TIP
本文主要是介绍 Netty-入门案例介绍 。
# Netty入门与实战教程
前言:都说Netty是Java程序员必须要掌握的一项技能,带着不止要知其然还要知其所以然的目的,在慕课上找了一个学习Netty源码的教程,看了几章后着实有点懵逼。虽然用过Netty,并且在自己的个人网站上实现了聊天室的功能。但是使用的还是Netty很少一部分功能,很多组件都没涉及,很多API也似懂非懂。基础都没打牢,学习源码肯定懵逼。正好在掘金小册上找到了一个Netty入门的教程,链接放在最后【非广告】。学习过后,整理出了这么一篇博客。写这篇博客的目的一个是为了分享,另一个目的就是为了做个笔记,之后自己也可以当资料回顾一下。
在学习Netty前的必需知识:NIO。如果不了解可以看这篇:手动搭建I/O网络通信框架3:NIO编程模型,升级改造聊天室 (opens new window)。对于BIO和AIO可以只看文字了解一下,但是NIO编程模型最好还是动手实践一下,毕竟NIO目前是使用最广的。还有一篇Netty实战SpringBoot+Netty+WebSocket实现实时通信 (opens new window)。这是我实现个人网站的聊天室时写的一篇,文字内容很少,主要是代码,最好粗略看看代码,因为下面有几个地方会和这篇代码做一些比较,下面统称Netty实战。如果现在看不懂,等你认真看到这篇博客的pipeline那里,应该都会看懂。Netty实战中的客户端是Web,配合一些前端IM框架,客户端实现起来非常简单。但是聊天通讯的功能在APP中多一些,所以下面会说到Netty在客户端中的使用。下面所有代码都确保可以正确运行,如果哪里有问题,请留言指出,谢谢。
# Netty是什么?
官方定义:Netty 是一个异步事件驱动的网络应用框架,用于快速开发可维护的高性能服务器和客户端。
简单地说Netty封装了JDK的NIO,不用再写一大堆复杂的代码。既然代替了原生的NIO,肯定有比它好的理由,主要有如下几点:
1.Netty底层IO模型可以随意切换,比如可以从NIO切换到BIO,但一般很少会这么做。
2.Netty自带拆包解包,从NIO各种繁复的细节中脱离出来,让开发者重点关心业务逻辑。
3.Netty解决了NIO中Selector空轮询BUG,这个BUG应该很多人听说过,虽然官方声明jdk1.6的update18修复了该问题,只不过是降低了发生的概率。
4.对Selector做了很多细小的优化,reactor线程模型能做到高效的并发处理。
# 服务端启动类详解
精简的服务端Demo,与上面那篇Netty实战中的代码相比只有一个启动类,少了业务代码和初始化器。
public class NettyServer {
public static void main(String[] args) {
NioEventLoopGroup bossGroup = new NioEventLoopGroup();
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap
.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
protected void initChannel(NioSocketChannel ch) {
}
});
serverBootstrap.bind(8000);
}
}
- 两个NioEventLoopGroup对象,可以看作两个线程组。bossGroup的作用是监听客户端请求。workerGroup的作用是处理每条连接的数据读写。
- ServerBootstrap是一个引导类,其对象的作用是引导服务器的启动工作。
- .group是配置上面两个线程组的角色,也就是谁去监听谁去处理读写。上面只是创建了两个线程组,并没有实际使用。
- .channel是配置服务端的IO模型,上面代码配置的是NIO模型。也可以配置为BIO,如OioServerSocketChannel.class。
- .childHandler用于配置每条连接的数据读写和业务逻辑等。上面代码用的是匿名内部类,并没有什么内容。实际使用中为了规范起见,一般会再写一个单独的类也就是初始化器,在里面写上需要的操作。就如Netty实战那篇中的代码一样。
- 最后就是绑定监听端口了。
引导类最小化的参数配置就是如上四个:配置线程组、IO模型、处理逻辑、绑定端口。
# 引导类serverBootstrap 的其他方法:
1.handler()方法:上面的cildHandler是处理连接的读写逻辑,这个是用于指定服务端启动中的逻辑.
serverBootstrap.handler(new ChannelInitializer<NioServerSocketChannel>() {
protected void initChannel(NioServerSocketChannel ch) {
System.out.println("服务端启动中");
}
})
2.attr()方法:给服务端的channel指定一些自定义属性。然后通过channel.attr()取出这个属性,其实就是给channel维护一个map。一般也用不上。
3.childAttr()方法:作用和上面一样,这个是针对客户端的channel。
4.option()方法:给服务端的channel设置属性,如
serverBootstrap.option(ChannelOption.SO_BACKLOG, 1024)
上面代码表示系统用于临时存放已完成三次握手的请求的队列的最大长度,如果连接建立频繁,服务器处理创建新连接较慢,可以适当调大这个参数
5.childOption()方法:大家肯定已经明白了Netty的命名规律,这个是给每条客户端连接设置TCP相关的属性,如
serverBootstrap
//开启TCP底层心跳机制
.childOption(ChannelOption.SO_KEEPALIVE, true)
//开启Nagle算法,如果要求高实时性,有数据发送时就马上发送,就关闭,如果需要减少发送次数减少网络交互,就开启。
.childOption(ChannelOption.TCP_NODELAY, true)
# 客户端启动类
还是说说那篇Netty实战,里面的客户端是Web,所以用到了WebSocket。主要的重点还是在服务端上,客户端实现起来相对容易,因为它只用发送消息和接收消息。下面依旧写出一个精简的客户端Demo,可以根据自己的项目类型还选择客户端的实现。
public class NettyClient {
public static void main(String[] args) {
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
