Storm-集群应用案例
更新时间
浏览
TIP
本文主要是介绍 Storm-集群应用案例 。
# Storm集群部署及单词统计案例
# 1、集群部署的基本流程
集群部署的流程:下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
注意:所有的集群上都需要配置hosts:vi /etc/hosts
# 2、集群部署的基础环境准备
1、storm安装依赖Python,所以在安装前请确保Python已经安装成功了\
[root@hadoop1 software]# wget http://www.python.org/ftp/python/2.6.6/Python-2.6.6.tar.bz2
[root@hadoop1 software]# tar -jxvf Python-2.6.6.tar.bz2
[root@hadoop1 software]# cd Python-2.6.6
[root@hadoop1 software]# ./configure
[root@hadoop1 software]# make
[root@hadoop1 software]# make install
测试Python,检查是否已经安装好了
[root@hadoop1 Python-2.6.6]# python -V
2、在安装前要保证shizhan2,shizhan3,shizhan5之间能够互相两两之间ssh免登陆 3、安装好JDK 4、安转好Zookeeper集群(shizhan2、shizhan3、shizhan5)\
# 3、Storm集群部署:
# 3.1.下载安装包:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-1.1.2/apache-storm-1.1.2.tar.gz
# 3.2.解压安装包:
[root@shizhan2 software]# mkdir -p /export/servers/
[root@shizhan2 software]# tar -xzvf apache-storm-1.1.2.tar.gz -C /export/servers/
[root@shizhan2 software]# cd /export/servers/
[root@shizhan2 servers]# ln -s apache-storm-1.1.2 storm
# 3.3.修改配置文件:
配置文件:vi /export/servers/apache-storm-1.1.2/conf/storm.yaml
#指定strom使用的zk集群,如果Zookeeper集群使用的不是默认端口,那么还需要storm.zookeeper.port选项
storm.zookeeper.servers:
- "shizhan2"
- "shizhan3"
- "shizhan5"
#strom.local.dir : Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限。然后在storm.yaml中配置目录,如:
storm.local.dir: "/home/software/stormInstallPath/workdir"
#指定storm集群中的nimbus节点所在的服务器
nimbus.host: "shizhan2"
#指定nimbus启动JVM最大可用内存大小
nimbus.childopts: "-Xmx1024m"
#指定supervisor启动JVM最大可用内存大小
supervisor.childopts: "-Xmx1024m"
#指定supervisor节点上,每个worker启动JVM最大可用内存大小
worker.childopts: "-Xmx768m"
#指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。
ui.childopts: "-Xmx768m"
#指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker,对于Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,该配置选线即用于接收消息,该配置选项用于定义哪些端口是可以被worker使用的。默认情况下每个节点下可以运行4个workers,分别在6700,6701,6702,6703端口,如:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
# 3.4.分发安装包:
scp -r /export/servers shizhan3:/export/
scp -r /export/servers shizhan5:/export/
cd /export/servers/
ln -s apache-storm-0.9.5 storm
配置strom的环境变量(shizhan2,shizhan3,shizhan5这几台服务器都要相应的修改)
[root@hadoop1 software]# vim /etc/profile
#set storm env
export STORM_HOME=/export/servers/apache-storm-1.1.2
export PATH=$PATH:$STORM_HOME/bin
[root@hadoop1 software]# source /etc/profile
# 3.5启动集群:
先启动zookeeper集群,再启动Storm集群
在nimbus.host所属的机器上启动 nimbus服务
cd /export/servers/storm/bin/
nohup ./storm nimbus &
在nimbus.host所属的机器上启动ui服务
cd /export/servers/storm/bin/
nohup ./storm ui &
在其它个点击上启动supervisor服务
cd /export/servers/storm/bin/
nohup ./storm supervisor &
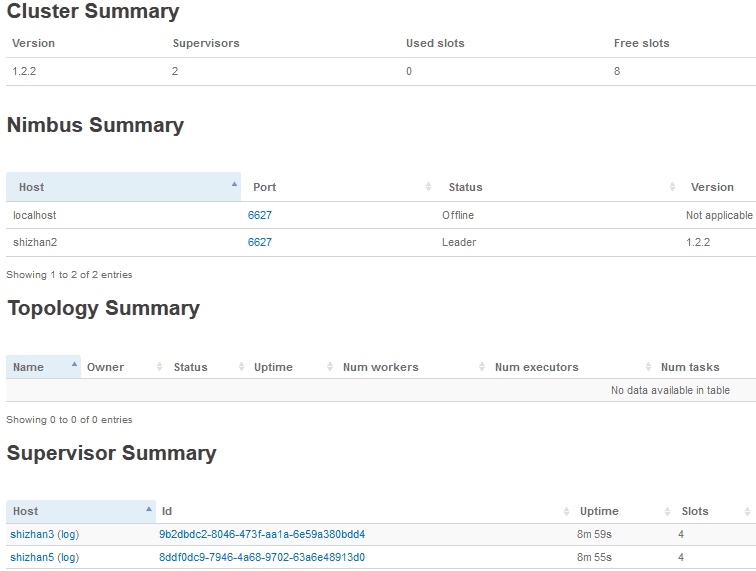
# 3.6 查看集群 Storm UI:
http://shizhan2:8080,即可查看storm UI界面
# 4、Storm集群的进程及日志熟悉
部署成功后,启动集群:
4.1 查看nimbus的日志信息(在shizhan2的nimbus服务器上)
cd /export/servers/apache-storm-1.2.2/logs/
tail -100f /export/servers/apache-storm-1.2.2/logs/nimbus.log
4.2 查看UI的运行日志信息(一般和nimbus在同一服务器上)
cd /export/servers/apache-storm-1.2.2/logs/
tail -100f /export/servers/apache-storm-1.2.2/logs/ui.log
4.3 查看supervisor运行日志信息(在superviso服务器上)
cd /export/servers/apache-storm-1.2.2/logs/
tail -100f /export/servers/apache-storm-1.2.2/logs/supervisor.log
4.4 查看supervisor上worker的运行日志信息(在superviso服务器上)
cd /export/servers/apache-storm-1.2.2/logs/
tail -100f /export/servers/apache-storm-1.2.2/logs/worker6702.log
<img class= "zoom-custom-imgs" :src="$withBase('/assets/img/dp/storm/wordcase-2.png')" alt="wxmp">
(该worker正在运行wordcount程序)
# 5、Storm集群的常用操作命令
Storm命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑
提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
杀死任务命令格式:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte topology-name
我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。
销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成
当前的数据流。
启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后
在相应超时时间之后重分配工人,并重启拓扑。
# 6、Storm源码下载及目录熟悉(很重要):
1.在Storm官方网站上寻找源码地址: http://storm.apache.org/downloads.html
2.点击Source Code
3.进入GitHub后,拷贝Storm源码地址,点击Clone or Download,进行下载,也可使用Subversion客户端下载
4.目录分析

扩展包中的三个项目,使storm能与hbase、hdfs、kafka交互
# 7、Storm单词计数案例:
集群部署成功时,测试自带wordcount程序案例,熟悉任务提交部署流程
# 参考文章
- https://www.cnblogs.com/yaboya/p/9389121.html










