TIP
本文主要是介绍 TensorFlow-基础入门介绍 。
# TensorFlow 简介
- TensorFlow 是一个开放源代码软件库,用于进行高性能数值计算。借助其灵活的架构,用户可以轻松地将计算工作部署到多种平台(CPU、GPU、TPU)和设备(桌面设备、服务器集群、移动设备、边缘设备等)。
- TensorFlow 是一个用于研究和生产的开放源代码机器学习库。TensorFlow 提供了各种 API,可供初学者和专家在桌面、移动、网络和云端环境下进行开发。
- TensorFlow是采用数据流图(data flow graphs)来计算,所以首先我们得创建一个数据流流图,然后再将我们的数据(数据以张量(tensor)的形式存在)放在数据流图中计算. 节点(Nodes)在图中表示数学操作,图中的边(edges)则表示在节点间相互联系的多维数据数组, 即张量(tensor)。训练模型时tensor会不断的从数据流图中的一个节点flow到另一节点, 这就是TensorFlow名字的由来。 张量(Tensor):张量有多种. 零阶张量为 纯量或标量 (scalar) 也就是一个数值. 比如 [1],一阶张量为 向量 (vector), 比如 一维的 [1, 2, 3],二阶张量为 矩阵 (matrix), 比如 二维的 [[1, 2, 3],[4, 5, 6],[7, 8, 9]],以此类推, 还有 三阶 三维的 … 张量从流图的一端流动到另一端的计算过程。它生动形象地描述了复杂数据结构在人工神经网中的流动、传输、分析和处理模式。
在机器学习中,数值通常由4种类型构成: (1)标量(scalar):即一个数值,它是计算的最小单元,如“1”或“3.2”等。 (2)向量(vector):由一些标量构成的一维数组,如[1, 3.2, 4.6]等。 (3)矩阵(matrix):是由标量构成的二维数组。 (4)张量(tensor):由多维(通常)数组构成的数据集合,可理解为高维矩阵。
Tensorflow中的数据流图(from官网)
- 使用TensorFlow的优点主要表现在如下几个方面:
(1)TensorFlow有一个非常直观的构架,顾名思义,它有一个“张量流”。用户可以很容易地看到张量流动的每一个部分(借助TensorBoard,在后面的章节会有所提及)。
(2)TensorFlow可轻松地在CPU/GPU上部署,进行分布式计算。
(3)TensorFlow跨平台性高,灵活性强。TensorFlow不但可以在Linux、Mac和Windows系统下运行,甚至还可以在移动终端下工作。