Bootstrap bootstrap = new Bootstrap();
bootstrap
// 1.指定线程模型
.group(workerGroup)
// 2.指定 IO 类型为 NIO
.channel(NioSocketChannel.class)
// 3.IO 处理逻辑
.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
}
});
// 4.建立连接
bootstrap.connect("127.0.0.1", 8000).addListener(future -> {
if (future.isSuccess()) {
System.out.println("连接成功!");
} else {
System.err.println("连接失败!");
//重新连接
}
});
}
}
弄懂服务端代码后,客户端就很好理解了,就不再一一说明了。主要作用就在注释中。
# 重新连接
网络环境差的情况下,客户端第一次连接可能会失败,所以我们需要尝试重新连接。可以把连接connect上面的代码封装起来,然后传入一个Bootstrap类型的对象,通过这个对象循环连接。但是一般情况下,连接失败后不会马上重连,而是会通过一个指数退避的方式,比如每隔1s、2s、4s、8s....重新连接。
int MAX_RETRY=5;
connect(bootstrap, "127.0.0.1", 8000, MAX_RETRY);
private static void connect(Bootstrap bootstrap, String host, int port, int retry) {
bootstrap.connect(host, port).addListener(future -> {
if (future.isSuccess()) {
System.out.println("连接成功!");
} else if (retry == 0) {
System.err.println("重试次数已用完,放弃连接!");
} else {
// 第几次重连
int order = (MAX_RETRY - retry) + 1;
// 本次重连的间隔,1<<order相当于1乘以2的order次方
int delay = 1 << order;
System.err.println(new Date() + ": 连接失败,第" + order + "次重连……");
bootstrap.config().group().schedule(() -> connect(bootstrap, host, port, retry - 1), delay, TimeUnit
.SECONDS);
}
});
}
在上面的代码中,我们看到,我们定时任务是调用 bootstrap.config().group().schedule(), 其中 bootstrap.config() 这个方法返回的是 BootstrapConfig,他是对 Bootstrap 配置参数的抽象,然后 bootstrap.config().group() 返回的就是我们在一开始的时候配置的线程模型 workerGroup,调 workerGroup 的 schedule 方法即可实现定时任务逻辑。
在 schedule 方法块里面,前面四个参数我们原封不动地传递,最后一个重试次数参数减掉一,就是下一次建立连接时候的上下文信息。我们可以自行修改代码,更改到一个连接不上的服务端 Host 或者 Port,查看控制台日志就可以看到5次重连日志。
bootstrap的其他方法,attr()和option()。作用和服务端的方法一样。attr设置自定义属性,option设置TCP相关的属性。
# 数据传输的载体:ByteBuf
NIO中经常使用的ByteBuffer,但它还有一些缺陷:
1.长度固定。2.读写状态需要通过filp()和rewind()手动转换。3.功能有限。
如果看过上面NIO那篇博客中聊天室Demo,其实都会发现这些问题。长度设置固定的1024个字节,读写也要用filp()转换。所以Netty为了解决ByteBuffer的这些缺陷,设计了ByteBuf。其结构如下:
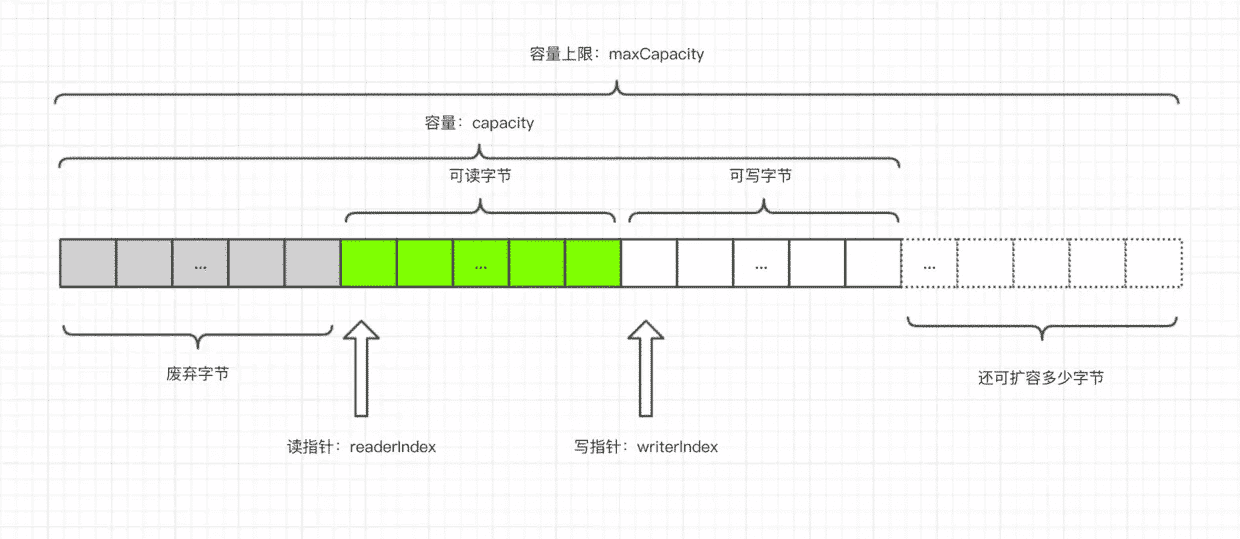
- ByteBuf 是一个字节容器,容器里面的的数据分为三个部分,第一个部分是已经丢弃的字节,这部分数据是无效的;第二部分是可读字节,这部分数据是 ByteBuf 的主体数据, 从 ByteBuf 里面读取的数据都来自这一部分;最后一部分的数据是可写字节,所有写到 ByteBuf 的数据都会写到这一段。最后一部分虚线表示的是该 ByteBuf 最多还能扩容多少容量。
- 以上三段内容是被两个指针给划分出来的,从左到右,依次是读指针(readerIndex)、写指针(writerIndex),然后还有一个变量 capacity,表示 ByteBuf 底层内存的总容量。
- 从 ByteBuf 中每读取一个字节,readerIndex 自增1,ByteBuf 里面总共有 writerIndex-readerIndex 个字节可读, 由此可以推论出当 readerIndex 与 writerIndex 相等的时候,ByteBuf 不可读。
- 写数据是从 writerIndex 指向的部分开始写,每写一个字节,writerIndex 自增1,直到增到 capacity,这个时候,表示 ByteBuf 已经不可写了。
- ByteBuf 里面其实还有一个参数 maxCapacity,当向 ByteBuf 写数据的时候,如果容量不足,那么这个时候可以进行扩容,直到 capacity 扩容到 maxCapacity,超过 maxCapacity 就会报错。
# ByteBuf的API
capacity():表示ByteBuf底层占用了多少字节,包括丢弃字节、可读字节、可写字节。
maxCapacity():表示ByteBuf最大能占用多少字节,也就是包括后面的可扩容的内存。
readableBytes() 与 isReadable():前者表示当前可读字节数,也就是写指针-读指针。后者表示是否可读。
writableBytes()、 isWritable() 与 maxWritableBytes():第一个表示可写字节数。第二个表示是否可写。第三个表示最大可写字节数。
readerIndex() 与 readerIndex(int):前者返回当前的读指针。后者可以设置读指针。
writeIndex() 与 writeIndex(int):和上面一样,只是读指针变成了写指针。
