TIP
本文主要是介绍 Yarn-集群搭建案例 。
# Yarn-集群搭建案例(一)
# 一、基础环境
1.虚拟机 VMware 15.0
2.CentOS 6.5 Linux 系统
# 二、MapReduce的原理分析
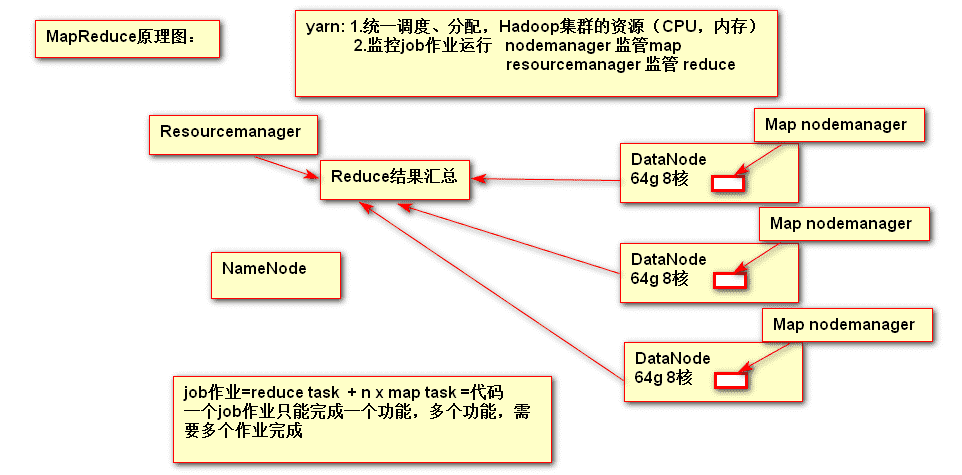
# 三、Yarn集群搭建
1.准备好三台虚拟机(这里我直接拷贝了Ha集群中一个作为主机,其余克隆)
2.修改基础配置:
1.删除每一台机器的Mac地址(CentOS 7 以上不需要)
rm -rf /erc/udev/rules.d/70-persistent-net.rules
2.修改etho网卡的ip地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
3.修改hostname
vi /etc/sysconfig/network
4.修改 hostmap
vi /etc/hosts ###记得添加其余俩台的ip与映射 然后scp 拷贝过去,省得再去修改其余俩台机器
3.修改Hadoop配置文件(由于是拷贝过来的,所以只修改部分就够了)
1.hadoop-env.sh 不做修改 ##jdk的目录早已配置好
2.core-site.xml 将入口改成主NameNode的hostname
1 <property>
2 <name>fs.default.name</name>
3 <value>hdfs://cmx031.ai179.com:8020</value>
4 </property>
5 <property>
6 <name>hadoop.tmp.dir</name>
7 <value>/opt/install/hadoop-2.5.2/data/tmp</value>
8 </property>
3.hdfs-site.xml #只要外部修改权限即可
1 <property>
2 <name>dfs.permissions.enabled</name>
3 <value>false</value>
4 </property>
4.yarn-site.xml #加上resourcenamenode的节点地址 ##注意这里的resource节点地址 最好不要与主NameNode节点相同
1 <property>
2 <name>yarn.nodemanager.aux-services</name>
3 <value>mapreduce_shuffle</value>
4 </property>
5 <property>
6 <name>yarn.resourcemanager.hostname</name>
7 <value>cmx032.ai179.com</value>
8 </property>
5.mapred-site.xml 不需要改变
6.slaves ##从节点的主机名 需要改成你对应的DataNode节点
4.然后先清除Hadoop_Home/data/tmp 目录下的所有文件,再将其余俩台机器的 /opt/install/hadoop (这是安装Hadoop的目录,可自己定义)删除,之后在第一台机器,
通过scp -r hadoop root@hostname:/opt/isntall 分别拷贝到其余俩台机器上。
5.然后在每一台机器上互相ssh 免密登录一下,打出yes,防之后启动hdfs服务主节点连接其他俩台机器连接不上
6.在主NameNode节点上进行格式化 :bin/hdfs namenode -format
7.开启hdfs服务:在Hadoop目录下:sbin/start-dfs.sh 开启服务 #通过jps检测相应的进程是否开启