当然,TensorFlow也有不足之处,主要表现在它的代码比较底层,需要用户编写大量的代码,而且很多相似的功能,用户还不得不“重造轮子”。但“瑕不掩瑜”,TensorFlow还是以雄厚技术积淀、稳定的性能,一骑红尘,“笑傲”于众多深度学习框架之巅。
# TensorFlow北大公开课:
TensorFlow北大公开课 https://www.icourse163.org/course/PKU-1002536002?tid=1002700003
TensorFlow北大公开课 (opens new window)
# 课程概述
课程会以投影的形式,帮你梳理tensorflow的用法,希望你用纸质笔记本记录下每个打着对勾的知识点;会用录屏的形式,带你编写代码,实现实际应用,希望你用电脑复现课程的案例。每次课后,助教会分享他的tensorflow笔记和源代码,帮你查漏补缺。
授课目标
学会使用Python语言搭建人工神经网络,实现图像分类。
# 课程大纲
第一讲 带着大家梳理人工智能领域的基本概念:比如什么是人工智能、什么机器学习、什么是深度学习,他们的发展历史是什么,能用他们做什么。课后,助教会带领大家安装Ubuntu系统、Python解释器 和 Tensorflow环境,把同学们的电脑进行改造,让它变得更专业。
第二讲 串讲python语法:课程将帮同学们在最短的时间内把python语法织成网,为后续课程扫清代码关;
第三讲 讲解Tensorflow的关键词,搭建神经网络:这节课会介绍张量、计算图、会话等概念,并用Python搭建你的第一个神经网络,总结出神经网络搭建的八股。
第四讲 讲解神经网络的优化:包括损失函数、学习率、滑动平均和正则化。
第五讲 讲解全连接网络:使用MNIST数据集,搭建全连接网络实现手写数字的识别。包括前向传播、反向传播、识别准确率输出和反向传播断点续训。
第六讲 讲解全连接网络应用:更改上一讲全连接网络的代码,现场手写一个数字,输出这个数字的值。
第七讲 讲解卷积神经网络:使用MNIST数据集,搭建卷积神经网络实现前向传播、反向传播、识别准确率输出和反向传播断点续训。
第八讲 讲解卷积神经网络应用:复现ImageNet数据集训练好的模型,实现特定图片的识别。
# 证书要求
满分100分,达到60分为合格,达到90分以上为优秀。
期中项目60分:编写Python代码,实现输入手写数字图片,输出预测的数值。识别准确率达到90%为合格:课程给出十张手写数字图片,每正确识别一张得6分。
期末项目40分:编写Python代码,复现卷积神经网络,输入一张图片,识别出图片的内容。识别准确率达90%为合格:课程给出十张图片,每正确识别一张得4分。
# 参考资料
《Tensorflow:实战Google深度学习框架》 郑泽宇,顾思宇 著,电子工业出版社
《深度学习》赵申剑,黎彧君,符天凡,李凯 译,人民邮电出版社
