TIP
本文主要是介绍 Flink-checkPoint和SavePoint区别 。
- Flink检查点(checkpoint)、保存点(savepoint)的区别与联系
- 【----------------------------】
- Flink的Checkpoint和Savepoint介绍
- 第一部分:Flink的Checkpoint
- 1. Flink Checkpoint原理介绍
- 2. Checkpoint的简单设置
- 3. 保存多个Checkpoint
- 4.从Checkpoint进行恢复
- 第二部分: Flink的Savepoint
- 【----------------------------】
- Flink 专题 Checkpoint、Savepoint 机制
- CheckPoint
- Savepoint
- 参考文章
# Flink检查点(checkpoint)、保存点(savepoint)的区别与联系
# checkpoint和savepoint 简述
checkpoint和savepoint是Flink为我们提供的作业快照机制,它们都包含有作业状态的持久化副本。官方文档这样描述checkpoint:
Checkpoints make state in Flink fault tolerant by allowing state and the corresponding stream positions to be recovered, thereby giving the application the same semantics as a failure-free execution.
而对savepoint的描述是:
A Savepoint is a consistent image of the execution state of a streaming job, created via Flink’s checkpointing mechanism. You can use Savepoints to stop-and-resume, fork, or update your Flink jobs.
下面这张来自Flink 1.1版本文档(更新的版本就不见了)的图示出了checkpoint和savepoint的关系。
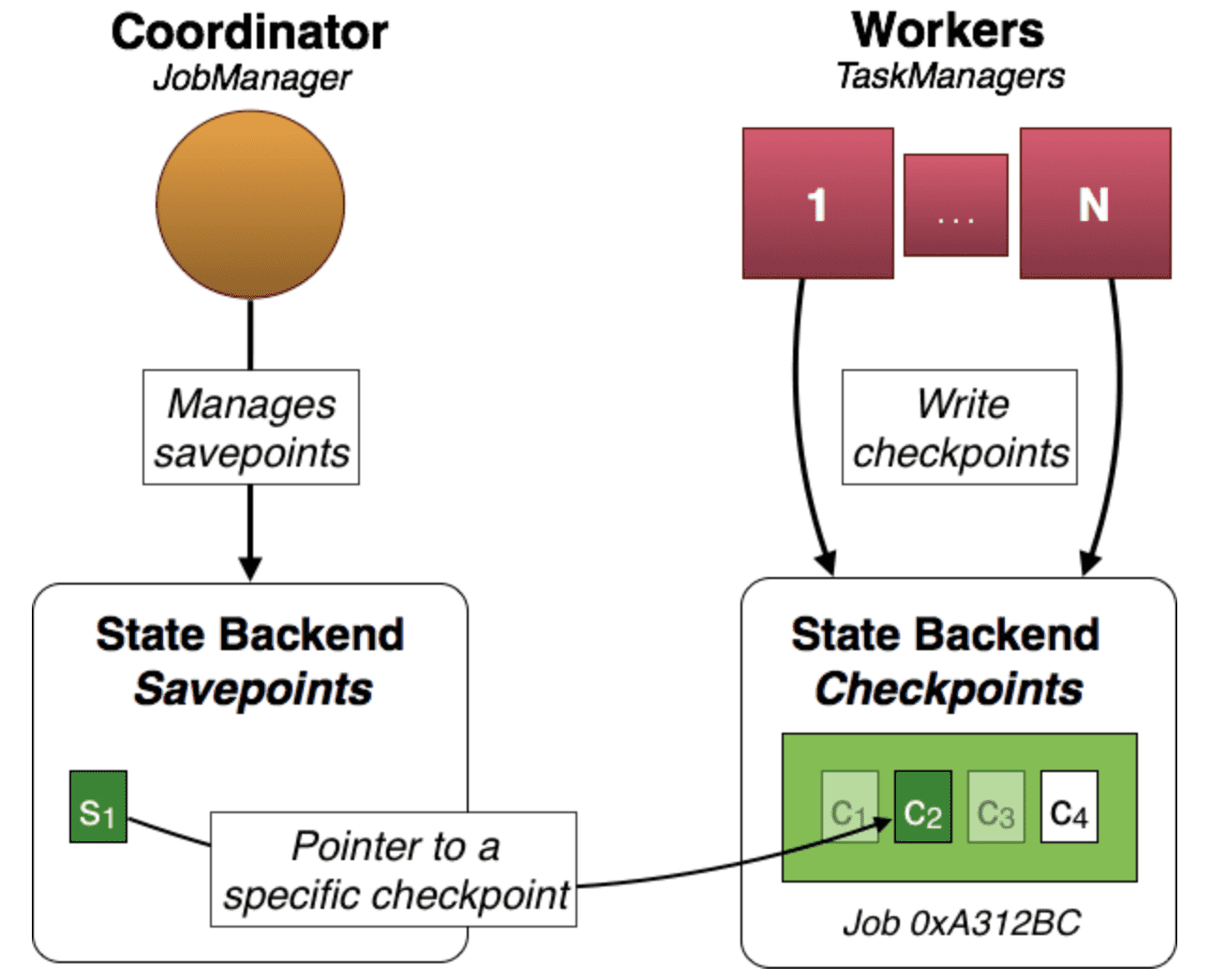
# checkpoint和savepoint区别总结
用几句话总结一下。
- checkpoint的侧重点是“容错”,即Flink作业意外失败并重启之后,能够直接从早先打下的checkpoint恢复运行,且不影响作业逻辑的准确性。而savepoint的侧重点是“维护”,即Flink作业需要在人工干预下手动重启、升级、迁移或A/B测试时,先将状态整体写入可靠存储,维护完毕之后再从savepoint恢复现场。
- savepoint是“通过checkpoint机制”创建的,所以savepoint本质上是特殊的checkpoint。
- checkpoint面向Flink Runtime本身,由Flink的各个TaskManager定时触发快照并自动清理,一般不需要用户干预;savepoint面向用户,完全根据用户的需要触发与清理。
- checkpoint的频率往往比较高(因为需要尽可能保证作业恢复的准确度),所以checkpoint的存储格式非常轻量级,但作为trade-off牺牲了一切可移植(portable)的东西,比如不保证改变并行度和升级的兼容性。savepoint则以二进制形式存储所有状态数据和元数据,执行起来比较慢而且“贵”,但是能够保证portability,如并行度改变或代码升级之后,仍然能正常恢复。
- checkpoint是支持增量的(通过RocksDB),特别是对于超大状态的作业而言可以降低写入成本。savepoint并不会连续自动触发,所以savepoint没有必要支持增量。
# 【----------------------------】
# Flink的Checkpoint和Savepoint介绍
# 第一部分:Flink的Checkpoint
# 1. Flink Checkpoint原理介绍
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator的状态来生成Snapshot,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些Snapshot进行恢复,从而修正因为故障带来的程序数据状态中断。这里,我们简单理解一下Flink Checkpoint机制,如官网下图所示:  [Flink原理介绍第四篇】:Flink的Checkpoint和Savepoint介绍_hxcaifly的博客-CSDN博客_files/2018120113464219.png)
Checkpoint指定触发生成时间间隔后,每当需要触发Checkpoint时,会向Flink程序运行时的多个分布式的Stream Source中插入一个Barrier标记,这些Barrier会根据Stream中的数据记录一起流向下游的各个Operator。当一个Operator接收到一个Barrier时,它会暂停处理Steam中新接收到的数据记录。因为一个Operator可能存在多个输入的Stream,而每个Stream中都会存在对应的Barrier,该Operator要等到所有的输入Stream中的Barrier都到达。当所有Stream中的Barrier都已经到达该Operator,这时所有的Barrier在时间上看来是同一个时刻点(表示已经对齐),在等待所有Barrier到达的过程中,Operator的Buffer中可能已经缓存了一些比Barrier早到达Operator的数据记录(Outgoing Records),这时该Operator会将数据记录(Outgoing Records)发射(Emit)出去,作为下游Operator的输入,最后将Barrier对应Snapshot发射(Emit)出去作为此次Checkpoint的结果数据。
# 2. Checkpoint的简单设置
开启Checkpoint功能,有两种方式。其一是在conf/flink_conf.yaml中做系统设置;其二是针对任务再代码里灵活配置。但是我个人推荐第二种方式,针对当前任务设置,设置代码如下所示:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置保存点的保存路径,这里是保存在hdfs中
env.setStateBackend(new FsStateBackend("hdfs://namenode01.td.com/flink-1.5.3/flink-checkpoints"));
CheckpointConfig config = env.getCheckpointConfig();
// 任务流取消和故障应保留检查点
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 保存点模式:exactly_once
config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 触发保存点的时间间隔
config.setCheckpointInterval(60000);
上面调用enableExternalizedCheckpoints设置为ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION,表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint处理。上面代码配置了执行Checkpointing的时间间隔为1分钟。
