TIP
本文主要是介绍 MySQL性能优化方案 。
性能优化(Optimize)指的是在保证系统正确性的前提下,能够更快速响应请求的一种手段。而且有些性能问题,比如慢查询等,如果积累到一定的程度或者是遇到急速上升的并发请求之后,会导致严重的后果,轻则造成服务繁忙,重则导致应用不可用。它对我们来说就像一颗即将被引爆的定时炸弹一样,时刻威胁着我们。因此在上线项目之前需要严格的把关,以确保 MySQL 能够以最优的状态进行运行。
# MySQL 的优化方案有哪些?
MySQL 数据库常见的优化手段分为
# 三个层面:
SQL 和索引优化、数据库结构优化、系统硬件优化等,
MYSQL优化主要分为以下
# 四大方面:
设计:存储引擎,字段类型,范式与逆范式
功能:索引,缓存,分区分表。
架构:主从复制,读写分离,负载均衡。
合理SQL:测试,经验。
然而每个大的方向中又包含多个小的优化点,下面我们具体来看看。
# 优化注意事项:
- 依据数据而不是凭空猜测
- 忌过早优化
- 忌过度优化
- 深入理解业务
- 性能优化是持久战
- 选择合适的衡量指标、测试用例、测试环境
# 优化目标
- 减少 IO 次数,IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当然,也是收效最明显的优化手段。
- 降低 CPU 计算,除了 IO 瓶颈之外,SQL优化中需要考虑的就是 CPU 运算量的优化了。order by, group by,distinct … 都是消耗 CPU 的大户(这些操作基本上都是 CPU 处理内存中的数据比较运算)。当我们的 IO 优化做到一定阶段之后,降低 CPU 计算也就成为了我们 SQL 优化的重要目标
# 优化方案一: SQL 和索引优化
使用正确的索引,索引是数据库中最重要的概念之一,也是提高数据库性能最有效的手段之一,它的诞生本身就是为了提高数据查询效率的,就像字典的目录一样,通过目录可以很快找到相关的内容。我们应该尽可能的使用主键查询,而非其他索引查询,因为主键查询不会触发回表查询,因此节省了一部分时间,变相的提高了查询的性能。
索引类型:普通索引、主键索引、唯一索引、组合索引、全文索引,假如我们没有添加索引,那么在查询时就会触发全表扫描,因此查询的数据就会很多,并且查询效率会很低,为了提高查询的性能,我们就需要给最常使用的查询字段上,添加相应的索引,这样才能提高查询的性能
sql书写时的注意
在 MySQL 5.0 之前的版本要尽量避免使用 or 查询,可以使用 union 或者子查询来替代,因为早期的 MySQL 版本使用 or 查询可能会导致索引失效,在 MySQL 5.0 之后的版本中引入了索引合并,简单来说就是把多条件查询,比如 or 或 and 查询的结果集进行合并交集或并集的功能,因此就不会导致索引失效的问题了。如果限制条件中其他字段没有索引,尽量少用or。
避免在 where 查询条件中使用 != 或者 <> 操作符,因为这些操作符会导致查询引擎放弃索引而进行全表扫描。
