TIP
本文主要是介绍 Tez-基础知识 。
# TEZ诞生背景
# 诞生原因
TEZ的诞生主要是为了解决MapReduce效率低下的问题。
# 采用的方法
传统的MR(包括Hive,Pig和直接编写MR程序)。假设有四个有依赖关系的MR作业(1个较为复杂的Hive SQL语句或者Pig脚本可能被翻译成4个有依赖关系的MR作业),运行过程如下:

采用tez运行过程如下:
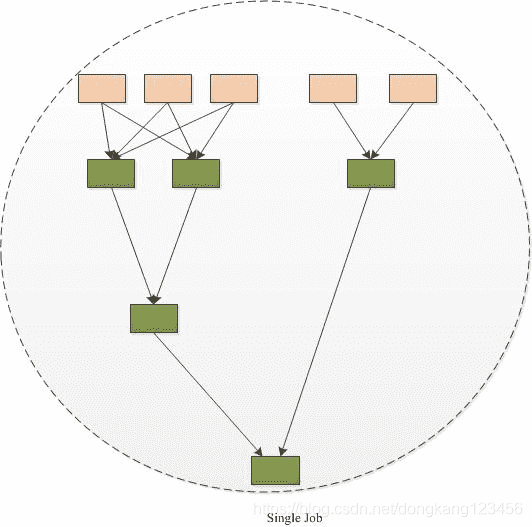
我们可以看到TEZ将4个job任务转换为1个作业,从而大大减少了读写HDFS的操作(MR程序需要将中间结果存储到HDFS中)。
# TEZ简介
TEZ将原有的Map和Reduce两个操作简化为一个概念-Vertex;并将原有的计算处理节点拆分成多个组成部分:Vertex Input、Vertex Output、Sorting、Shuffing和Metging。计算节点之间的数据通信被称为Edge,这些分解后的元操作可以任意灵活组合,产生新的操作,这个操作经过组装之后,形成一个大的ADG作业。
- Input:对输入数据源的抽象,它解析输入数据格式,并吐出一个个Key/value
- Output:对输出数据源的抽象,它将用户程序产生的Key/value写入文件系统
- Paritioner:对数据进行分片,类似于MR中的Partitioner
- Processor:对计算的抽象,它从一个Input中获取数据,经处理后,通过Output输出
- Task:对任务的抽象,每个Task由一个Input、Ouput和Processor组成
- Maser :管理各个Task的依赖关系,并按顺依赖关系执行他们
除了以上6种组件,Tez还提供了两种算子,分别是Sort(排序)和Shuffle(混洗),为了用户使用方便,它还提供了多种Input、Output、Task和Sort的实现。
# DAG编程模型
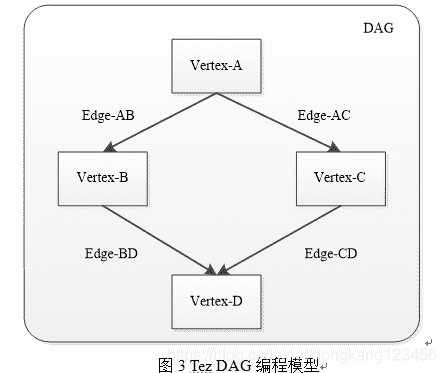
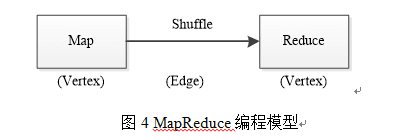
tez通过有向图模型组织应用程序中的Task,这些Task按照依赖关系可形成一个DAG,具体如图3所示,Tez采用图数据结构描述DAG组成,一个DAG由若干个顶点(Vertex)和连接这些顶点的边(Edge)组成,每个顶点对应一段作用在一个数据集上的处理逻辑,可同时启动多个任务,而边则定义了两个顶点之间的数据通信方式。如图4所示,MapReduce作业是一个非常简单的DAG,Map和Reduce相当于两个顶点,它们均可以同时启动多个任务处理数据,而Map和Reduce之间的Shuffle通信模型相当于连接两个顶点的边:
# Vertex
Vertex分为 MapVertex、ReduceVertex
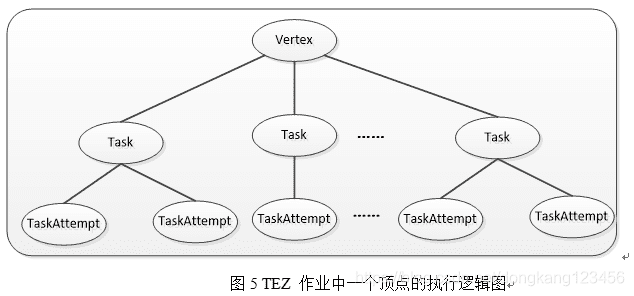
如下图所示,对于DAG中的一个顶点(Vertex),它由一定数目的任务(Task)组成,这些任务分别处理输入数据集中的一份数据,一旦所有任务运行完成,则意味着该顶点运行完成;对于任何一个任务,它可能对应多个运行实例TaskAttempt,比如任务刚开始运行时,会创建一个运行实例,如果该实例运行失败,则会再启动一个实例重新运行;如果该实例运行速度过慢,则会为它再启动一个相同实例同时处理一份数据,这些机制均借鉴了MRv1中的设计。
# Reduce Task 并行度分配方法
ShuffleVertexManager对于在mapreduce的shuffle传输层定义的基于hash分区的语法很清楚。对一个确定的顶点,tez定义了一个VertexManager事件用户将任何用户定义发送给该顶点的VertexManager。分区任务(即Map tasks)使用该事件将诸如输出分区的大小等统计信息发送给reduce顶点的ShuffleVertexManager。该manager收到这些事件之后会尝试根据其中的抽样统计信息估算出所有map tasks的最终输出的统计信息。理想的情况将是重新分区,然后决定运行时恰当的reduce个数。顶点控制者会在确定了reduce并行度之后,取消多余的tasks并像以前一样正常启动tasks。
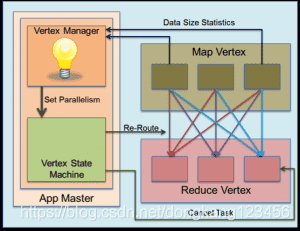
# MapReduce和Tez对比
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)"。
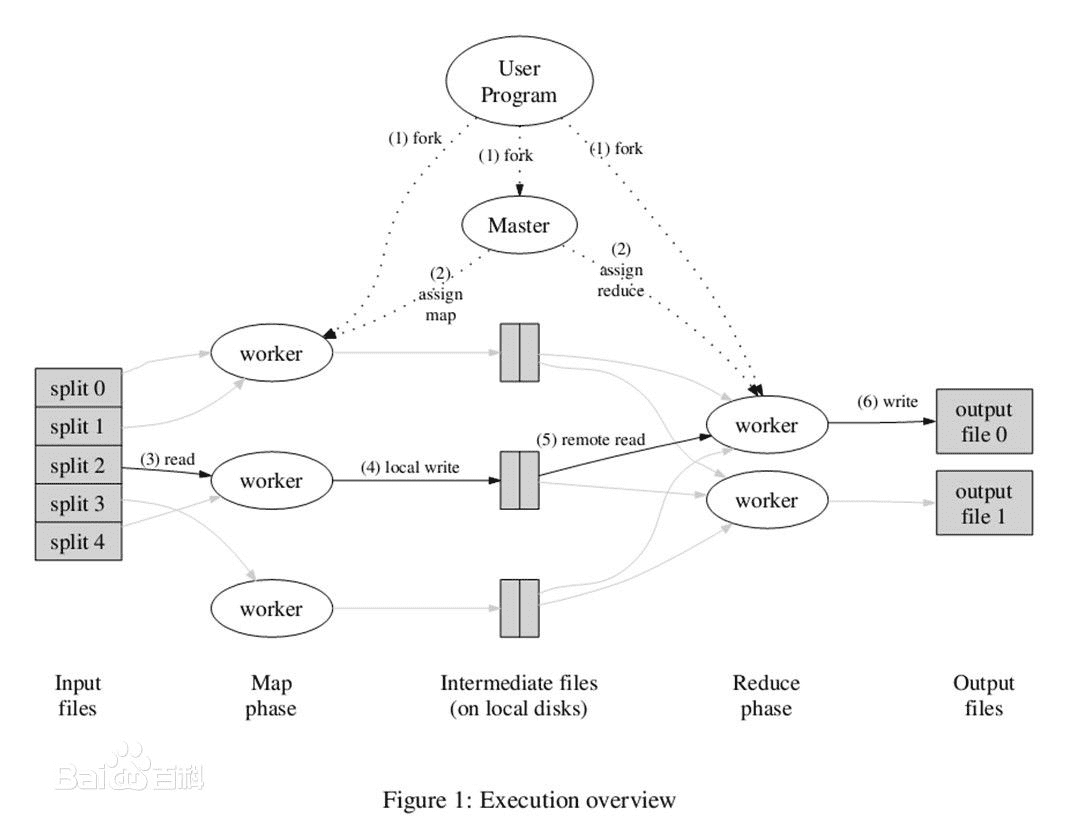
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。总结起来,Tez有以下特点:
- (1)Apache二级开源项目(源代码今天发布的)
- (2)运行在YARN之上