markReaderIndex() 与 resetReaderIndex():前者表示把当前读指针保存起来。后者表示把当前的读指针恢复到保存时的值。他们的功能其实readerIndex() 与 readerIndex(int)一样可以实现,但一般会选择下面两句,因为不用定义一个变量。
int readerIndex = buffer.readerIndex();
buffer.readerIndex(readerIndex);
//和上面两句等价
buffer.markReaderIndex();
buffer.resetReaderIndex();
writeBytes(byte[] src) 与 buffer.readBytes(byte[] dst):前者表示把src写到ByteBuf。后者表示把ByteBuf全部数据读取到dst。
writeByte(byte b) 与 buffer.readByte():前者表示把字节b写道ByteBuf。后者表示从ByteBuf读取一个字节。类似的 API 还有 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble() 与 readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble() 这里就不一一赘述了。
release() 与 retain():由于 Netty 使用了堆外内存,而堆外内存是不被 jvm 直接管理的,也就是说申请到的内存无法被垃圾回收器直接回收,所以需要我们手动回收。Netty 的 ByteBuf 是通过引用计数的方式管理的,如果一个 ByteBuf 没有地方被引用到,需要回收底层内存。默认情况下,当创建完一个 ByteBuf,它的引用为1,然后每次调用 retain() 方法, 它的引用就加一, release() 方法原理是将引用计数减一,减完之后如果发现引用计数为0,则直接回收 ByteBuf 底层的内存。
slice()、duplicate()、copy():这三个都会返回一个新的ByteBuf。第一个是截取读指针到写指针范围内的一段内容。第二个是截取整个ByteBuf,包括数据和指针信息。第三个是拷贝所有信息,除了第二个API的内容还包括底层信息,因此拷贝后的新ByteBuf任何操作不会影响原始的ByteBuf。
# 实战:服务端和客户端双向通信
了解客户端、服务端的启动类和ByteBuf以后,可以进行一个简单的实战了。
首先看看前面的客户端代码,.handler里重写的initChannel方法并没实际内容。现在加上逻辑处理器,其实就是一个执行逻辑代码的类,怎么叫无所谓,明白它的意思就行。
客户端
.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new FirstClientHandler());
}
});
ch.pipeline().addLast()就是添加一个逻辑处理器。我们在FirstClientHandler里添加对应的逻辑代码就行。
public class FirstClientHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx) {
System.out.println("客户端发送消息...");
// 1. 获取数据
ByteBuf buffer = getByteBuf(ctx);
// 2. 写数据
ctx.channel().writeAndFlush(buffer);
}
private ByteBuf getByteBuf(ChannelHandlerContext ctx) {
// 1. 获取二进制抽象 ByteBuf
ByteBuf buffer = ctx.alloc().buffer();
// 2. 准备数据,指定字符串的字符集为 utf-8
byte[] bytes = ("【客户端】:这是客户端发送的消息:"+new Date()).getBytes(Charset.forName("utf-8"));
// 3. 填充数据到 ByteBuf
buffer.writeBytes(bytes);
return buffer;
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf byteBuf = (ByteBuf) msg;
//接收服务端的消息并打印
System.out.println(byteBuf.toString(Charset.forName("utf-8")));
}
}
- channelActive()方法会在客户端与服务器建立连接后调用。所以我们可以在这里面编写逻辑代码
- .alloc().buffer()的作用是把字符串的二进制数据填充到ByteBuf。
- .writeBytes()的作用是把数据写到服务器。
- channelRead()在接受到服务端的消息后调用。
服务端
同样的我们需要在initChannel()里添加一个逻辑处理器。
.childHandler(new ChannelInitializer<NioSocketChannel>() {
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast(new FirstServerHandler());
}
});
逻辑处理器里的代码
public class FirstServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf byteBuf = (ByteBuf) msg;
System.out.println(new Date() + ": 服务端读到数据 -> " + byteBuf.toString(Charset.forName("utf-8")));
//接收到客户端的消息后我们再回复客户端
ByteBuf out = getByteBuf(ctx);
ctx.channel().writeAndFlush(out);
}
private ByteBuf getByteBuf(ChannelHandlerContext ctx) {
byte[] bytes = "【服务器】:我是服务器,我收到你的消息了!".getBytes(Charset.forName("utf-8"));
ByteBuf buffer = ctx.alloc().buffer();
buffer.writeBytes(bytes);
return buffer;
}
}
channelRead()方法在接收到客户端发来的数据后调用。
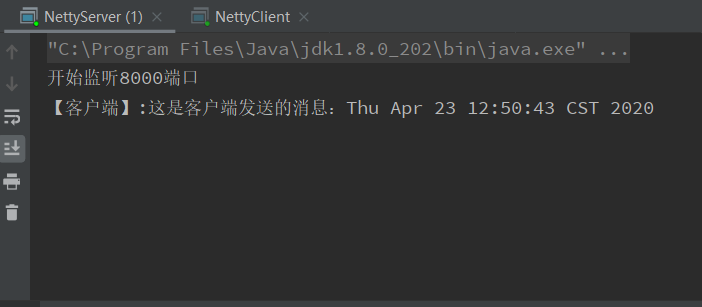
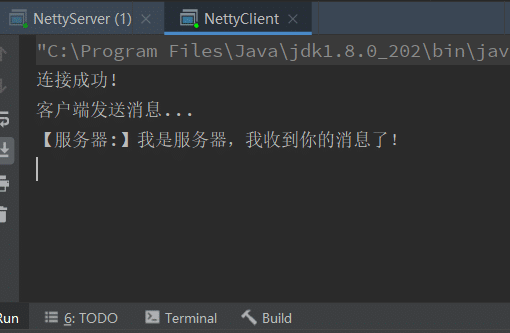
最后我们启动客户端和服务端的启动类,效果如下:
# 自定义客户端与服务端的通信协议
# 什么是通信协议?
TCP通信的数据包格式均为二进制,协议指的就是客户端与服务端制定一个规则,这个规则规定了每个二进制数据包中每一段的字节代表什么含义。客户端与服务端通信的过程如下。
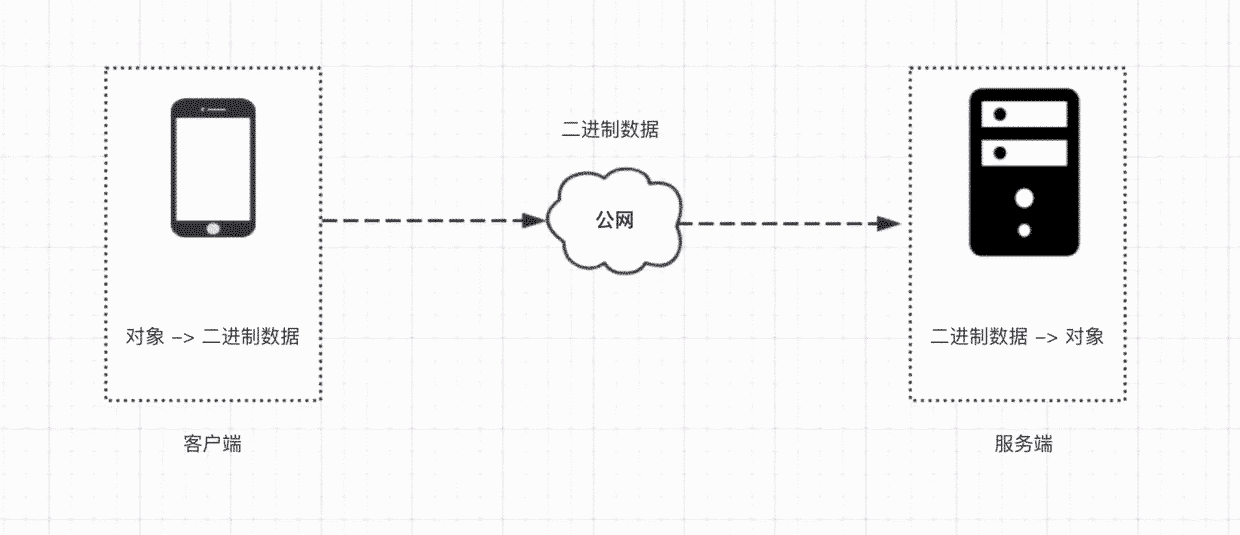
客户端首先把一个Java对象转换成二进制数据,然后通过网络传输给服务端。这里的传输过程属于TCP/IP协议负责,与我们应用层无关。
# 通信协议的设计

1.第一个字段是魔数,可以理解为识别这条二进制数据类型的字段。在《深入理解Java虚拟机》中这么解释:使用魔数而不是扩展名来进行识别主要是基于安全方面的考虑,因为文件扩展名可以随意地改动。文件格式的制定者可以自由地选择魔数值,只要这个魔数值还没有被广泛采用过同时又不会引起混淆即可。
2.第二个是版本号,就像IPV4和IPV6一样。能够支持协议的升级。
3.第三个表示如何把Java对象转换成二进制数据和把二进制数据转回Java对象。
4.第四个用于区分这条数据是干嘛的或者说叫数据类型,如:这是发送的消息,还是登录的请求等。服务端就可以根据这个指令执行不同的逻辑代码。
5.第五个代表后面的数据长度。
6.第六个代表发送的数据,如果指令表明这是个登录数据,里面存储的就是账号密码。
# 通信协议的实现
以实现登录为例,下面接口和类有点多,建议先把代码拷贝到IDE里,分好包写好注释,助于理解它们的关系。
1.首先创建一个Java对象,这里以登录时的请求响应为例
@Data
public abstract class Packet {
//协议版本
private Byte version = 1;
//获取数据类型
public abstract Byte getCommand();
}
@Date注解由lombok提供,不了解的可以看看这个https://www.cnblogs.com/lbhym/p/12551021.html
public interface Command {
//定义登录请求指令和响应指令为1和2,其他的指令同理如MESSAGE_REQUEST等
Byte LOGIN_REQUEST = 1;
Byte LOGIN_RESPONSE = 2;
}
//这个是登录请求数据包的Java对象,所以调用的是上面接口的登录请求指令,其他类型的数据包同理
@Data
public class LoginRequestPacket extends Packet {
//定义用户信息
private Integer userId;
private String username;
private String password;
@Override
public Byte getCommand() {
return LOGIN_REQUEST;
}
}
@Data
public class LoginResponsePacket extends Packet {
//是否登录成功
private boolean success;
//如果失败,返回的信息
private String reason;
@Override
public Byte getCommand() {
return LOGIN_RESPONSE;
}
}
2.Java对象创建完了,再定义Java对象转换的规则
//序列化接口
public interface Serializer {
Serializer DEFAULT = new JSONSerializer();
//序列化算法
byte getSerializerAlogrithm();
//java 对象转换成二进制
byte[] serialize(Object object);
//二进制转换成 java 对象
<T> T deserialize(Class<T> clazz, byte[] bytes);
}
接口定义完后开始实现接口。这里的序列化算法使用的是fastjson里面的。需要在pom.xml里导入。
public interface SerializerAlgorithm {
//json序列化标识,如果你有其他的序列化方式可以在这注明标识,类似上面的登录指令
byte JSON = 1;
}
//实现上面定义的序列化接口
public class JSONSerializer implements Serializer {
@Override
public byte getSerializerAlgorithm() {
//获取上面的序列化标识
return SerializerAlgorithm.JSON;
}
@Override
public byte[] serialize(Object object) {
return JSON.toJSONBytes(object);
}
@Override
public <T> T deserialize(Class<T> clazz, byte[] bytes) {
return JSON.parseObject(bytes, clazz);
}
}
3.创建一个类PacketCodeC,里面写上编解码的方法。这里再说一点,因为使用了@Data注解,所以有的get方法在语法检测阶段会报错,可以在IDEA里面下载Lombok插件。
public class PacketCodeC {
//自定义一个魔数
private static final int MAGIC_NUMBER = 0x12345678;
//创建一个静态实例供外部调用
public static final PacketCodeC INSTANCE=new PacketCodeC();
//创建两个map,一个存储数据类型,如:是登录数据还是普通消息等。第二个是存储序列化类型。
//这样在解码时就可以把数据转换为对应的类型。如:这个byte数组是LOGIN_REQUEST类型,就把它转换成LoginRequestPacket类型的Java对象
private final Map<Byte, Class<? extends Packet>> packetTypeMap;
private final Map<Byte, Serializer> serializerMap;