适当使用前缀索引,MySQL 是支持前缀索引的,也就是说我们可以定义字符串的一部分来作为索引。我们知道索引越长占用的磁盘空间就越大,那么在相同数据页中能放下的索引值也就越少,这就意味着搜索索引需要的查询时间也就越长,进而查询的效率就会降低,所以我们可以适当的选择使用前缀索引,以减少空间的占用和提高查询效率。
要尽量避免使用 select *,而是查询需要的字段,这样可以提升速度,以及减少网络传输的带宽压力。
关于JOIN优化,尽量使用 Join 语句来替代子查询,因为子查询是嵌套查询,而嵌套查询会新创建一张临时表,而临时表的创建与销毁会占用一定的系统资源以及花费一定的时间,但 Join 语句并不会创建临时表,因此性能会更高。
我们要尽量使用小表驱动大表的方式进行查询,也就是如果 B 表的数据小于 A 表的数据,那执行的顺序就是先查 B 表再查 A 表。
不要在列字段上进行算术运算或其他表达式运算,否则可能会导致查询引擎无法正确使用索引,从而影响了查询的效率。
增加冗余字段可以减少大量的连表查询,因为多张表的连表查询性能很低,所有可以适当的增加冗余字段,以减少多张表的关联查询,这是以空间换时间的优化策略。
避免类型转换,这里所说的“类型转换”是指 where 子句中出现 column 字段的类型和传入的参数类型不一致的时候发生的类型转换。
尽量用 union all 代替 union,union 和 union all 的差异主要是前者需要将两个(或者多个)结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的 CPU 运算,加大资源消耗及延迟。所以当我们可以确认不可能出现重复结果集或者不在乎重复结果集的时候,尽量使用 union all 而不是 union。
尽量少排序 order by,排序操作会消耗较多的 CPU 资源,所以减少排序可以在缓存命中率高等 IO 能力足够的场景下会较大影响 SQL 的响应时间。如果排序字段没有用到索引,就尽量少排序。
SQL语句中IN包含的值不应过多,MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗也是比较大的。
当只需要一条数据的时候,使用limit 1,这是为了使EXPLAIN中type列达到const类型。
区分in和exists, not in和not exists。
使用合理的分页方式以提高分页的效率。
分段查询
避免在 where 子句中对字段进行 null 值判断
不建议使用%前缀模糊查询,如果使用%前缀来模糊查询,建议使用全文索引。
对于联合索引来说,要遵守最左前缀法则。比如:组合索引(a,b,c)三列,我们可以使用(a),(a,b),(a,b,c),(a,c<默认走a,不走c>),(c,b,a),(c,a),但是不能以(c,b),(b,c),(b),©等组合使用否则导致索引失效。
必要时可以使用force index来强制查询走某个索引。
以上这些优化方案我们都可以通过EXPLAIN方式来验证。
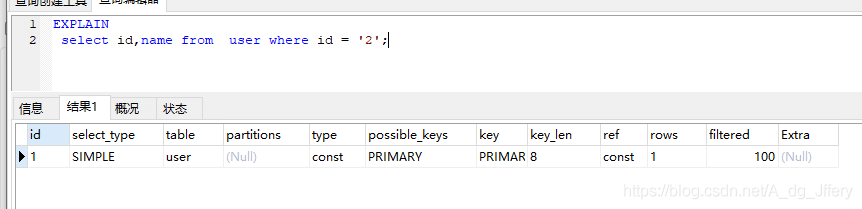
# EXPLAIN各个字段详介绍:
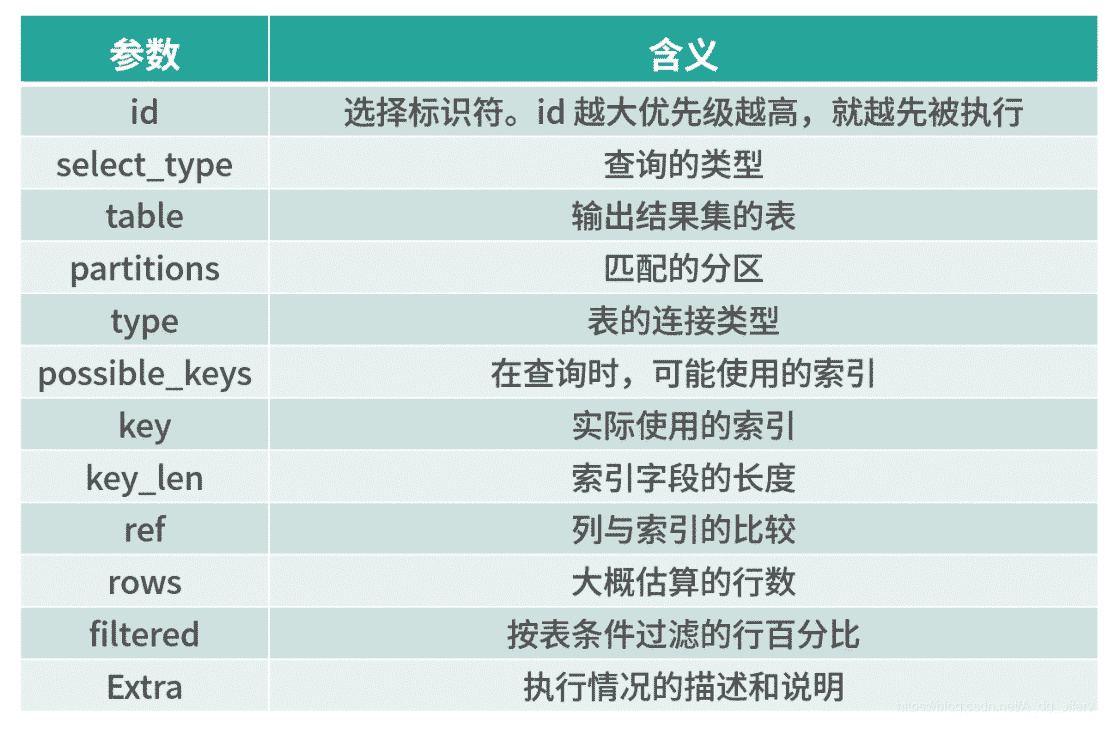
