TIP
本文主要是介绍 Spark-RDD模型介绍 。
本篇文章主要是介绍什么RDD、RDD的5个特性和RDD的特征。
# 1.RDD是什么
RDD是Resilient Distributed Dataset。 RDD是Spark的基础数据结构。表现形式为不可变的分区元素的集合,并且可以在集群中并行操作。
# RDD解析
- Resilient(弹性):在DAG的帮助下,具有容错性。即在节点故障导致丢失或者损坏分区,可以重新计算数据。
- Distributed:数据存储在多个节点上。
- Dataset:要处理的数据集。用户可以在外部数据源获取数据,这些数据源可以JSON文件、CSV文件、文本文件获取通过JDBC的形式获取数据库中没有特定数据结构的数据。
# RDD的5特属性
- 获取分区列表(getPartitions):有一个数据分片列表,能够将数据进行切分,切分后的数据能够进行并行计算,是数据集的原子组成部分。
- 可以在每一个分区上进行计算(compute):计算每个分区,得到一个可便利的结果,用于说明在父RDD上执行何种计算。
- 获取每个RDD的依赖(getDependencies):计算每个RDD对父RDD的依赖列表,源RDD没有依赖,通过依赖关系描述血统。
- RDD的键值分区器( @transient val partitioner: Option[Partitioner] = None):描述分区模式和数据存放的位置,键值对的RDD根据哈希值进行分区。
- 在那个分区上进行计算最好(getPreferredLocations):每一个分片的优先计算位置。
RDD中的数据集是按照逻辑分不到集群中的节点上,这样可以在各个节点上并行计算。RDD具有容错性,在失败的情况下,可以自动恢复。
RDD可以被缓存,并且可以手动分区。
开发人员可以将需要再次使用的RDD进行持久化。Spark是默认将数据持久化到内存中,如果内存不足,会将数据写入到磁盘上。用户可以自定义持久化方式。
# 2.为什么需要RDD
提出RDD的动机有:
- 迭代计算。
- 交互式的数据挖掘工具。
- DSM(Distributed Shared Memory)是一个通用的抽象,这种通用性使得在集群上高效执行和容错性变得更难。
RDD具有容错性,这是因为RDD是基于coarse-grained transformation而不是fine-grained updates来更新状态。
RDD是lazy的,在需要的时候,这样可以节省很多时间并提高效率。
# 3.RDD vs DSM
| RDD | DSM | |
|---|---|---|
| Read | RDD的读操作可以是粗力度,也可以是细粒度。 粗粒度是对整个数据集进行转换操作,而不是针对数据集中的每一个元素。 细粒度是针对数据集中的每一个元素进行转换操作。 | DSM中的转换操作是细粒度的。 |
| Write | RDD的写入是粗粒度 | DSM的写操作是细粒度 |
| Consistency | RDD的数据是不可变的 | 如果开发者遵循规则,内存中的数据保持一致,并且内存操作结果是可预测的 |
| Fault-Recovery Mechanism | 丢失的数据可以通过DAG来恢复,RDD的数据都是不可变的,很容易恢复 | 通过checkpoint实现容错,如果出现问题,回到最新的checkpoint |
| Straggler Mitigation | RDD可以用备份任务来解决运行比较慢的任务 | 解决运行慢的任务非常困难 |
