MySQL-并集、交集、差集
更新时间
浏览
TIP
本文主要是介绍 MySQL-并集、交集、差集 。
# MySQL 并集、交集、差集
# 创建两个表
CREATE TABLE `object_a` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`oname` varchar(50) DEFAULT NULL,
`odesc` varchar(50) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=latin1
# 添加数据
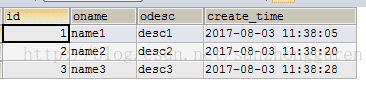
CREATE TABLE `object_b` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`oname` varchar(50) DEFAULT NULL,
`odesc` varchar(50) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=latin1
# 添加数据
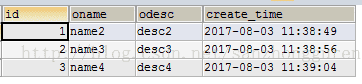
# 连接查询并集、交集、差集
# 查询并集(union all) 不剔重
SELECT oname,odesc FROM object_a
UNION ALL
SELECT oname,odesc FROM object_b
结果如下

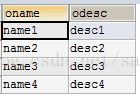
# 查询并集(union) 数据剔重
SELECT oname,odesc FROM object_a
UNION
SELECT oname,odesc FROM object_b
结果如下
PS:union自带去重
# 查询交集
SELECT a.oname,a.odesc FROM object_a a INNER JOIN object_b b ON a.oname=b.oname AND a.odesc=b.odesc
等价于
SELECT a.oname,a.odesc FROM object_a a INNER JOIN object_b b USING(oname,odesc)
结果如下

PS:别的数据库可以试试这种写法(比如Oracle)
SELECT oname,odesc FROM object_a
INTERSECT
SELECT oname,odesc FROM object_b
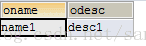
# 查询差集
SELECT a.oname, a.odesc
FROM
object_a a
LEFT JOIN object_b b
ON a.oname = b.oname
AND a.odesc = b.odesc
WHERE b.id IS NULL
PS:上面的SQL中where条件后面不要增加b.某个字段=具体数值,这样相当于把所有为NULL的数据过滤掉了,差集结果为空。千万注意。
结果如下
PS:别的数据库可以试试这种写法
SELECT a.oname, a.odesc FROM object_a a
MINUS
SELECT b.oname, b.odesc FROM object_b b
# 【----------------------------】
# MySQL并集、交集、差集
# 测试数据:
test01
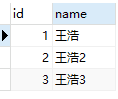
test02
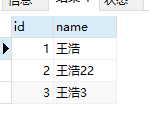
# 一、并集
使用UNION ALL关键字
UNION ALL (并集 不去重)
select * from test01
UNION ALL
select * from test02
结果如下,六条数据全部累积起来了,并且有重复的。
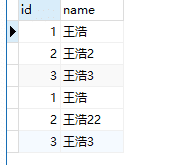
UNION (并集 去重)
select * from test01
UNION
select * from test02
结果如下,可以跟上面的对比少了两条,王浩与王浩3
# 二、交集
-- INNER JOIN (等值连接) 只返回两个表中联结字段相等的行
-- inner join并不以谁为基础,它只显示符合条件的记录.
SELECT a.*
FROM test01 a
INNER JOIN test02 b
ON a.id=b.id AND a.name=b.name;
-- USING(id,name) 等价于 on后面的条件
SELECT a.* FROM test01 a
INNER JOIN test02 b USING(id,name)
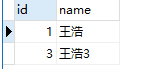
# 三、差集
-- 差集
SELECT a.*
FROM
test01 a
LEFT JOIN test02 b
ON a.id=b.id AND a.name=b.name
WHERE b.id IS NULL

# 【----------------------------】
# MYSQL 交集 差集 并集
# 一 MYSQL
只有并集没有交集差集的关键字
# 二 表结构
a b
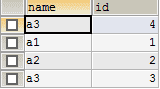
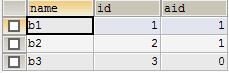
# 三 并集
# 3.1 UNION 不包含重复数据
SELECT NAME FROM a UNION
SELECT NAME FROM b;
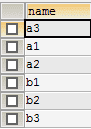
# 3.2 UNION ALL 包含重复数据
# 四 差集
找出在a表中存在的id 但是在b表中不存在的id
# 4.1 : 利用 union
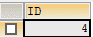
SELECT ID FROM (
-- 并集
SELECT DISTINCT a.id AS ID FROM a
UNION ALL
SELECT DISTINCT B.ID AS ID FROM b
)TEMP GROUP BY ID HAVING COUNT(ID) = 1;
# 4.2 :子查询 not in
SELECT id FROM a WHERE id NOT IN (SELECT id FROM b);
# 4.3 : 子查询 not exists
SELECT id FROM a WHERE NOT EXISTS (SELECT id FROM b WHERE a.id = b.id);
# 4.4 :左连接判断右表IS NULL
SELECT a.id FROM a LEFT JOIN b ON a.id = b.id WHERE b.id IS NULL ORDER BY a.id
# 五 交集 INTERSECT :
SELECT ID FROM (
-- 并集
SELECT DISTINCT a.id AS ID FROM a
UNION ALL
SELECT DISTINCT B.ID AS ID FROM b
)TEMP GROUP BY ID HAVING COUNT(ID) != 1;
# 参考文章
- https://www.cnblogs.com/ssrs-wanghao/articles/11587641.html
- https://blog.csdn.net/sanzhongguren/article/details/76615464
- https://blog.csdn.net/mikefei007/article/details/53888100/