# type字段值如下:
# 优化方案二:数据库结构优化
# ① 最小数据长度
一般说来数据库的表越小,那么它的查询速度就越快,因此为了提高表的效率,应该将表的字段设置的尽可能小,比如身份证号,可以设置为 char(18) 就不要设置为 varchar(18)。
# ② 使用最简单数据类型
能使用 int 类型就不要使用 varchar 类型,因为 int 类型比 varchar 类型的查询效率更高。
# ③ 尽量少定义 text 类型
text 类型的查询效率很低,如果必须要使用 text 定义字段,可以把此字段分离成子表,需要查询此字段时使用联合查询,这样可以提高主表的查询效率。
# ④ 选择合适的存储引擎
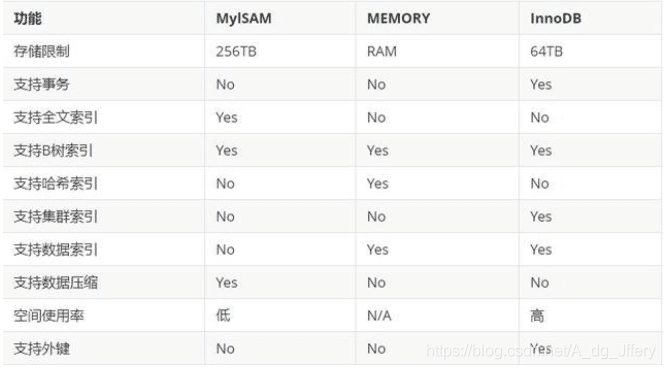
存储引擎类型:MyISAM、InnoDB、MEMORY、MERGE、TokuDB、CSV、Archive等。
MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择该存储引擎是非常合适的。MyISAM是在Web、数据仓库和其他应用环境下最常使用的存储引擎之一。
InnoDB:用于事务处理应用程序,支持外键。如果应用程序对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询外,还包括很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。InnoDB存储引擎除了有效地降低由于删除和更新导致地锁定,还可以确保事务地完整提交(Commit)和回滚(Rollback),对于类似计费系统或者财务系统等对数据准确性要求较高地系统,InnoDB都是合适地选择。
MEMORY:将所有数据保存在RAM中,在需要快速定位记录和其他类似数据的环境下,可提供极快的访问。MEMORY的缺陷是对表的大小有限制,太大的表无法缓存在内存中,其次是要确保表的数据可以恢复,数据库异常终止后表中的数据是可以恢复的。MEMORY表通常用于更新不太频繁的小表,用以快速访问结果。
MERGE:用于将一系列等同地MyISAM表以逻辑方式组合在一起,并作为一个对象引用它们,MERGE表地优点在于可以突破对单个MyISAM表大小的限制,并且通过将不同的表分布在多个磁盘上,可以有效地改善MERGE表的访问效率,这对于诸如数据仓库等VLDB环境十分适合。属于第三方存储引擎 ,高写性能高压缩率,支持事务处理的MySQL和MariaDB的存储引擎,支持大多数在线DDL操作。
TokuDB:使用Fractal树索引保证高效的插入性能;优秀的压缩特性,比InnoDB高近10倍;Hot Schema Changes特性支持在线创建索引和添加、删除属性列等DDL操作。使用Bulk Loader达到快速加载大量数据;提供了主从延迟消除技术;支持ACID和MVCC。
# 三种常见的存储引擎对比:
⑤ 适当分表、分库策略
分表和分库方案也是我们经常说的垂直分隔(分表)和水平分隔(分库)。
