TIP
本文主要是介绍 Flink-集群安装案例 。
# Flink集群搭建
Flink支持多种安装模式。
- local(本地)——单机模式,一般不使用
- standalone——独立模式,Flink自带集群,开发测试环境使用
- yarn——计算资源统一由Hadoop YARN管理,生产环境测试
# Standalone模式
# 步骤
解压flink压缩包到指定目录
配置flink
配置slaves节点
分发flink到各个节点
启动集群
提交WordCount程序测试
查看Flink WebUI
# 具体操作
上传flink压缩包到指定目录
解压缩flink到 /export/servers 目录
tar -xvzf flink-1.6.0-bin-hadoop26-scala_2.11.tgz -C /export/servers
- 使用vi修改 conf/flink-conf.yaml
# 配置Master的机器名(IP地址)
jobmanager.rpc.address: node-1
# 配置每个taskmanager生成的临时文件夹
taskmanager.tmp.dirs: /export/servers/flink-1.6.0/tmp
- 使用vi修改slaves文件
node-1
node-2
node-3
- 使用vi修改 /etc/profile 系统环境变量配置文件,添加HADOOP_CONF_DIR目录
export HADOOP_CONF_DIR=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
- 分发/etc/profile到其他两个节点
scp -r /etc/profile node-2:/etc
scp -r /etc/profile node-3:/etc
- 每个节点重新加载环境变量
source /etc/profile
- 使用scp命令分发flink到其他节点
scp -r /export/servers/flink-1.6.0/ node-2:/export/servers/
scp -r /export/servers/flink-1.6.0/ node-3:/export/servers/
启动Flink集群
启动HDFS集群
在HDFS中创建/test/input目录
hadoop fs -mkdir -p /test/input
- 上传wordcount.txt文件到HDFS /test/input目录
hadoop fs -put /root/wordcount.txt /test/input
- 并运行测试任务
bin/flink run /export/servers/flink-1.6.0/examples/batch/WordCount.jar --input hdfs://node-1:9000/test/input/wordcount.txt --output hdfs://node-1:9000/test/output/result.txt
- 浏览Flink Web UI界面
http://node-1:8081