private PacketCodeC() {
//初始化map并添加数据类型和序列化类型,如果有其他数据类型,记得在这里添加
packetTypeMap = new HashMap<>();
packetTypeMap.put(LOGIN_REQUEST, LoginRequestPacket.class);
packetTypeMap.put(LOGIN_RESPONSE, LoginResponsePacket.class);
serializerMap = new HashMap<>();
Serializer serializer = new JSONSerializer();
serializerMap.put(serializer.getSerializerAlogrithm(), serializer);
}
//编码
public ByteBuf encode(ByteBufAllocator bufAllocator,Packet packet) {
// 1. 创建 ByteBuf 对象
ByteBuf byteBuf = bufAllocator.ioBuffer();
// 2. 序列化 Java 对象
byte[] bytes = Serializer.DEFAULT.serialize(packet);
// 3. 实际编码过程,把通信协议几个部分,一一编码
byteBuf.writeInt(MAGIC_NUMBER);
byteBuf.writeByte(packet.getVersion());
byteBuf.writeByte(Serializer.DEFAULT.getSerializerAlogrithm());
byteBuf.writeByte(packet.getCommand());
byteBuf.writeInt(bytes.length);
byteBuf.writeBytes(bytes);
return byteBuf;
}
//解码
public Packet decode(ByteBuf byteBuf) {
// 跳过魔数
byteBuf.skipBytes(4);
// 跳过版本号
byteBuf.skipBytes(1);
// 序列化算法标识
byte serializeAlgorithm = byteBuf.readByte();
// 指令
byte command = byteBuf.readByte();
// 数据包长度
int length = byteBuf.readInt();
byte[] bytes = new byte[length];
byteBuf.readBytes(bytes);
Class<? extends Packet> requestType = getRequestType(command);
Serializer serializer = getSerializer(serializeAlgorithm);
if (requestType != null && serializer != null) {
return serializer.deserialize(requestType, bytes);
}
return null;
}
//获取序列化类型
private Serializer getSerializer(byte serializeAlgorithm) {
return serializerMap.get(serializeAlgorithm);
}
//获取数据类型
private Class<? extends Packet> getRequestType(byte command) {
return packetTypeMap.get(command);
}
}
# 使用自定义通信协议
最后通过一个登录示例,来使用一下上面自定义的通信协议。
基于上面的代码,首先更换一下客户端和服务端的逻辑处理器,直接在原来的逻辑处理器里面修改逻辑代码也行。
.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new ClientHandler());
}
});
.childHandler(new ChannelInitializer<NioSocketChannel>() {
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast(new ServerHandler());
}
}
客户端在连接上服务端后立即登录,下面为客户端登录代码
public class ClientHandler extends ChannelInboundHandlerAdapter{
@Override
public void channelActive(ChannelHandlerContext ctx) {
System.out.println(new Date() + ": 客户端开始登录");
// 创建登录对象
LoginRequestPacket loginRequestPacket = new LoginRequestPacket();
loginRequestPacket.setUserId(new Random().nextInt(10000));
loginRequestPacket.setUsername("username");
loginRequestPacket.setPassword("pwd");
// 编码
ByteBuf buffer = PacketCodeC.INSTANCE.encode(ctx.alloc(), loginRequestPacket);
// 写数据
ctx.channel().writeAndFlush(buffer);
}
//接收服务端信息
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf byteBuf = (ByteBuf) msg;
Packet packet = PacketCodeC.INSTANCE.decode(byteBuf);
//如果数据类型是登录,就进行登录判断