分表是指当一张表中的字段更多时,可以尝试将一张大表拆分为多张子表,把使用比较高频的主信息放入主表中,其他的放入子表,这样我们大部分查询只需要查询字段更少的主表就可以完成了,从而有效的提高了查询的效率。
分库是指将一个数据库分为多个数据库。比如我们把一个数据库拆分为了多个数据库,一个主数据库用于写入和修改数据,其他的用于同步主数据并提供给客户端查询,这样就把一个库的读和写的压力,分摊给了多个库,从而提高了数据库整体的运行效率。
# 优化方案三: 系统硬件优化
MySQL 对硬件的要求主要体现在三个方面:磁盘、网络和内存。
# ① 磁盘
磁盘寻道能力(磁盘I/O),以目前高转速SCSI硬盘(7200转/秒)为例,这种硬盘理论上每秒寻道7200次,这是物理特性决定的,没有办法改变;磁盘应该尽量使用有高性能读写能力的磁盘,比如固态硬盘,这样就可以减少 I/O 运行的时间,从而提高了 MySQL 整体的运行效率。 磁盘也可以尽量使用多个小磁盘而不是一个大磁盘,因为磁盘的转速是固定的,有多个小磁盘就相当于拥有多个并行运行的磁盘一样。
# ② 网络
保证网络宽带的通畅(低延迟)以及够大的网络带宽是 MySQL 正常运行的基本条件,如果条件允许的话也可以设置多个网卡,以提高网络高峰期 MySQL 服务器的运行效率。 DNS配置 尽量使用skip-name-resolve来减少因解析带来的不必要麻烦. 检查网络的ping 丢包率.。 通过优化/etc/sysctl.cnf 中的网络参数,提升性能。
# ③ 内存
MySQL 服务器的内存越大,那么存储和缓存的信息也就越多,而内存的性能是非常高的,从而提高了整个 MySQL 的运行效率。
知识扩展: 慢查询:慢查询通常的排查手段是先使用慢查询日志功能,查询出比较慢的 SQL 语句,然后再通过 explain 来查询 SQL 语句的执行计划,最后分析并定位出问题的根源,再进行处理(上文中有介绍到)。
慢查询日志指的是在 MySQL 中可以通过配置来开启慢查询日志的记录功能,超过 long_query_time 值的 SQL 将会被记录在日志中。我们可以通过设置“slow_query_log=1”来开启慢查询,它的开启方式有两种:
通过 MySQL 命令行的模式进行开启,只需要执行“set global slow_query_log=1”即可,然而这种配置模式再重启 MySQL 服务之后就会失效; 另一种方式可通过修改 MySQL 配置文件的方式进行开启,我们需要配置 my.cnf 中的“slow_query_log=1”即可,并且可以通过设置“slow_query_log_file=/tmp/mysql_slow.log”来配置慢查询日志的存储目录,但这种方式配置完成之后需要重启 MySQL 服务器才可生效。 需要注意的是,在开启慢日志功能之后,会对 MySQL 的性能造成一定的影响,因此在生产环境中要慎用此功能。
# 参考文章
- https://blog.csdn.net/A_dg_Jffery/article/details/106001536
← MySQL-触发器案例 索引设计优化 →