# Standalone集群架构
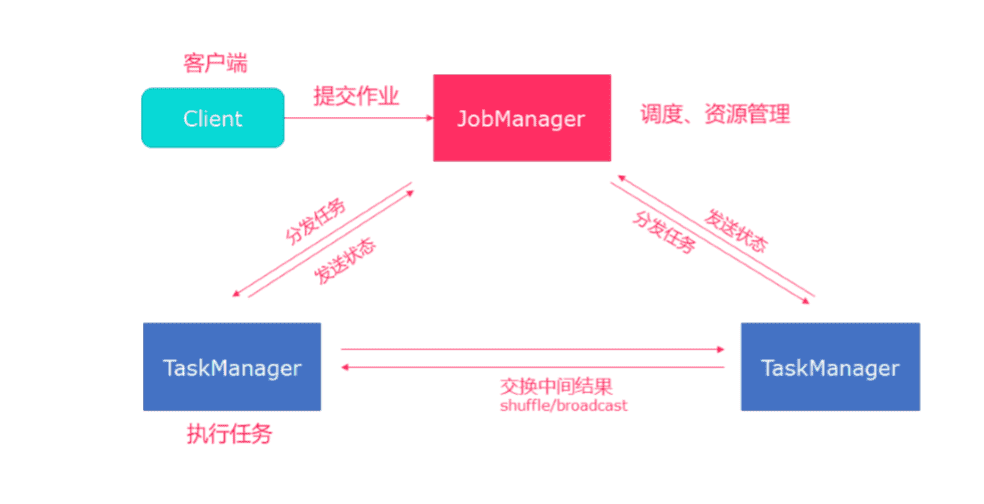
- client客户端提交任务给JobManager
- JobManager负责Flink集群计算资源管理,并分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
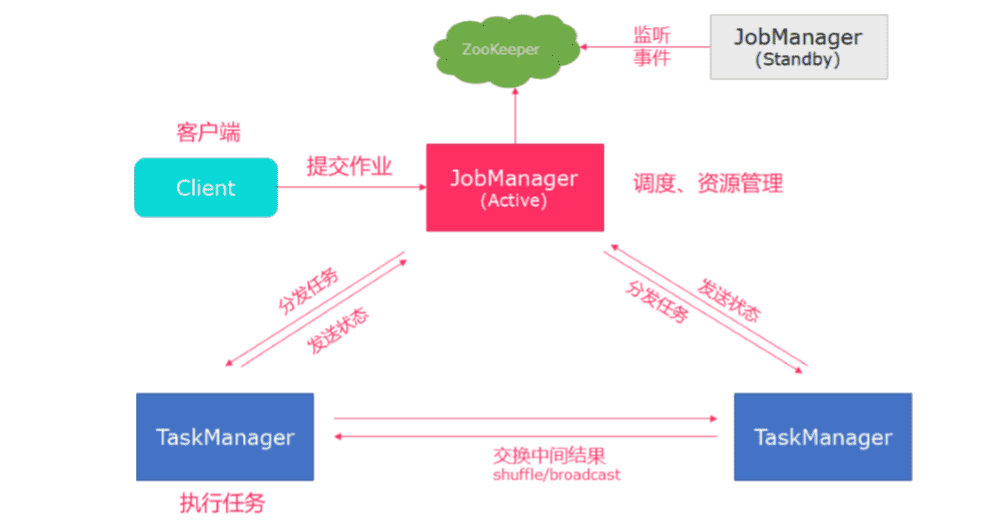
# 高可用HA模式
从上述架构图中,可发现JobManager存在 单点故障 ,一旦JobManager出现意外,整个集群无法工作。所以,为了确 保集群的高可用,需要搭建Flink的HA。(如果是部署在YARN上,部署YARN的HA),我们这里演示如何搭建 Standalone 模式HA。
HA架构图
# 步骤
在flink-conf.yaml中添加zookeeper配置
将配置过的HA的 flink-conf.yaml 分发到另外两个节点
分别到另外两个节点中修改flink-conf.yaml中的配置
在 masters 配置文件中添加多个节点
分发masters配置文件到另外两个节点
启动 zookeeper 集群
启动 flink 集群
# 具体操作
- 在flink-conf.yaml中添加zookeeper配置
#开启HA,使用文件系统作为快照存储
state.backend: filesystem
#启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://node-1:9000/flink-checkpoints
#使用zookeeper搭建高可用
high-availability: zookeeper
# 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://node-1:9000/flink/ha/
high-availability.zookeeper.quorum: node-1:2181,node-2:2181,node-3:2181
- 将配置过的HA的 flink-conf.yaml 分发到另外两个节点
scp -r /export/servers/flink-1.6.0/conf/flink-conf.yaml node-2:/export/servers/flink-1.6.0/conf/
scp -r /export/servers/flink-1.6.0/conf/flink-conf.yaml node-3:/export/servers/flink-1.6.0/conf/
- 到节点2中修改flink-conf.yaml中的配置,将JobManager设置为自己节点的名称
jobmanager.rpc.address: node-2
- 在 masters 配置文件中添加多个节点
node-1:8081
node-2:8082
- 分发masters配置文件到另外两个节点
scp /export/servers/flink-1.6.0/conf/masters node-2:/export/servers/flink-1.6.0/conf/