//同理可以判断数据是否是普通消息,还是其他类型的数据
if (packet instanceof LoginResponsePacket) {
LoginResponsePacket loginResponsePacket = (LoginResponsePacket) packet;
if (loginResponsePacket.isSuccess()) {
System.out.println(new Date() + ": 客户端登录成功");
} else {
System.out.println(new Date() + ": 客户端登录失败,原因:" + loginResponsePacket.getReason());
}
}
}
}
下面是服务端代码
public class ServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf requestByteBuf = (ByteBuf) msg;
// 解码
Packet packet = PacketCodeC.INSTANCE.decode(requestByteBuf);
// 判断是否是登录请求数据包
if (packet instanceof LoginRequestPacket) {
LoginRequestPacket loginRequestPacket = (LoginRequestPacket) packet;
LoginResponsePacket loginResponsePacket=new LoginResponsePacket();
loginResponsePacket.setVersion(packet.getVersion());
// 登录校验
if (valid(loginRequestPacket)) {
// 校验成功
loginResponsePacket.setSuccess(true);
System.out.println("客户端登录成功!");
} else {
// 校验失败
loginResponsePacket.setReason("账号或密码错误");
loginResponsePacket.setSuccess(false);
System.out.println("客户端登录失败!");
}
// 编码,结果发送给客户端
ByteBuf responseByteBuf = PacketCodeC.INSTANCE.encode(ctx.alloc(), loginResponsePacket);
ctx.channel().writeAndFlush(responseByteBuf);
}
}
private boolean valid(LoginRequestPacket loginRequestPacket) {
//这里可以查询数据库,验证用户的账号密码是否正确
return true;
}
}
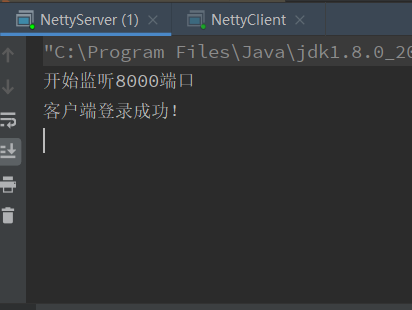
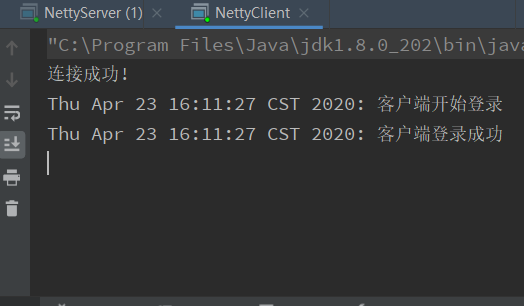
最后演示效果如图所示:
# 自己实现收发消息
按照上面的登录功能,可以自己尝试实现一下收发消息的功能。首先还是要定义一个收发消息的Java对象。还需要在Command里面加上收发消息的指令,在编解码类里面的map添加Java对象。收发消息前,肯定需要登录。那么怎么判断一个客户端是否登录呢?可以通过ctx获取channel,然后通过channel的attr方法设置属性。如果登录成功这个属性就设为true。然后在客户端的启动类里连接成功后,新建一个线程专门监听用户的输入,新建输入线程前判断一下登录属性是否为true就行了。其他的地方跟登录就没有太大差别了。
# pipeline与channelHandler
通过上面的一些实战,可以发现我们所有的逻辑代码都写在了一个Handler类里面,幸好现在需要处理的业务不是很多。如果以后功能拓展,这个类会变得非常臃肿。Netty中的pipeline和channelHandler就是解决这个问题的,它们通过责任链设计模式来组织代码逻辑,并且能够支持逻辑的添加和删除,能够支持各类协议拓展,如HTTP、Websocket等。可以看看Netty实战博客中的初始化器类,里面就是通过pipeline添加了各类协议和一些逻辑代码。
# pipeline与channelHandler的构成
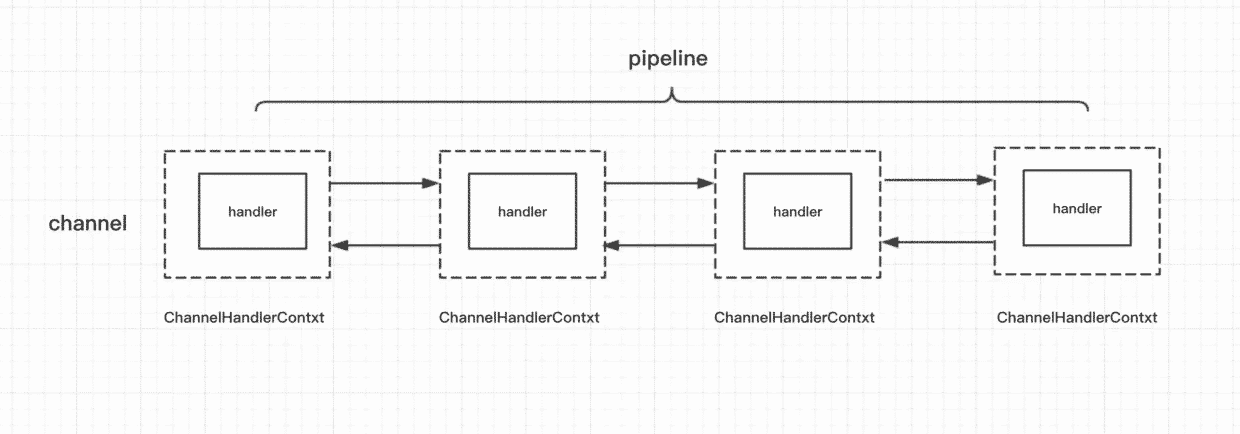
我们知道一个连接对应一个channel,这个channel的所有处理逻辑在一个ChannelPipeline对象里,就是上图中的pipeline,这是它的对象名。然后这个对象里面是一个双向链表结构,每个节点是一个ChannelHandlerContext对象。这个对象能拿到与channel相关的所有上下文信息,这个对象还包含一个重要的对象:ChannelHandler,它的分类如下。
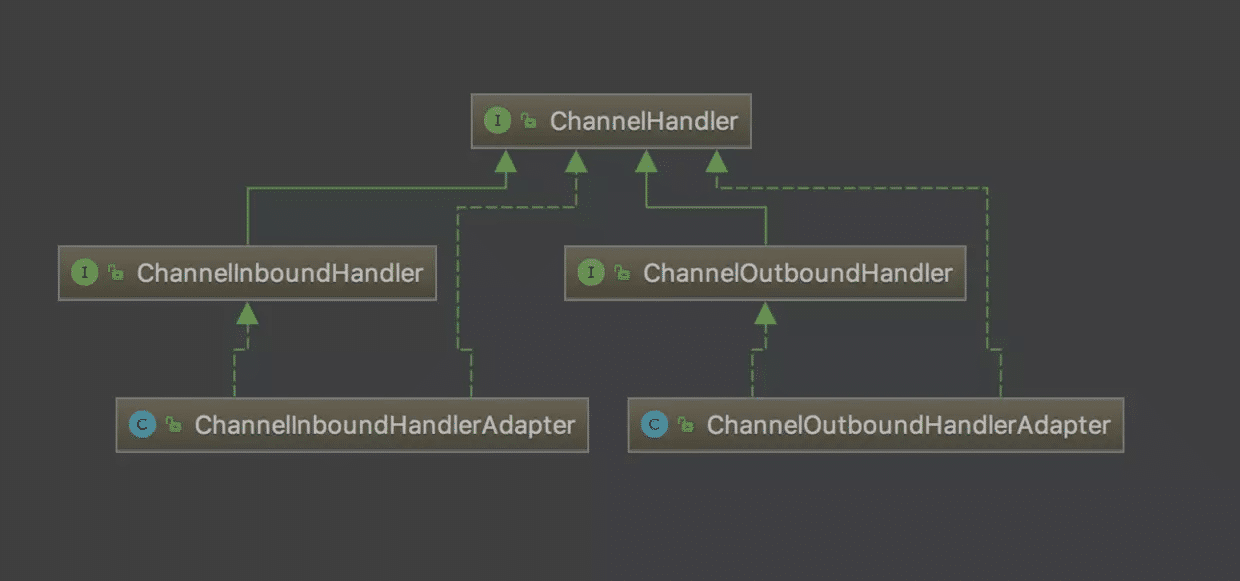
简单地说,它包含两个接口和这两个接口的实现类,图中左边的实现类是不是很熟悉,就是我们自己写的逻辑处理器里的继承的类。从名字就可以看出,它们的作用分别是读数据和写数据,或理解为入站和出战。最重要的两个方法分别为channelRead():消息入站。和write():消息出战。
# 构建客户端与服务端的pipeline
下面的代码基于上面的登录示例改造。
我们先了解一下ByteToMessageDecoder这个类。不论客户端还是服务端收到数据后,都会先进行解码,这个类就是Netty提供的专门做这个事情的。使用如下:
public class PacketDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List out) {
out.add(PacketCodeC.INSTANCE.decode(in));
}
}
这个类有一个好处就是,ByteBuf默认使用的是堆外内存,而它会帮你自动释放内存,无需我们关心。上面是解码,对应的Netty也准备了一个类来专门编码:MessageToByteEncoder.