# 【----------------------------】
# tensorflow的定义
- tensorflow是一个采用数据流图,用于数值计算的开源的软件库。本质上可以认为是一个数据库,tensorflow可以作为
- Tensor(张量)意味着N维数组,Flow(流)意味
# tensorflow 网站
- 中文:https://tensorflow.google.cn/
- 英文:https://tensorflow.org/
- github:https://github.com/tensorflow/tensorflow
# tensorflow的特性
- 高度灵活性:只要能将计算表示成为一个数据流图,那就可以使用tensorflow
- 可移植性:支持CPU和GPU,可以在台式机、服务器、手机端运算。现在只支持英伟达的GPU
- 求微分:Tensorflow内部实现了自动对于各种给定目标函数求导的方式
- 支持多种语言:python、c、java、swift、go等
- 性能高度优化
# tensorflow playground
学习网站:https://playground.tensorflow.org (opens new window)
# tensorflow的基本概念
- 图:描述了计算过程,Tensorflow用图来表示计算过程
- 张量:Tensorflow 使用tensor表示数据,每一个tensor是一个多维化的数组
- 操作:图中的节点为op,一个op获得/输入0个或者多个Tensor,执行并计算,产生0个或多个Tensor
- 会话:session tensorflow的运行需要再绘话里面运行
# tensorflow写代码流程
- 定义变量占位符
- 根据数学原理写方程
- 定义损失函数cost
- 定义优化梯度下降 GradientDescentOptimizer
- session 进行训练,for循环
- 保存saver
# 【----------------------------】
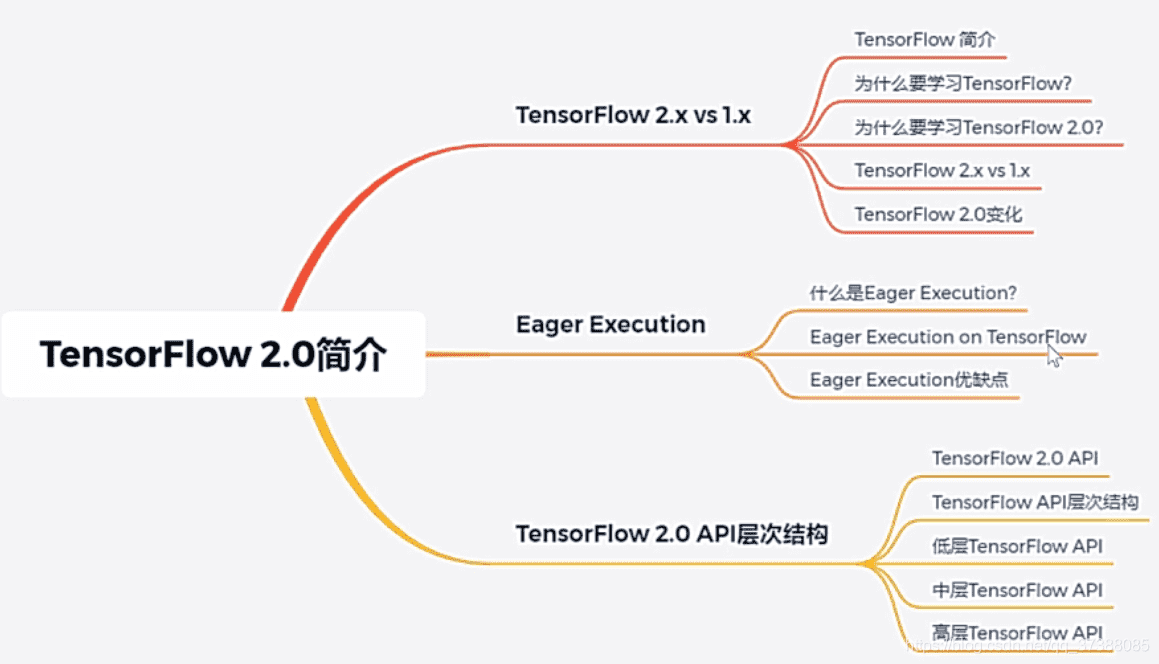
# TensorFlow 2.0简介
# 知识树
# 1、TensorFlow 2.x vs 1.x
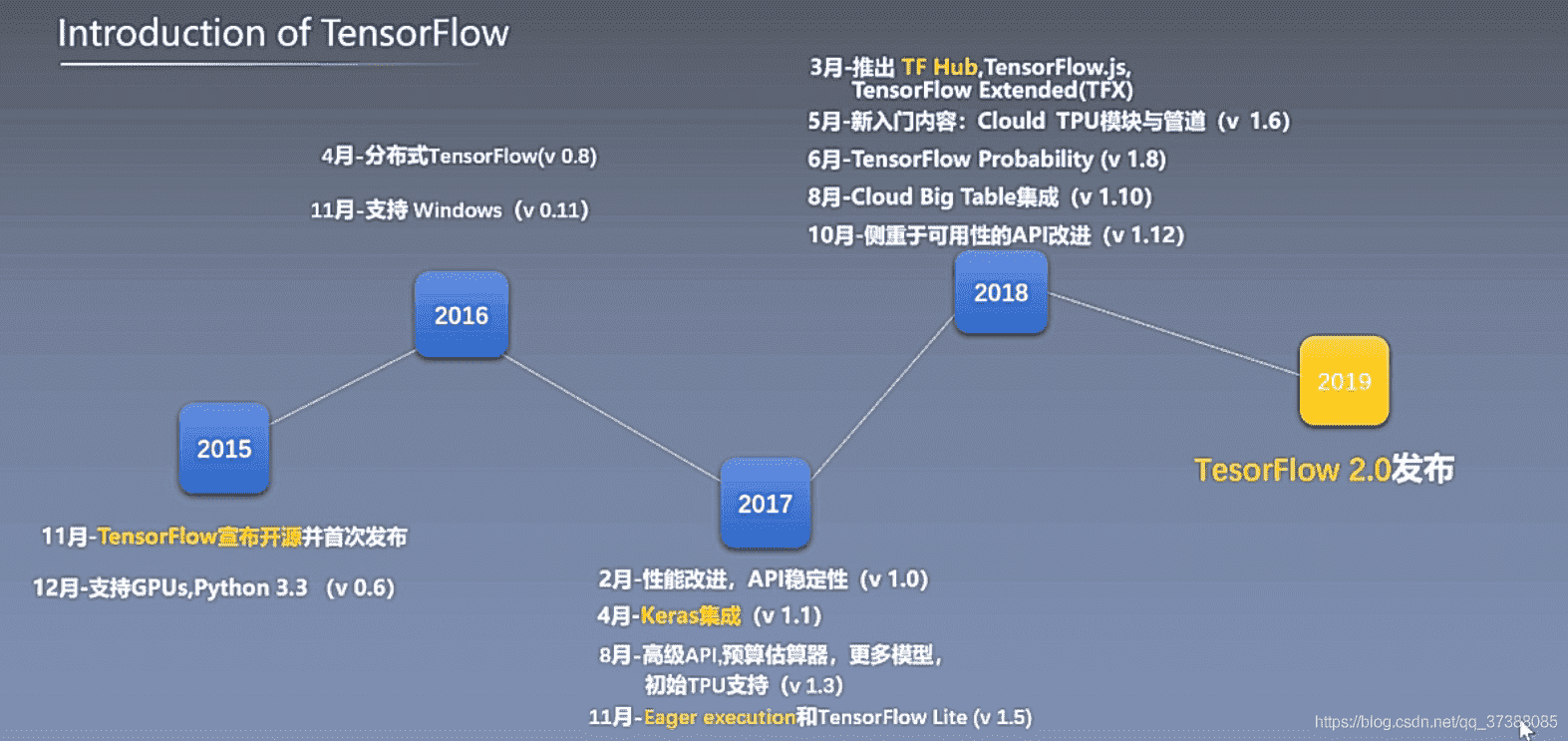
# 1.1 TensorFlow发展历程
# 1.2 为什么要学习TensorFlow
- 开源生态成熟;
- 完整的部署流程;
- 产品化方案;
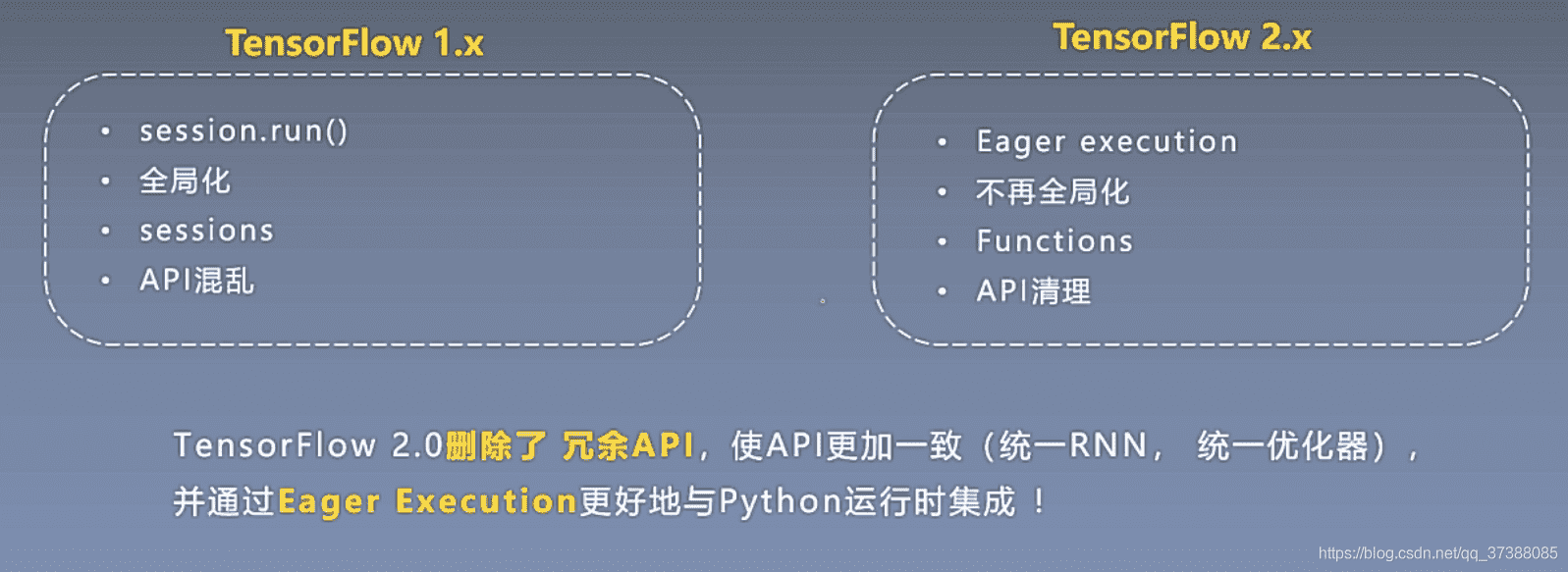
TensorFlow 1.X有哪些问题?
