TIP
本文主要是介绍 SpringBoot-JPA案例 。
最近在项目中使用了一下jpa,发现还是挺好用的。这里就来讲一下jpa以及在spring boot中的使用。 在这里我们先来了解一下jpa。
# 1.什么是jpa呢?
JPA顾名思义就是Java Persistence API的意思,是JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
# 2.jpa具有什么优势?
- 2.1标准化:JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能够在不同的JPA框架下运行。
- 2.2容器级特性的支持:JPA框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的局限,在企业应用发挥更大的作用。
- 2.3简单方便:JPA的主要目标之一就是提供更加简单的编程模型:在JPA框架下创建实体和创建Java 类一样简单,没有任何的约束和限制,只需要使用 javax.persistence.Entity进行注释,JPA的框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。JPA基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成。
- 2.4查询能力:JPA的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是Hibernate HQL的等价物。JPA定义了独特的JPQL(Java Persistence Query Language),JPQL是EJB QL的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
- 2.4高级特性:JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性在关系数据库的持久化。
# 3.基于注解的使用
本篇只介绍注解的使用,另一种基于xml方式的使用大家有兴趣可以自行了解一下。
# 3.1 JPA拥有哪些注解呢?
| 注解 | 解释 |
|---|---|
| @Entity | 声明类为实体或表。 |
| @Table | 声明表名。 |
| @Basic | 指定非约束明确的各个字段。 |
| @Embedded | 指定类或它的值是一个可嵌入的类的实例的实体的属性。 |
| @Id | 指定的类的属性,用于识别(一个表中的主键)。 |
| @GeneratedValue | 指定如何标识属性可以被初始化,例如自动、手动、或从序列表中获得的值。 |
| @Transient | 指定的属性,它是不持久的,即:该值永远不会存储在数据库中。 |
| @Column | 指定持久属性栏属性。 |
| @SequenceGenerator | 指定在@GeneratedValue注解中指定的属性的值。它创建了一个序列。 |
| @TableGenerator | 指定在@GeneratedValue批注指定属性的值发生器。它创造了的值生成的表。 |
| @AccessType | 这种类型的注释用于设置访问类型。如果设置@AccessType(FIELD),则可以直接访问变量并且不需要getter和setter,但必须为public。如果设置@AccessType(PROPERTY),通过getter和setter方法访问Entity的变量。 |
| @JoinColumn | 指定一个实体组织或实体的集合。这是用在多对一和一对多关联。 |
| @UniqueConstraint | 指定的字段和用于主要或辅助表的唯一约束。 |