scp /export/servers/flink-1.6.0/conf/masters node-3:/export/servers/flink-1.6.0/conf/
启动 zookeeper 集群
启动 HDFS 集群
启动 flink 集群
分别查看两个节点的Flink Web UI
kill掉一个节点,查看另外的一个节点的Web UI
# 注意事项
切记搭建HA,需要将第二个节点的 jobmanager.rpc.address 修改为node-2
# YARN模式
在企业中,经常需要将Flink集群部署到YARN,因为可以使用YARN来管理所有计算资源。而且Spark程序也可以部署到 YARN上。
Flink运行在YARN上,可以使用yarn-session来快速提交作业到YARN集群。
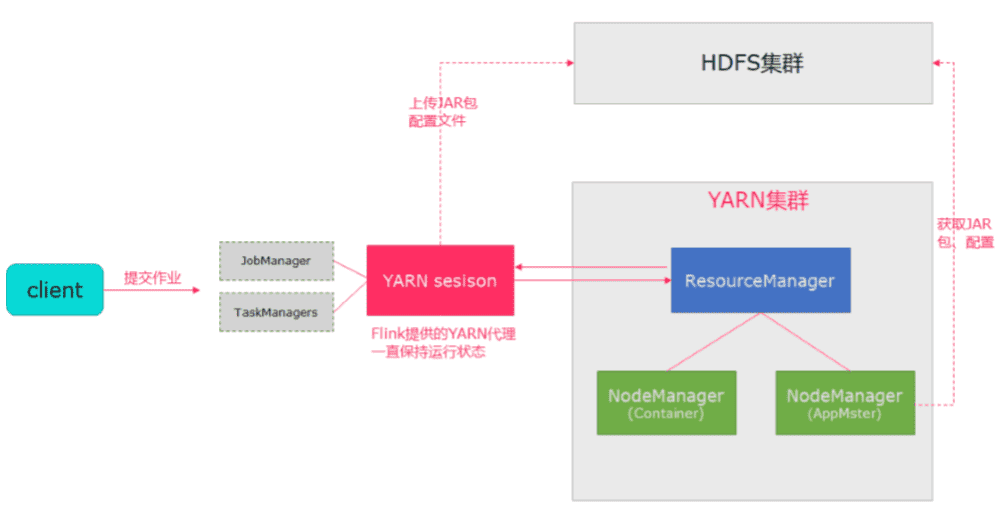
yarn-session提供两种模式
# 1. 会话模式
- 使用Flink中的yarn-session(yarn客户端),会启动两个必要服务 JobManager 和 TaskManagers
- 客户端通过yarn-session提交作业
- yarn-session会一直启动,不停地接收客户端提交的作用
- 有大量的小作业,适合使用这种方式
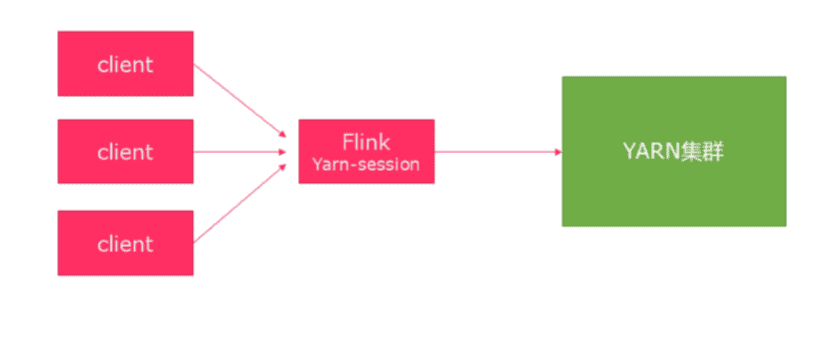
# 2. 分离模式
- 直接提交任务给YARN
- 大作业,适合使用这种方式

# 步骤
- 修改Hadoop的yarn-site.xml,添加该配置表示内存超过分配值,是否将任务杀掉。默认为true。
运行Flink程序,很容易超过分配的内存。
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
启动HDFS、YARN集群
使用yarn-session的模式提交作业
# YARN Session模式
- 在flink目录启动yarn-session
bin``/yarn-session``.sh -n 2 -tm 800 -s 1 -d <br>``# -n 表示申请2个容器, <br># -s 表示每个容器启动多少个slot <br># -tm 表示每个TaskManager申请800M内存 <br># -d 表示以后台程序方式运行
- 使用flink提交任务
bin``/flink` `run examples``/batch/WordCount``.jar
- 如果程序运行完了,可以使用 yarn application -kill application_id 杀掉任务
yarn application -``kill` `application_1554377097889_0002
# 分离模式
- 使用flink直接提交任务
bin``/flink` `run -m yarn-cluster -yn 2 .``/examples/batch/WordCount``.jar``# -yn 表示TaskManager的个数
- 查看WEB UI
# 参考文章
- https://www.cnblogs.com/jifengblog/p/12397887.html