- (3) 适用于DAG(有向图)应用(同Impala、Dremel和Drill一样,可用于替换Hive/Pig等)
对比举例:
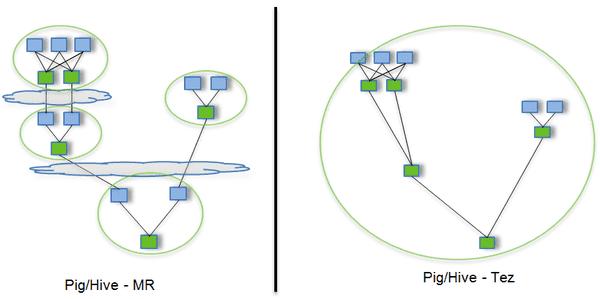
传统的MR(包括Hive,Pig和直接编写MR程序)。假设有四个有依赖关系的MR作业(1个较为复杂的Hive SQL语句或者Pig脚本可能被翻译成4个有依赖关系的MR作业)或者用Oozie描述的4个有依赖关系的作业,运行过程如下(其中,绿色是Reduce Task,需要写HDFS):
云状表示写屏蔽(write barrier,一种内核机制,持久写)
# Tez的核心优势:
Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能
Hadoop是基础,其中的HDFS提供文件存储,Yarn进行资源管理。在这上面可以运行MapReduce、Spark、Tez等计算框架。
MapReduce:是一种离线计算框架,将一个算法抽象成Map和Reduce两个阶段进行处理,非常适合数据密集型计算。
# Tez 和 Spark、Storm简要介绍
Spark:Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Storm:MapReduce也不适合进行流式计算、实时分析,比如广告点击计算等。Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域
Tez: 是基于Hadoop Yarn之上的DAG(有向无环图,Directed Acyclic Graph)计算框架。它把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。同时合理组合其子过程,也可以减少任务的运行时间
# wordCount
下面我们通过TEZ实现wordcount功能:
package com.tez.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.mapred.lib.HashPartitioner;
import org.apache.hadoop.util.ToolRunner;
import org.apache.tez.client.TezClient;
import org.apache.tez.dag.api.*;
import org.apache.tez.examples.TezExampleBase;
import org.apache.tez.mapreduce.input.MRInput;
import org.apache.tez.mapreduce.output.MROutput;
import org.apache.tez.mapreduce.processor.SimpleMRProcessor;
import org.apache.tez.runtime.api.ProcessorContext;
import org.apache.tez.runtime.library.api.KeyValueReader;
import org.apache.tez.runtime.library.api.KeyValueWriter;
import org.apache.tez.runtime.library.api.KeyValuesReader;
import org.apache.tez.runtime.library.conf.OrderedPartitionedKVEdgeConfig;
import org.apache.tez.runtime.library.processor.SimpleProcessor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @date 20200610
* @des Tez 版本的wordCount
*
* */
public class WordCount extends TezExampleBase {
static String INPUT = "Input";
static String OUTPUT = "Output";
static String TOKENIZER = "Tokenizer";
static String SUMMATION = "Summation";
private static final Logger LOG = LoggerFactory.getLogger(WordCount.class);
/**
* 第一个顶点-实现类似Map的逻辑
*
* */
public static class TokenProcessor extends SimpleProcessor {
//输出key,类似MapReduce的输出key
Text word = new Text();