| Behavior if not enough RAM | RDD的数据比较多,在内存中存储不了,将多余数据写入磁盘 | DSM中,如果数据量大于内存的最大值,性能下降厉害 |
# 4.RDD的特征
# 4.1 In-memory Computation
Spark RDD具有内存计算功能。RDD将中间的结果存储在内存中,如果内存中存不下的时候,将数据放在磁盘上。
# 4.2 Lazy Evaluations
Spark的所有转换操作都是Lazy的,如果遇到action操作时,才会执行之前的操作。
# 4.3 Fault Tolerance
Spark RDD具有容错能力。如果碰到故障时,RDD可以根据追踪数据的依赖关系,来重新生成丢失的数据。
# 4.4 Immutability
RDD中的数据都是不可变的,可以在进程之间共享使用。
# 4.5 Partitioning
分区是RDD并行计算的基本单元。每个分区都是一个可变数据的逻辑分区。在现有分区的基础上可以通过一些转换操作生成新的分区。
# 4.6 Coarse-grained Operations
将一个方法作用于数据集中的每一个元素。
# 4.7 Location-Stickiness
RDD可以定义计算分区的放置首选项。DAG Scheduler将尽量任务放到数据所在的节点上。
# 4.8 Persistence
RDD可以根据需要不同,选择相应的存储策略。
# 5.RDD Operation
# 5.1 Transformations
RDD的转换操作都是lazy的,分为两种narrow transformation, wide transformation。
# 5.1.1 Narrow Transformations(窄依赖)
在单个分区中计算记录所需的所有元素都存在父RDD的单个分区中。 map、flatMap、MapPartition、filter、Sample、Union操作的结果就是Narrow transformation。
一个父RDD的partition至少会被子RDD的某个partition使用一次。就是一个父类RDD的一个分区不可能对应一个子RDD的多个分区。
# 5.1.2 Wide transformation(宽依赖)
在单个分区中计算记录所需的所有元素都存在父RDD的多个分区中。 intersection、distinct、reduceByKey、GroupByKey、join、Cartesian、repartition、colaesce操作的结果是Wide transformation。
一个父RDD的partition会被子RDD的partition使用多次。就是一个父RDD的一个分区对应一个子RDD的多个分区。
Join操作:窄依赖,两个数据集使用相同的分区器;宽依赖,使用不同的分区器。
可以使用toDebugString,看到RDD的线性信息,如果出现ShuffleDependency,就是发生shuffle操作。
# 5.1.3依赖关系说明
窄依赖的RDd可以通过相同的键进行联合分区,整个操作都可以在一个集群节点上进行,以流水线的方式计算所有父分区,不会造成网络之间的数据混合。
宽依赖RDD涉及数据混合,宽依赖需要首先计算好所有父分区数据,然后在节点直接进行shuffle。
窄依赖能够更有效的进行失效节点的恢复,重新计算丢失RDD分区的父分区,不同节点之间可以并行计算; 对一个宽窄依赖的血统图,单个节点失效可能导致这个RDD的所有祖先丢失部分数据,因而需要整体重新计算(Shuffle执行时固化操作,以及采取persist缓存策略,可以在固化点或者缓存点重新计算)。