- 文档和接口混乱;
- 默认占用所有GPU的所有内存;
- 使用繁琐;
- 调试困难等;
# 1.3 TensorFlow 2.x vs 1.x

# 1.4 TensorFlow 2.0 变化
TensorFlow 2.0 推荐使用tf.keras、tf.data等高级库;
- 用Eager模式搭建原型;
- 用tf.data处理数据;
- 用tf.feature_column提取特征;
- 用tf.keras搭建模型;
- 用tf.saved_model打包模型;
# 2、Eager Execution
Eager模式就是类似于Python这样的命令式编程,写好程序之后,不需要编译,就可以直接运行,而且非常直观;
而之前的Session静态图模式则类似于C/C++的声明式编程,写好程序之后要先编译,然后才能运行;
Eager模式是在TF1.4版本之后引入的,在TF2.x的版本会把eager模式变为默认执行模式;
好处:
- 不需要编写完整的静态图;
- 调试不需要打开会话(Session);
- Python上调用它进行计算可以直接得出结果;
- TensorFlow 2.x的入门会简单得多;
# 2.1 Eager Execution优缺点
优点:
- eager模式提供了更直观的接口,可以像写Python代码一样写模型;
- 更方便调试;
- 自然的控制流程,像编写Python程序一样;
缺点:
- 通过graph构造的模型在分布式训练、性能优化以及线上部署上有优势;
推荐使用@tf.function(而非1.x中的tf.Session)实现Graph Execution,从而将模型转换为易于部署且高性能的TensorFlow图模型;
举个例子:
import tensorflow as tf
@tf.function
def simple_nn_layer(x, y):
return tf.nn.relu(tf.matmul(x, y))
x = tf.random.uniform((3,3))
y = tf.random.uniform((3,3))
simple_nn_layer(x,y)
# 3、TensorFlow API
TensorFlow API一共可以分为三个层次,即低阶API、中阶API、高阶API:
- 第一层为Python实现的操作符,主要包括各种张量操作算子、计算图、自动微分;
- 第二层为Python实现的模型组件,对低级API进行了函数封装,主要包括各种模型层,损失函数,优化器,数据管道,特征列等等;
- 第三层为Python实现的模型成品,一般为按照OOP方式封装的高级API,主要为tf.keras.models提供的模型的类接口;
# 3.1 低层TensorFlow API

举个例子,看看各种API的具体使用:
import tensorflow as tf
a = tf.constant([[1,2],[3,4]])
b = tf.constant([[5,6],[7,8]])
## 标量计算
a+b tf.math.add(a,b)
a-b tf.math.subtract(a,b)
a*b tf.math.multiply(a,b)
a/b tf.math.divide(a,b)
## 向量计算
a = tf.range(1,100)
tf.print(tf.reduce_sum(a))
tf.print(tf.reduce_mean(a))
tf.print(tf.reduce_max(a))
tf.print(tf.reduce_min(a))
tf.print(tf.reduce_prod(a))
# 3.2 中层TensorFlow API

举个例子,如下所示:
a = tf.random.uniform(shape=(10,5), minval=0, maxval=10) ## 矩阵
tf.nn.softmax(a) ## softmax操作
a = tf.random.uniform(shape(10,5), minval=-0.5, maxval=-0.5) ## 矩阵
b = tf.keras.layers.Dense(10)(a) ## 全连接层
b = tf.nn.softmax(b) ## softmax操作
a = tf.random.uniform(shape=(10,100,50), minval=-0.5, maxval=-0.5) ## 矩阵
b = tf.keras.LSTM(100)(a) ## LSTM层
b = tf.keras.layers.Dense(b) ## 全连接层
b = tf.nn.softmax(b) ## softmax操作
# 3.3 高层TensorFlow API
tensorflow.keras.models 建模方式有三种:
- Sequential办法;
- 函数式API方法;
- Model子类化自定义模型
如何构建模型将会在后面详细介绍,下面我们举个例子:
import tensorflow as tf
## 随机初始化输入X和输出y
X = tf.random.uniform(shape=(10,100,50),minval=-0.5,maxval=0.5)
y = tf.random.categorical(tf.random.uniform(shape=(10.3),minval=-0.5,maxval=-0.5),2)
## 构造模型
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.LSTM(100,input_shape=(100,50)))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Dense(2,activation='softmax'))
model.compilc(optimizer='adam',loss='categorical crossentropy',metrics=['accuracy'])
model.summary()
model.fit(X,y)
# 3.4 TensorFlow API 总结
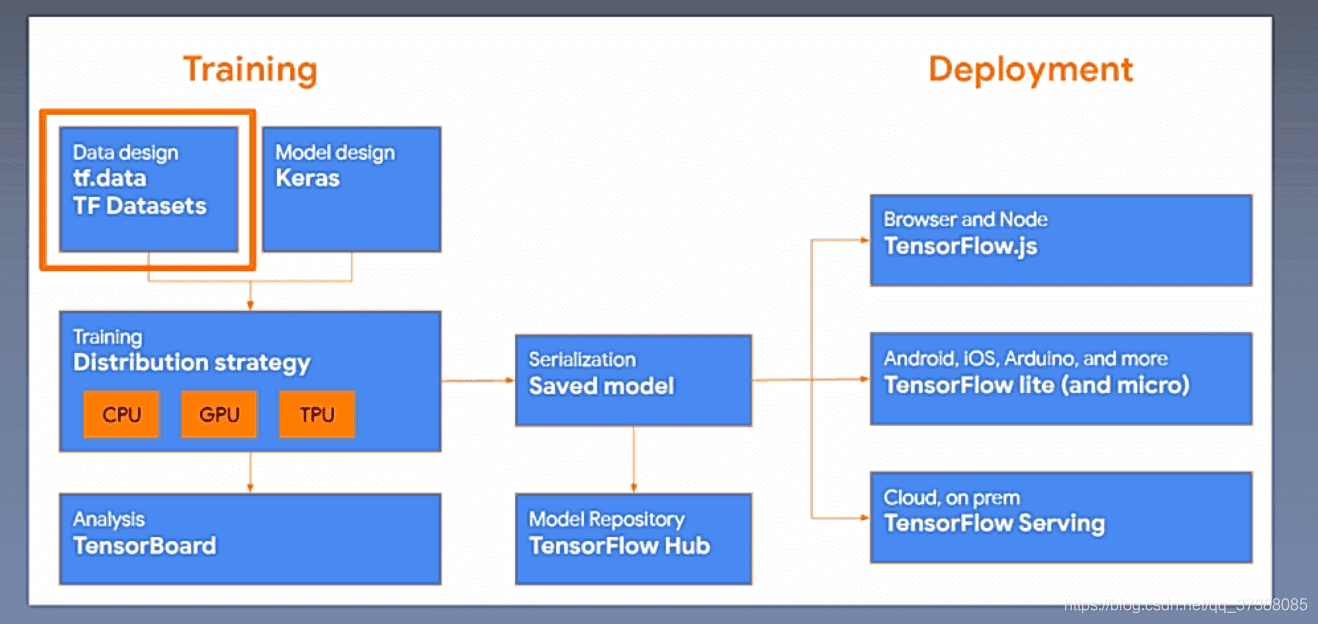