//输出value 类似MapReduce的输出value
IntWritable one = new IntWritable(1);
public TokenProcessor(ProcessorContext context) {
super(context);
}
@Override
public void run() throws Exception {
//读取输入的数据,其中INPUT指代输入任务在DAG图中的名称
KeyValueReader kvReader = (KeyValueReader) getInputs().get(INPUT).getReader();
//输出当前处理后的数据,其中变量SUMMATION指代数据输出的下一环节的名称
KeyValueWriter kvWriter = (KeyValueWriter) getOutputs().get(SUMMATION).getWriter();
while (kvReader.next()) {
//读取每一行的数据,按照空格进行切分成一个个单词
StringTokenizer itr = new StringTokenizer(kvReader.getCurrentValue().toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
kvWriter.write(word, one);
}
}
}
}
/**
* 顶点2-实现类的Reduce逻辑
* */
public static class SumProcessor extends SimpleMRProcessor {
public SumProcessor(ProcessorContext context) {
super(context);
}
@Override
public void run() throws Exception {
//读取顶点1的数据,其中TOKENIZER指代顶点1在DAG图中的名称
KeyValuesReader kvReader = (KeyValuesReader) getInputs().get(TOKENIZER).getReader();
//将当前数据处理后输出,其中变量OUTPUT指定输出任务在DAG图中的名称
KeyValueWriter kvWriter = (KeyValueWriter) getOutputs().get(OUTPUT).getWriter();
while (kvReader.next()) {
Text word = (Text) kvReader.getCurrentKey();
int sum = 0;
for (Object value : kvReader.getCurrentValues()) {
sum += ((IntWritable) value).get();
}
kvWriter.write(word, new IntWritable(sum));
}
}
}
/**
*
* 构建DAG图并提交任务
* */
private DAG createDAG(TezConfiguration tezConf, String inputPath, String outputPath,
int numPartitions) throws IOException {
//构造一个输入源dataSource,用于指定输入路径(inputPath)
//以Text方式读取数据
DataSourceDescriptor dataSource = MRInput.createConfigBuilder(
new Configuration(tezConf),
TextInputFormat.class, inputPath)
.groupSplits(!isDisableSplitGrouping())
.generateSplitsInAM(!isGenerateSplitInClient()).build();
//构造一个输出,用于将数据以Text方式,将数据写入到输出路径下
DataSinkDescriptor dataSink = MROutput.createConfigBuilder(new Configuration(tezConf),
TextOutputFormat.class, outputPath).build();
/**
* 构造第一个顶点
* 顶点名为TOKENIZER
* 这个顶点的数据源来自dataSource
* 同时为这个输入起名INPUT
* */
Vertex tokenizerVertex = Vertex.create(TOKENIZER, ProcessorDescriptor.create(
TokenProcessor.class.getName())).addDataSource(INPUT, dataSource);