| @ColumnResult | 参考使用select子句的SQL查询中的列名。 |
| @ManyToMany | 定义了连接表之间的多对多一对多的关系。 |
| @ManyToOne | 定义了连接表之间的多对一的关系。 |
| @OneToMany | 定义了连接表之间存在一个一对多的关系。 |
| @OneToOne | 定义了连接表之间有一个一对一的关系。 |
| @NamedQueries | 指定命名查询的列表。 |
| @NamedQuery | 指定使用静态名称的查询。 |
了解了注解之后我们来看看如何使用吧
# 4.代码实战
# 4.1maven依赖
添加jpa起步依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>1234
# 4.2配置文件
在application.yml文件中添加如下配置
spring:
datasource:
url: jdbc:mysql://localhost:3306/mytest
type: com.alibaba.druid.pool.DruidDataSource
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver //驱动
jpa:
hibernate:
ddl-auto: update //自动更新
show-sql: true //日志中显示sql语句1234567891011
jpa.hibernate.ddl-auto是hibernate的配置属性,其主要作用是:自动创建、更新、验证数据库表结构。该参数的几种配置如下:
·create:每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。
·create-drop:每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。
·update:最常用的属性,第一次加载hibernate时根据model类会自动建立起表的结构(前提是先建立好数据库),以后加载hibernate时根据model类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。要注意的是当部署到服务器后,表结构是不会被马上建立起来的,是要等应用第一次运行起来后才会。
·validate:每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。
以上我们完成了基本的配置工作,记下来看一下如何进行表与实体的映射,以及数据访问接口。
# 4.3创建实体以及数据访问接口
首先来看一下实体类Person.java
@Entity
@Getter
@Setter
public class Person {
@Id
@GeneratedValue
private Long id;
@Column(name = "name", nullable = true, length = 20)
private String name;
@Column(name = "agee", nullable = true, length = 4)
private int age;
}
接着是PersonRepository.java,改接口只需要继承JpaRepository接口即可。
public interface PersonRepository extends JpaRepository<Person, Long> {
}
然后写一个rest接口以供测试使用。
@RestController
@RequestMapping(value = "person")
public class PerconController {