public class PacketEncoder extends MessageToByteEncoder<Packet> {
@Override
protected void encode(ChannelHandlerContext ctx, Packet packet, ByteBuf out) {
PacketCodeC.INSTANCE.encode(out, packet);
}
}
注意encode传入的参数,第一个参数变成了ByteBuf的类型,所以我们需要把PacketCodeC里的encode方法的参数改过来,也不需要第一行创建一个ByteBuf对象了。
如果不明白为什么要用到这两个类的话,我先展示一段Netty实战博客里面的代码:
public class NettyServerInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
ChannelPipeline pipeline= socketChannel.pipeline();
//http解码器
pipeline.addLast(new HttpServerCodec());
//....
//websocket支持,设置路由
pipeline.addLast(new WebSocketServerProtocolHandler("/ws"));
//添加自定义的助手类(逻辑处理器)
pipeline.addLast(new NettyHandler());
}
}
在这篇实战中我没有实现自己的编解码器,而是直接使用了http的解码器。类似的,我们可以把自己的编解码器也通过pepeline添加到逻辑链中。就像前面说的,可以添加删除逻辑代码,每个功能各司其职,而不是一股脑的全在一个地方。用这两个类还有一个好处就是Netty会自动识别这两个类,从而自动编解码而不需要我们自己去调用。
编解码的问题解决了,再看看逻辑处理器类。看看登录的代码,如果我们不止实现登录功能,还有收发等其他功能,是不是要用大量的if else把各个消息类型分开,然后执行不同的逻辑。不同的逻辑都挤在一个方法中,显然也太拥挤了。因此Netty基于这种考虑,抽象出了SimpleChannelInboundHandler。下面看看它是如何解决这个问题的:
public class ClientLoginHandler extends SimpleChannelInboundHandler<LoginResponsePacket>{
@Override
public void channelActive(ChannelHandlerContext ctx) {
System.out.println("客户端开始登录....");
// 创建登录对象
LoginRequestPacket loginRequestPacket = new LoginRequestPacket();
loginRequestPacket.setUserId(new Random().nextInt(10000));
loginRequestPacket.setUsername("username");
loginRequestPacket.setPassword("pwd");
// 写数据
ctx.channel().writeAndFlush(loginRequestPacket);
}
@Override
protected void channelRead0(ChannelHandlerContext ctx, LoginResponsePacket loginResponsePacket) {
if (loginResponsePacket.isSuccess()) {
System.out.println(new Date() + ": 客户端登录成功");
} else {
System.out.println(new Date() + ": 客户端登录失败,原因:" + loginResponsePacket.getReason());
}
}
}
public class ServerLoginHandler extends SimpleChannelInboundHandler<LoginRequestPacket> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, LoginRequestPacket loginRequestPacket) {
//服务端登录逻辑
ctx.channel().writeAndFlush(login(loginRequestPacket));
}
private LoginResponsePacket login(LoginRequestPacket loginRequestPacket) {
LoginResponsePacket loginResponsePacket = new LoginResponsePacket();
loginResponsePacket.setVersion(loginRequestPacket.getVersion());
// 登录校验(自行判断用户信息是否正确)
if (true) {
// 校验成功
loginResponsePacket.setSuccess(true);
System.out.println("客户端登录成功!");
return loginResponsePacket;
} else {
// 校验失败
loginResponsePacket.setReason("账号或密码错误");
loginResponsePacket.setSuccess(false);
System.out.println("客户端登录失败!");
return loginResponsePacket;
}
}
}
类似的,收发消息也可以这么做。Netty会自动根据抽象类后面的泛型来区分它要调用哪个类。比如我们发送的是一个SendMessage类型的Java对象,它就会在继承了SimpleChannelInboundHandler的类中找到泛型为SendMessage的类去执行。
最后我们要把这些逻辑代码根据服务端和客户端不同的需求添加到它们的pipeline中。
客户端
.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
//解码一定要放在第一个,在这里pipeline按顺序执行,不然接收消息无法正常使用
ch.pipeline().addLast(new PacketDecoder());
ch.pipeline().addLast(new LoginResponseHandler());
ch.pipeline().addLast(new PacketEncoder());
}
});
服务端
.childHandler(new ChannelInitializer<NioSocketChannel>() {
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast(new PacketDecoder());
ch.pipeline().addLast(new LoginRequestHandler());
ch.pipeline().addLast(new PacketEncoder());
}
});
最后的运行结果和登录示例一样。看到这里,Netty实战中的代码,应该可以全部看懂了。
# channelHandler的生命周期
我们在重写ChannelInboundHandlerAdapter或者SimpleChannelInboundHandler里的方法的时候,只用到了读和Active,其他一大堆没用上的方法是干嘛的?现在就一一说明一下,这些方法运作的整个过程,我们可以理解为这个channelHandler的生命周期。以ChannelInboundHandlerAdapter为例,SimpleChannelInboundHandler继承于ChannelInboundHandlerAdapter,所以也差不多,个别方法名不一样而已。下面的API,从上到下,就是触发的顺序。
handlerAdded():逻辑处理器被添加后触发。
channelRegistered():channel绑定到线程组后触发。
channelActive():channel准备就绪,或者说连接完成。
channelRead():channel有数据可读。
channelReadComplete():channel某次数据读完了。
channelInactive():channel被关闭
channelUnregistered():channel取消线程的绑定
handlerRemoved():逻辑处理器被移除。
# 拆包和粘包
以上面客户端和服务端双向通信的代码为例。简单修改一下,在建立连接后,客户端用一个循环向服务器发送消息。然后服务端打印这些消息。
等次数多了以后,服务端打印时会发现一些问题,比如我们发送的字符串为“123456789”,大部分打印的是123456789;有一部分变成了123456789123,这就是粘包;有一部分变为了1234,这就是拆包。