执行时,调度程序检查依赖性的类型,将窄依赖的RDD划到一组处理当中,即Stage,宽依赖在一个跨越连续的Stage,同时需要显示指定多个子RDD的分区。
可以参考Wide vs Narrow Dependencies (opens new window)
# 6.RDD的局限性
# 6.1 No input optimization engine
RDD没有自动优化的规则,无法使用Spark高级优化器,例如catalyst优化器和Tungsten执行引擎。可以实现手动RDD优化。
在Dataset和DataFrame中不存在这个问题,DataSet和DataFrame可以使用catalyst来产生优化后的逻辑和物理执行计划,这样可以节省空间和提高运行速度。
# 6.2 Runtime type safety
在RDD中没有静态类型和运行时类型安全,并且不允许在运行时检查错误。 Dataset提供了编译时期类型安全来构建复杂数据工作流。
# 6.3 Degrade when not enough memory
在存储RDD时,如果没有足够的内存或者磁盘,将会使得RDD的性能下降特别厉害。
# 6.4 Performance limitation & Overhead of serialization & garbage collection
因为RDD是内存中的JVM对象,这就牵扯到GC和Java序列化,在数据增长时,会需要大量的内存或者磁盘空间。 GC的成本与Java对象是成正比的,使用数据结构比较少的对象可以减少成本,或者将数据持久化。
# 6.5 Handling structured data
RDD不提供数据的schema信息。 Dataset和DataFrame提供了数据的schema信息,可以每一列数据的含义。
# 【----------------------------】
# Spark—RDD介绍
Spark—RDD
# 1、概念介绍
RDD(Resilient Distributed Dataset):弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
官方定义还是比较抽象,个人理解为:它本质就是一个类,屏蔽了底层对数据的复杂抽象和处理,为用户提供了一组方便数据转换和求值的方法。
# 2、RDD特点
# 1)不可变:
弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合
# 2)可分区:
RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同Worker节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)
# 3)弹性:
- 1.存储弹性:内存与磁盘的自动切换
- 2.容错弹性:数据丢失可以自动恢复
- 3.计算弹性:计算出错重试机制
- 4.分片弹性:根据需要重新分片
# 3、在计算数据中RDD都做了什么:
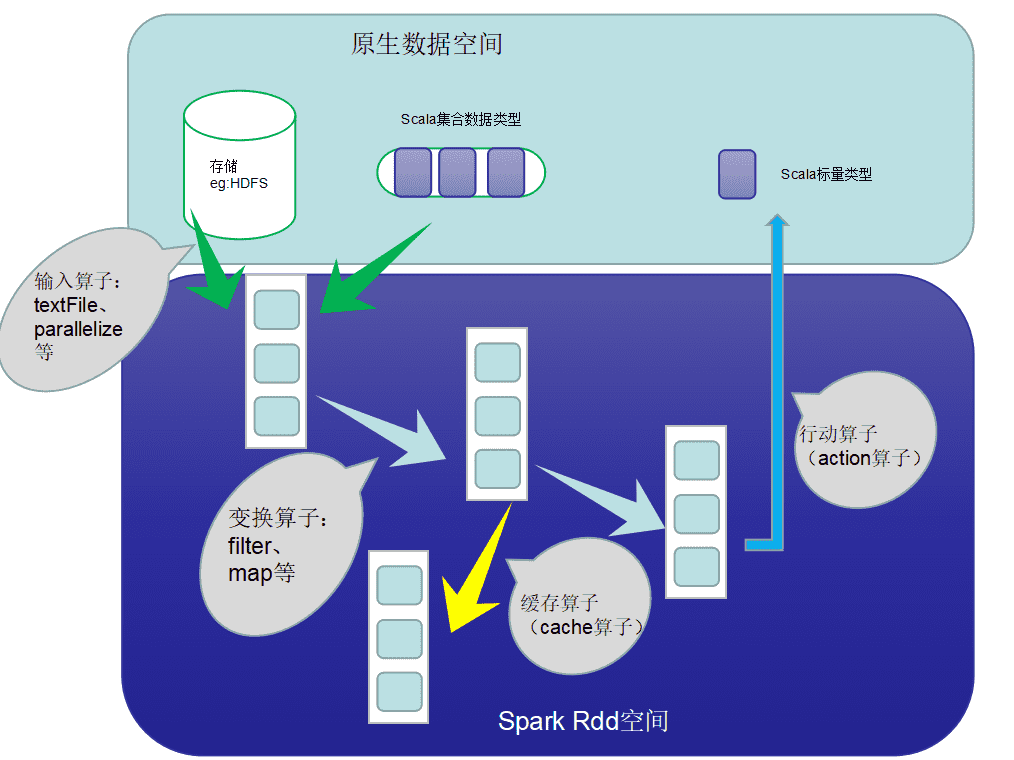
主要流程:
RDD创建——>RDD转换——>RDD缓存——>RDD行动——>RDD的输出
spark计算的核心就在RDD转换、缓存、行动上。
# 4、Spark wordcount 解释RDD

# 参考文章
- https://www.jianshu.com/p/c43cd6a5538d
- https://www.cnblogs.com/jnba/p/10830446.html