8.在第二台机器上开启yarn集群服务(我在yarn-site.xml设置的yarn主节点):sbin/start-yarn.sh
9.各节点的进程开启无误后,在Windows上打开http://cmx032.ai179.com:8088 (opens new window) ,可以访问到MapReduce的主页面,打开http://cmx031.ai179.com:50070 (opens new window) ,可以访问到NameNode的主页面
代表集群搭建成功。
# 【----------------------------】
# Yarn-集群搭建案例(二)
# Yarn篇--搭建yarn集群
# 一、前述
有了上次hadoop集群的搭建,搭建yarn就简单多了。废话不多说,直接来
# 二、规划
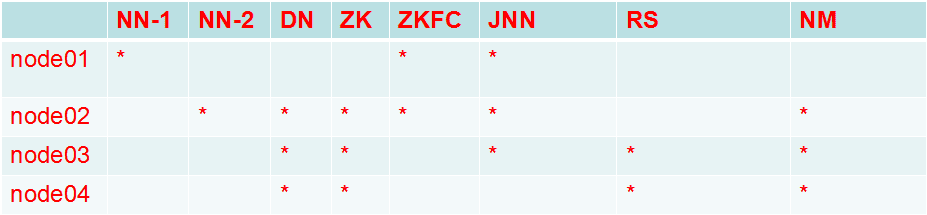
# 三。配置如下
yarn-site.xml配置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>//定义yarn的机制
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>//是否使用HA
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name//集群Id
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>//集群逻辑节点
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>//集群物理节点
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>//集群物理节点
<value>node04</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>//与zookeeper通信
<value>node02:2181,node03:2181,node04:2181</value>
</property>
mapred-site.xml配置
<property>
<name>mapreduce.framework.name</name>//使用yran
<value>yarn</value>
</property>
PS :slaves中既是datanode配置同时也是nodemanger的配置
# 四。配置免密
同样需要配置resourcemange到nodemanager的免密 和两个resourcemanger的免密
# 五。启动顺序
养成一个好习惯,先把集群停掉,然后再添加配置,(其实不停也行)
先在node01节点上手动先启动hdfs集群start-dfs.sh
node01然后再启动yarn集群 start-yarn.sh(Nodemanager也是由slaves文件管理)
然后再在node03和node04手动启动resourcemanger
yarn-daemon.sh start resourcemanager
# 六。验证

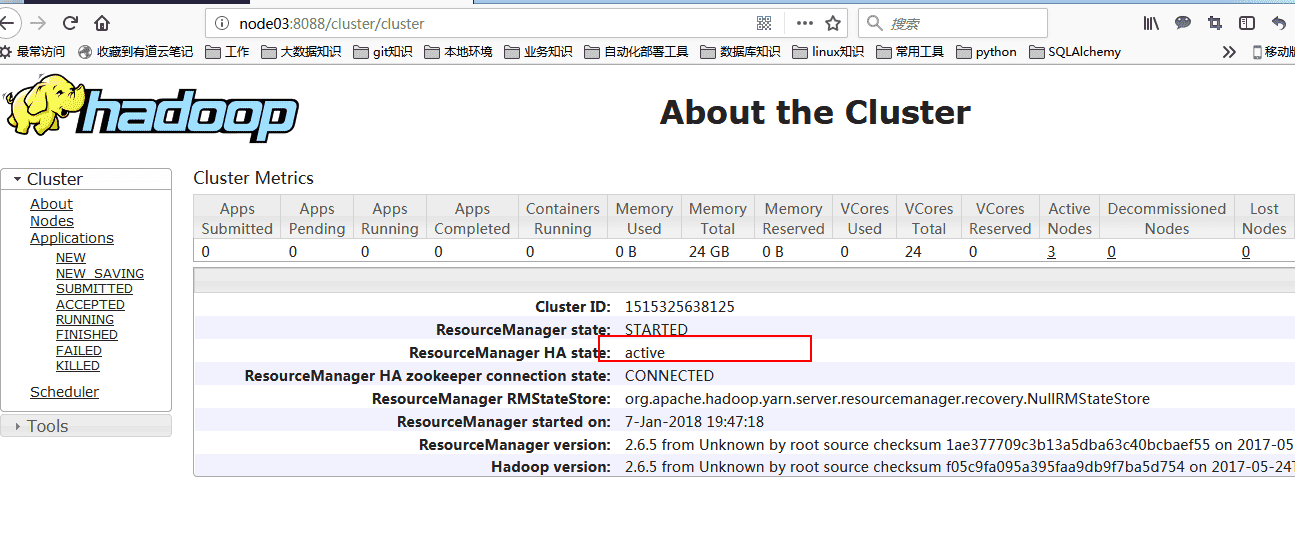
自此集群搭建成功!!!
# 参考文章
- https://www.cnblogs.com/cmxbky1314/p/12122030.html
- https://www.cnblogs.com/LHWorldBlog/p/8219453.html
- https://www.jianshu.com/p/076705abb50d