# 为什么会有这种现象?
虽然在我们代码层面,传输的数据单位是ByteBuf。但是到了更底层,用到了TCP协议,终究会按照字节流发送数据。而底层并不知道应用层数据的具体含义,它会根据TCP缓冲区的实际情况进行数据包的划分。所以最终到达服务端的数据产生上面的现象。
# 如何解决?
Netty为我们提供了4种解决方法:
1.FixedLengthFrameDecoder:固定长度拆包器,每个数据包长度都是固定的。
2.LineBasedFrameDecoder:行拆包器,每个数据包之间以换行符作为分隔。
3.DelimiterBasedFrameDecoder:类似行拆包器,不过我们可以自定义分隔符。
4.LengthFieldBasedFrameDecoder:基于长度域拆包器,最常用的,只要你的自定义协议中包含数据长度这个部分,就可以使用。它需要三个参数,第一个是数据包最大长度、第二个是参数长度域偏移量、第三个是长度域长度。

看看前面通信协议的图,所谓长度域就是数据长度就是数据长度占用的字节,这里是4。长度域偏移量就是数据长度这个部分在通信协议组成部分中的位置,前面几个部分加起来是7,所以它的偏移量就是7。
# 使用LengthFieldBasedFrameDecoder
添加到客户端和服务端pipeline中就行了,注意要放在第一个。以服务端为例。
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(Integer.MAX_VALUE, 7, 4));
ch.pipeline().addLast(new PacketDecoder());
ch.pipeline().addLast(new LoginRequestHandler());
ch.pipeline().addLast(new PacketEncoder());
如果和我一样,客户端用到的是WebSocket,没有自定义协议,就不用添加拆包器了,Netty已经帮我们做好了。
# 心跳与空闲检测
网络应用程序普遍会遇到的一个问题就是连接假死。简单地说就是因为网络或其他问题导致某一端实际上(TCP)已经断开连接,但是应用程序没有检测到,以为还连接着。对服务端来说,这会浪费系统资源,导致性能下降。对于客户端来说,假死会造成数据发送超时,影响体验。
# 如何解决这个问题?
只需要客户端每隔一段时间打个招呼,表示它还活着就行了,就是所谓的心跳。Netty自带的IdleStateHandler 就可以实现这个功能。下面就来实现它。
服务端
//心跳检测类
public class IMIdleStateHandler extends IdleStateHandler {
//读空闲时间,也就是多久没读到数据了
private static final int READER_IDLE_TIME = 15;
public IMIdleStateHandler() {
//调用父类构造函数,四个参数分别为:
//读空闲时间、写空闲时间、读写空闲时间、时间单位
super(READER_IDLE_TIME, 0, 0, TimeUnit.SECONDS);
}
@Override
protected void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt) {
System.out.println(READER_IDLE_TIME + "秒内未读到数据,关闭连接");
ctx.channel().close();
}
}
//回复客户端发送的心跳数据包
public class HeartBeatRequestHandler extends SimpleChannelInboundHandler<HeartBeatRequestPacket> {
public static final HeartBeatRequestHandler INSTANCE = new HeartBeatRequestHandler();
private HeartBeatRequestHandler() {
}
@Override
protected void channelRead0(ChannelHandlerContext ctx, HeartBeatRequestPacket requestPacket) {
ctx.writeAndFlush(new HeartBeatResponsePacket());
}
}
ch.pipeline().addLast(new IMIdleStateHandler());//添加到最前面
ch.pipeline().addLast(HeartBeatRequestHandler.INSTANCE);//添加到解码和登录请求之后
客户端
服务端实现了检测读空闲,客户端肯定就需要发送一个数据。
public class HeartBeatTimerHandler extends ChannelInboundHandlerAdapter {
//心跳数据包发送时间间隔,这里设为5秒,实际使用时建议服务端和客户端都设成分钟级别
private static final int HEARTBEAT_INTERVAL = 5;
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
scheduleSendHeartBeat(ctx);
super.channelActive(ctx);
}
private void scheduleSendHeartBeat(ChannelHandlerContext ctx) {
//schedule类似延时任务,每隔5秒发送心跳数据包
ctx.executor().schedule(() -> {
if (ctx.channel().isActive()) {
ctx.writeAndFlush(new HeartBeatRequestPacket());
scheduleSendHeartBeat(ctx);
}
}, HEARTBEAT_INTERVAL, TimeUnit.SECONDS);
}
}
客户端发送心跳数据包后,也需要检测服务端是否回复了自己,所以也需要个检测类,与服务端的代码一样,就不写了。也需要和服务端一样,pipeline添加到相同的位置。
最后:如果服务端在读到数据后,不要再read方法里面直接访问数据库或者其他比较复杂的操作,可以把这些耗时的操作放进我们的业务线程池中去执行。如:
ThreadPool threadPool = xxx;
protected void channelRead0(ChannelHandlerContext ctx, T packet) {
threadPool.submit(new Runnable() {
// 1. balabala 一些逻辑
// 2. 数据库或者网络等一些耗时的操作
// 3. writeAndFlush()
})
}
如果我们想统计某个操作的响应时间,直接用System.currentTimeMillis()其实是不准确的,因为有些操作是异步的,它马上就返回了,所以我们要判断异步结果是否完成再计算结束时间。
protected void channelRead0(ChannelHandlerContext ctx, T packet) {
threadPool.submit(new Runnable() {
long begin = System.currentTimeMillis();
// 1. balabala 一些逻辑
// 2. 数据库或者网络等一些耗时的操作
// 3. writeAndFlush
xxx.writeAndFlush().addListener(future -> {
if (future.isDone()) {
long time = System.currentTimeMillis() - begin;
}
});
})
}
# 资料:https://juejin.im/book/5b4bc28bf265da0f60130116
# 参考文章
- https://www.cnblogs.com/lbhym/p/12753314.html