/**
* 构造第二个顶点
* vertex 名为SUMMATION,
* 同时为这个输出起名OUTPUT
*
* */
Vertex summationVertex = Vertex.create(SUMMATION,
ProcessorDescriptor.create(SumProcessor.class.getName()), numPartitions)
.addDataSink(OUTPUT, dataSink);
/**
* 构造上面两个顶点连接的边
* 制定数据输出是 <Text,IntWritable> 键值对的形式
* 声明了从源到目标顶点的分区器是采用HashPartitioner
*
* */
OrderedPartitionedKVEdgeConfig edgeConf = OrderedPartitionedKVEdgeConfig
.newBuilder(Text.class.getName(), IntWritable.class.getName(),
HashPartitioner.class.getName())
.setFromConfiguration(tezConf)
.build();
//创建一个名为WordCount的DAG
DAG dag = DAG.create("WordCount");
dag.addVertex(tokenizerVertex)
.addVertex(summationVertex)
.addEdge(
Edge.create(tokenizerVertex, summationVertex, edgeConf.createDefaultEdgeProperty()));
return dag;
}
@Override
protected void printUsage() {
}
@Override
protected int validateArgs(String[] strings) {
return 0;
}
@Override
protected int runJob(String[] args, TezConfiguration tezConf,
TezClient tezClient) throws Exception {
DAG dag = createDAG(tezConf, args[0], args[1],
args.length == 3 ? Integer.parseInt(args[2]) : 1);
LOG.info("Running WordCount");
return runDag(dag, isCountersLog(), LOG);
}
public static void main(String[] args) throws Exception {
/**
*
* 输入参数设置
*
* F://file//word.txt F://file//word_tez.txt 3
* */
int res = ToolRunner.run(new Configuration(), new WordCount(), args);
System.exit(res);
}
}
# Tez参数
在和hive结合使用的过程中,我们会经常使用下面的一些常用参数:
1) set hive.execution.engine=tez; hive使用tez执行引擎;
2) set tez.grouping.min-size=256000000; //默认5010241024 set tez.grouping.max-size=3221225472; //默认 102410241024 Map 任务分组分片的最大和最小值,最大最小都会影响性能;
3) set tez.queue.name=root.odms; 在yarn集群中的队列名称;
4) set tez.job.name=job_dm_icsm_ts_area_manage_bdp; tez引擎设置任务名称;
5) set mapred.job.name=job_dm_icsm_ts_area_manage_bdp; mapReduce引擎设置任务名称
6) set hive.tez.auto.reducer.parallelism=true; //默认为false 打开Tez的 auto reducer 并行特性。启用后,配置单元仍将估计数据大小并设置并行度估计。Tez将采样源顶点的输出大小,并在运行时根据需要调整估计值。
7) set mapred.reduce.tasks =1550; 设置reduce的个数;
# 参考文章
- https://blog.csdn.net/dongkang123456/article/details/106670829/
- https://www.cnblogs.com/linn/p/5325147.html