上图中的tf.data用于构造数据,Keras用于构造模型的层,接着用CPU、GPU、TPU进行加速训练,对训练结果使用TensorBoard进行可视化,可以对模型进行保存(Saved model),TensorFlow HUb的作用是模型复用,Deployment的作用是模型部署。
# 4、资料来源
深度之眼课程——《TensorFlow》
# 【----------------------------】
# TensorFlow基础总结
# 1.基础概念
- Tensor:类型化的多维数组,图的边;Tensor所引用的并不持有具体的值,而是保持一个计算过程,可以使用session.run()或者t.eval()对tensor的值进行计算。
- Operation:执行计算的单元,图的节点;这里大概可总结为Tensor创建,Tensor转换,逻辑判断,数学运算,聚合运算,序列比较与索引提取等。
- Graph:一张有边与点的图,其表示了需要进行计算的任务;
- Session:称之为会话的上下文,用于执行图。用户管理CPU和GPU和网络连接。
# 2.Tensor
# 2.1 数据结构
- rank:数据的维度,其与线性代数中的rank不是一个概念。
- shape:tensor每个维度数据的个数;下图表示了rank,shape的关系。
| Rank | Shape | Dimension number | Example |
|---|---|---|---|
| 0 | [] | 0-D | A 0-D tensor. A scalar. |
| 1 | [D0] | 1-D | A 1-D tensor with shape [5]. |
| 2 | [D0, D1] | 2-D | A 2-D tensor with shape [3, 4]. |
| 3 | [D0, D1, D2] | 3-D | A 3-D tensor with shape [1, 4, 3]. |
| n | [D0, D1, ... Dn-1] | n-D | A tensor with shape [D0, D1, ... Dn-1]. |
- data type:单个数据的类型。下图表示了所有的types。
| Data type | Python type | Description |
|---|---|---|
| DT_FLOAT | tf.float32 | 32 bits floating point. |
| DT_DOUBLE | tf.float64 | 64 bits floating point. |
| DT_INT8 | tf.int8 | 8 bits signed integer. |
| DT_INT16 | tf.int16 | 16 bits signed integer. |
| DT_INT32 | tf.int32 | 32 bits signed integer. |
| DT_INT64 | tf.int64 | 64 bits signed integer. |
| DT_UINT8 | tf.uint8 | 8 bits unsigned integer. |
| DT_UINT16 | tf.uint16 | 16 bits unsigned integer. |
| DT_STRING | tf.string | Variable length byte arrays. Each element of a Tensor is a byte array. |
| DT_BOOL | tf.bool | Boolean. |
| DT_COMPLEX64 | tf.complex64 | Complex number made of two 32 bits floating points: real and imaginary parts. |
| DT_COMPLEX128 | tf.complex128 | Complex number made of two 64 bits floating points: real and imaginary parts. |
| DT_QINT8 | tf.qint8 | 8 bits signed integer used in quantized Ops. |
| DT_QINT32 | tf.qint32 | 32 bits signed integer used in quantized Ops. |
| DT_QUINT8 | tf.quint8 | 8 bits unsigned integer used in quantized Ops. |
# 2.2 稀疏张量(SparseTensor)
用于处理高维稀疏数据,包含indices,values,dense_shape三个属性。 indices:形状为(N, ndims)的Tensor,N为非0元素个数,ndims表示张量阶数 values:形状为(N)的Tensor,保存indices中指定的非0元素的值 dense_shape:形状为(ndims)的Tensor,表示该稀疏张量对应稠密张量的形状
# 3.Operation
# 3.1 Tensor创建函数
| 用法 | 说明 |
|---|---|
| tf.zeros(shape, dtype=tf.float32, name=None) | 创建所有元素设置为零的张量 |
| tf.zeros_like(tensor, dtype=None, name=None) | 返回tensor与所有元素设置为零相同的类型和形状的张量 |
| tf.ones(shape, dtype=tf.float32, name=None) | 创建一个所有元素设置为1的张量。 |
| tf.ones_like(tensor, dtype=None, name=None) | 返回tensor与所有元素设置为1相同的类型和形状的张量 |
| tf.fill(dims, value, name=None) | 创建一个填充了标量值的张量 |
| tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) | 从截断的正态分布中输出随机值 |
| tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) | 从正态分布中输出随机值 |
| tf.random_uniform(shape, minval=0.0, maxval=1.0, dtype=tf.float32, seed=None, name=None) | 从均匀分布输出随机值 |
| tf.eye(num_rows, num_columns=None, batch_shape=None, dtype=tf.float32, name=None) | 构建一个单位矩阵, 或者 batch 个矩阵,batch_shape 以 list 的形式传入 |
| tf.diag(diagonal, name=None) | 构建一个对角矩阵 |
| tf.global_variables_initializer() | 初始化全部变量 |
# 3.2 Tensor转换函数
| 用法 | 说明 |
|---|---|
| tf.random_shuffle(value, seed=None, name=None) | 沿其第一维度随机打乱 |
| tf.set_random_seed(seed) | 设置图级随机种子 |
| tf.string_to_number(string_tensor, out_type=None, name=None) | 张量变换 |
| tf.to_double(x, name='ToDouble') | 张量变换 |
| tf.to_float(x, name='ToFloat') | 张量变换 |
| tf.to_bfloat16(x, name='ToBFloat16') | 张量变换 |
| tf.to_int32(x, name='ToInt32') | 张量变换 |
| tf.to_int64(x, name='ToInt64') | 张量变换 |
| tf.cast(x, dtype, name=None) | 张量变换 |
| tf.shape(input, name=None) | 用于确定张量的形状并更改张量的形状 |
| tf.size(input, name=None) | 用于确定张量的形状并更改张量的形状 |
| tf.rank(input, name=None) | 用于确定张量的形状并更改张量的形状 |
| tf.reshape(tensor, shape, name=None) | 用于确定张量的形状并更改张量的形状 |
| tf.squeeze(input, squeeze_dims=None, name=None) | 用于确定张量的形状并更改张量的形状 |
| tf.expand_dims(input, dim, name=None) | 用于确定张量的形状并更改张量的形状 |
| tf.slice(input_, begin, size, name=None) | 切片与扩展 |
| tf.split(split_dim, num_split, value, name='split') | 切片与扩展 |
| tf.tile(input, multiples, name=None) | 切片与扩展 |
| tf.pad(input, paddings, name=None) | 切片与扩展 |
| tf.concat(concat_dim, values, name='concat') | 切片与扩展 |
| tf.pack(values, name='pack') | 切片与扩展 |
| tf.unpack(value, num=None, name='unpack') | 切片与扩展 |
| tf.reverse_sequence(input, seq_lengths, seq_dim, name=None) | 切片与扩展 |
| tf.reverse(tensor, dims, name=None) | 切片与扩展 |
| tf.transpose(a, perm=None, name='transpose') | 切片与扩展 |
| tf.gather(params, indices, name=None) | 切片与扩展 |
| tf.dynamic_partition(data, partitions, num_partitions, name=None) | 切片与扩展 |
| tf.dynamic_stitch(indices, data, name=None) | 切片与扩展 |
# 3.3 逻辑判断
| 用法 | 说明 |
|---|---|
| tf.logical_and(x, y, name=None) | 逻辑运算符 |
| tf.logical_not(x, name=None) | 逻辑运算符 |
| tf.logical_or(x, y, name=None) | 逻辑运算符 |
| tf.logical_xor(x, y, name='LogicalXor') | 逻辑运算符 |
| tf.equal(x, y, name=None) | 比较运算符 |
| tf.not_equal(x, y, name=None) | 比较运算符 |
| tf.less(x, y, name=None) | 比较运算符 |
| tf.less_equal(x, y, name=None) | 比较运算符 |
| tf.greater(x, y, name=None) | 比较运算符 |
| tf.greater_equal(x, y, name=None) | 比较运算符 |
| tf.select(condition, t, e, name=None) | 比较运算符 |
| tf.where(input, name=None) | 比较运算符 |
| tf.is_finite(x, name=None) | 判断检查 |
| tf.is_inf(x, name=None) | 判断检查 |
| tf.is_nan(x, name=None) | 判断检查 |
| tf.verify_tensor_all_finite(t, msg, name=None) 断言张量不包含任何NaN或Inf | 判断检查 |