@Autowired
private PersonRepository personRepository;
@PostMapping(path = "addPerson")
public void addPerson(Person person) {
personRepository.save(person);
}
@DeleteMapping(path = "deletePerson")
public void deletePerson(Long id) {
personRepository.delete(id);
}
}
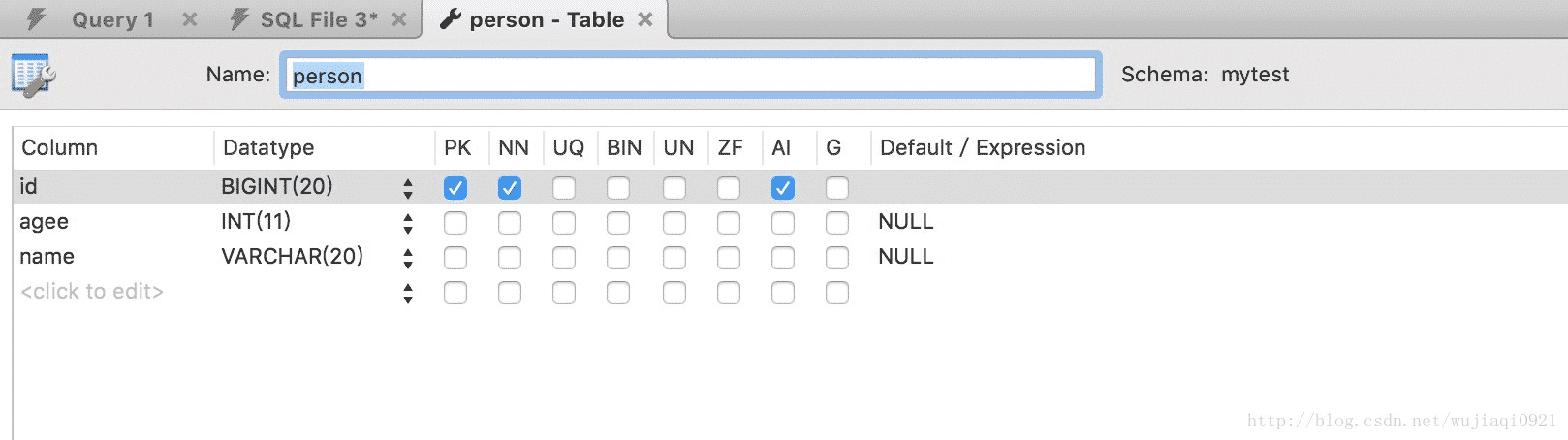
好了,让我们来运行一下程序看看结果吧,启动程序,查询数据库我们就可以看到,JPA以及自动帮我们创建了表
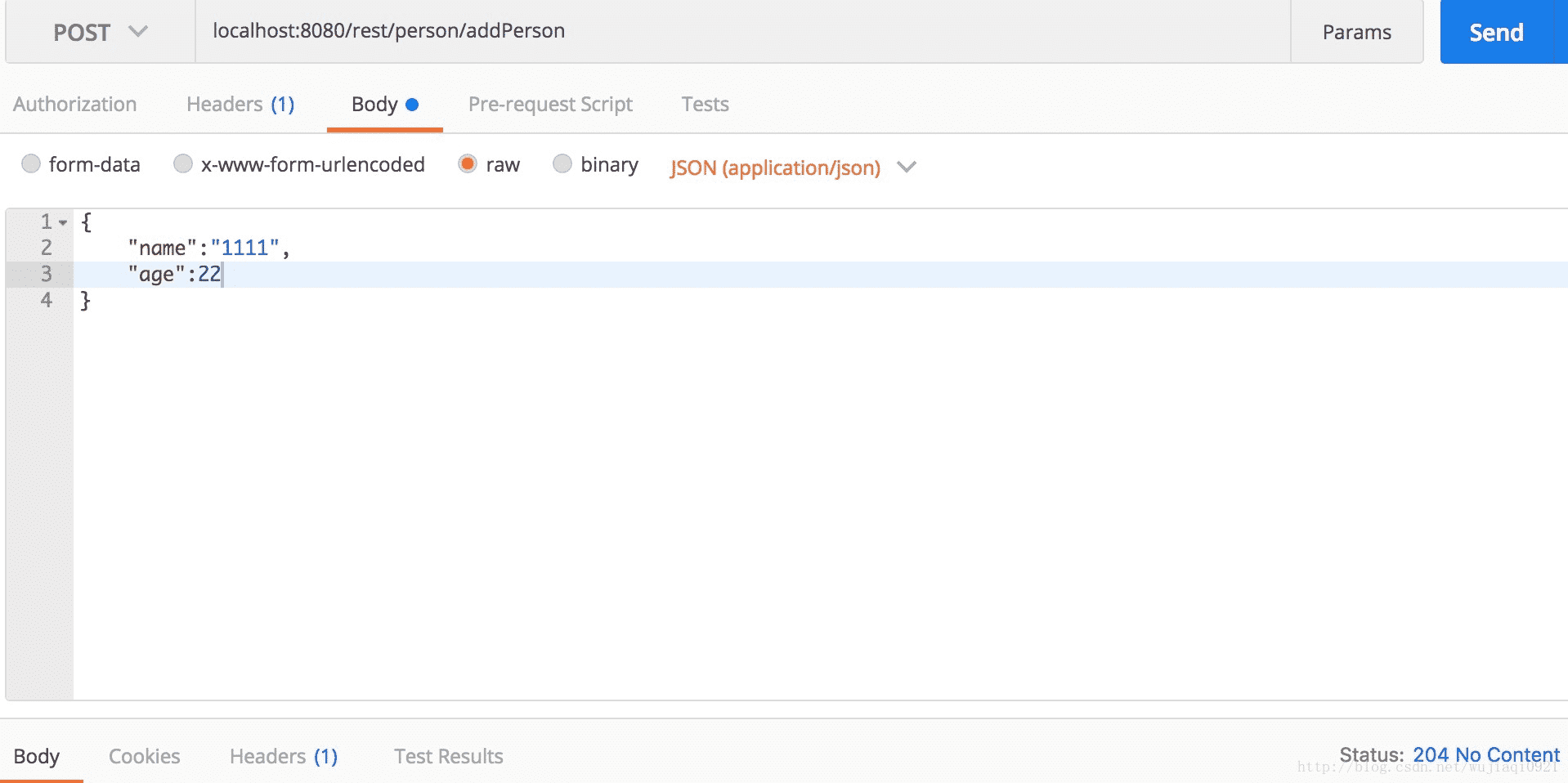
接下来我们调用一下addPerson接口。我们使用postman来测试:
然后通过查询数据库来看一下结果:
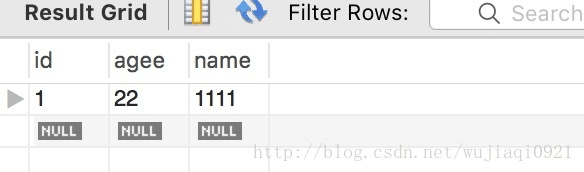
我们可以看到成功插入了数据,并且观察表结构可以看到,agee是我们定义的column名称,id为自增。并且从上面的repository接口代码我们可以看到,接口中并没有定义任何的方法,这是因为JpaRepository中帮我们定义了基础的增删改查方法,可以很方便的直接使用。
接下来我们来看一下如何编写自己的方法。我们以根据name查询person为例。添加一个rest接口
@GET
@Produces(TYPE_JSON)
@Path("getPerson")
public Object getPerson(@QueryParam("name") String name) {
return personRepository.findByName(name);
}
并在repository接口中添加如下查询方法:
Person findByName(String name);1
重启之后让我们来看一下查询结果

我们可以看到通过name获取到了想要的结果。我们也可以在日志中看到hibernate输出的日志:
Hibernate: select person0_.id as id1_0_, person0_.agee as agee2_0_, person0_.name as name3_0_ from person person0_ where person0_.name=?1
那么JPA是通过什么规则来根据方法名生成sql语句查询的呢? 其实JPA在这里遵循Convention over configuration(约定大约配置)的原则,遵循spring 以及JPQL定义的方法命名。Spring提供了一套可以通过命名规则进行查询构建的机制。这套机制会把方法名首先过滤一些关键字,比如 find…By, read…By, query…By, count…By 和 get…By 。系统会根据关键字将命名解析成2个子语句,第一个 By 是区分这两个子语句的关键词。这个 By 之前的子语句是查询子语句(指明返回要查询的对象),后面的部分是条件子语句。如果直接就是 findBy… 返回的就是定义Respository时指定的领域对象集合,同时JPQL中也定义了丰富的关键字:and、or、Between等等,下面我们来看一下JPQL中有哪些关键字:
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
| …… |
以上就是jpa的简单实用和介绍。
# 参考文章
- https://blog.csdn.net/wujiaqi0921/article/details/78789087