| tf.check_numerics(tensor, message, name=None) | 判断检查 |
| tf.add_check_numerics_ops() | 判断检查 |
| tf.Assert(condition, data, summarize=None, name=None) | 判断检查 |
| tf.Print(input_, data, message=None, first_n=None, summarize=None, name=None) | 判断检查 |
# 3.4 数学函数
| 用法 | 说明 |
|---|---|
| tf.add(x, y, name=None) | 加法(支持 broadcasting) |
| tf.subtract(x, y, name=None) | 减 |
| tf.multiply(x, y, name=None) | 乘 |
| tf.divide(x, y, name=None) | 除 |
| tf.mod(x, y, name=None) | 取余 |
| tf.pow(x, y, name=None) | 幂 |
| tf.square(x, name=None) | 求平方 |
| tf.sqrt(x, name=None) | 开方 |
| tf.exp(x, name=None) | 自然指数 |
| tf.log(x, name=None) | 自然对数 |
| tf.negative(x, name=None) | 取相反数 |
| tf.sign(x, name=None) | 返回 x 的符号 |
| tf.reciprocal(x, name=None) | 取倒数 |
| tf.abs(x, name=None) | 求绝对值 |
| tf.round(x, name=None) | 四舍五入 |
| tf.ceil(x, name=None) | 向上取整 |
| tf.floor(x, name=None) | 向下取整 |
| tf.rint(x, name=None) | 取最接近的整数 |
| tf.maximum(x, y, name=None) | 返回两tensor中的最大值 (x > y ? x : y) |
| tf.minimum(x, y, name=None) | 返回两tensor中的最小值 (x < y ? x : y) |
| tf.cos(x, name=None) | 三角函数和反三角函数 |
| tf.sin(x, name=None) | 三角函数和反三角函数 |
| tf.tan(x, name=None) | 三角函数和反三角函数 |
| tf.acos(x, name=None) | 三角函数和反三角函数 |
| tf.asin(x, name=None) | 三角函数和反三角函数 |
| tf.atan(x, name=None) | 三角函数和反三角函数 |
| tf.matmul(a,b,name=None) | 矩阵乘法(tensors of rank >= 2) |
| tf.transpose(a, perm=None, name='transpose') | 转置,可以通过指定 perm=[1, 0] 来进行轴变换 |
| tf.trace(x, name=None) | 求矩阵的迹 |
| tf.matrix_determinant(input, name=None) | 计算方阵行列式的值 |
| tf.matrix_inverse(input, adjoint=None, name=None) | 求解可逆方阵的逆 |
| tf.svd(tensor, name=None) | 奇异值分解 |
| tf.qr(input, full_matrices=None, name=None) | QR 分解 |
| tf.norm(tensor, ord='euclidean', axis=None, keep_dims=False, name=None) | 求张量的范数(默认2) |
# 3.5 聚合相关
| 用法 | 说明 |
|---|---|
| tf.reduce_sum(input_tensor, axis=None, keep_dims=False, name=None) | 计算输入 tensor 所有元素的和,或者计算指定的轴所有元素的和 |
| tf.reduce_mean(input_tensor, axis=None, keep_dims=False, name=None) | 求均值 |
| tf.reduce_max(input_tensor, axis=None, keep_dims=False, name=None) | 求最大值 |
| tf.reduce_min(input_tensor, axis=None, keep_dims=False, name=None) | 求最小值 |
| tf.reduce_prod(input_tensor, axis=None, keep_dims=False, name=None) | 求累乘 |
| tf.reduce_all(input_tensor, axis=None, keep_dims=False, name=None) | 全部满足条件 |
| tf.reduce_any(input_tensor, axis=None, keep_dims=False, name=None) | 至少有一个满足条件 |
# 3.6 序列比较与索引提取
| 用法 | 说明 |
|---|---|
| tf.setdiff1d(x, y, index_dtype=tf.int32, name=None) | 比较两个 list 或者 string 的不同,并返回不同的值和索引 |
| tf.unique(x, out_idx=None, name=None) | 返回 x 中的唯一值所组成的tensor 和原 tensor 中元素在现 tensor 中的索引 |
| tf.where(condition, x=None, y=None, name=None) | x if condition else y, condition 为 bool 类型的 |
| tf.argmax(input, axis=None, name=None, output_type=tf.int64) | 返回沿着坐标轴方向的最大值的索引 |
| tf.argmin(input, axis=None, name=None, output_type=tf.int64) | 返回沿着坐标轴方向的最小值的索引 |
| tf.invert_permutation(x, name=None) | x 的值当作 y 的索引,range(len(x)) 索引当作 y 的值 |
| tf.edit_distance(x,y) | 编辑距离 |
# 4.Graph
| 用法 | 说明 |
|---|---|
| tf.get_default_graph() | 访问默认图 |
| tf.Graph.seed | 此图内使用的随机种子 |
| tf.Graph.init() | 创建一个新的空的图 |
| tf.Graph.as_default() | 返回一个使得当前图成为默认图的上下文管理器 |
| tf.Graph.as_graph_def(from_version=None, add_shapes=False) | 返回一个表示这个图的序列化的 GraphDef。 |
| tf.Graph.as_graph_element(obj, allow_tensor=True, allow_operation=True) | 给定一个obj,看它能否对应到图中的元素 |
| tf.Graph.get_operation_by_name(name) | 根据名字获取某个operation |
| tf.Graph.get_tensor_by_name(name) | 根据名字获取某个tensor |
| tf.Graph.get_operations() | 获取所有operations |
| tf.Graph.is_feedable(tensor) | 判断是否可feed或可fetch |
| tf.Graph.is_fetchable(tensor_or_op) | 判断是否可feed或可fetch |
| tf.Graph.prevent_feeding(tensor) | 设置不可feed或不可fetch |
| tf.Graph.prevent_fetching(op) | 设置不可feed或不可fetch |
| tf.Graph.finalize() | 结束这个图,使它只读,不能向g添加任何新的操作 |
| tf.Graph.finalized | 如果这个图已经结束,它为真 |
| tf.Graph.control_dependencies(control_inputs) | 返回一个明确控制依赖(control dependencies)的上下文管理器 |
| tf.Graph.devide(device_name_or_function) | 返回一个明确默认设备的使用的上下文管理器 |
| tf.Graph.name_scope(name) | 返回为操作创建分层的上下文管理器 |
| tf.Graph.add_to_collection(name,value) | 将value值存入给定name的collection |
| tf.Graph.add_to_collections(names,value) | 将value存入给定的names的collections中 |
| tf.Graph.get_collection(name,scope=None) | 返回给定名称集合的值的列表 |
# 5.Session
| 用法 | 说明 |
|---|---|
| tf.Session() | |
| tf.InteractiveSession() | |
| tf.get_default_session() | 获取默认session |
| tf.Session().graph | |
| tf.Session(). init(self, target='', graph=None, config=None) | |
| tf.Session().as_default() | 返回使该对象成为默认session的上下文管理器. |
| tf.Session().close | 关闭这个session |
| tf.Session().list_devices() | 列出此session中的可用设备. |
| tf.Session().run(fetches,feed_dict=None) | 执行 |
| tf.Session().reset(target) | 在target上重置资源容器,并关闭所有连接的会话. |
# 附录
https://www.jianshu.com/p/55a47b1720ba https://www.cnblogs.com/qjoanven/p/7736025.html https://blog.csdn.net/xun527/article/details/79690226 https://blog.bitsrc.io/learn-tensorflow-fundamentals-in-20-minutes-cdef2dec331a https://blog.csdn.net/kmsj0x00/article/details/80698794 https://www.w3cschool.cn/tensorflow_python/tensorflow_python-slp52jz8.html
# 参考文章
- https://www.cnblogs.com/raisok/p/12659627.html
- https://zhuanlan.zhihu.com/p/52550025
- https://blog.csdn.net/qq_37388085/article/details/108250718
- https://www.cnblogs.com/arachis/p/TF_BASICS.html
- https://www.icourse163.org/course/PKU-1002536002?tid=1002700003