# 3. 保存多个Checkpoint
默认情况下,如果设置了Checkpoint选项,则Flink只保留最近成功生成的1个Checkpoint,而当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活,比如,我们发现最近4个小时数据记录处理有问题,希望将整个状态还原到4小时之前。 Flink可以支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,指定最多需要保存Checkpoint的个数:
state.checkpoints.num-retained: 20
这样设置以后,运行Flink Job,并查看对应的Checkpoint在HDFS上存储的文件目录,示例如下所示:
hdfs dfs -ls /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/
Found 22 items
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:23 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-858
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:24 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-859
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:25 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-860
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:26 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-861
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:27 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-862
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:28 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-863
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:29 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-864
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:30 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-865
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:31 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-866
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:32 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-867
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:33 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-868
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:34 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-869
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:35 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-870
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:36 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-871
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:37 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-872
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:38 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-873
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:39 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-874
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:40 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-875
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:41 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-876
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:42 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-877
drwxr-xr-x - hadoop supergroup 0 2018-08-31 20:05 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/shared
drwxr-xr-x - hadoop supergroup 0 2018-08-31 20:05 /flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/taskowned
可见,我们配置了state.checkpoints.num-retained的值为20,只保留了最近的20个Checkpoint。如果希望会退到某个Checkpoint点,只需要指定对应的某个Checkpoint路径即可实现。
# 4.从Checkpoint进行恢复
如果Flink程序异常失败,或者最近一段时间内数据处理错误,我们可以将程序从某一个Checkpoint点,比如chk-860进行回放,执行如下命令:
bin/flink run -s hdfs://namenode01.td.com/flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-860/_metadata flink-app-jobs.jar
程序正常运行后,还会按照Checkpoint配置进行运行,继续生成Checkpoint数据,如下所示:
hdfs dfs -ls /flink-1.5.3/flink-checkpoints/11bbc5d9933e4ff7e25198a760e9792e
Found 6 items
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:56 /flink-1.5.3/flink-checkpoints/11bbc5d9933e4ff7e25198a760e9792e/chk-861
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:57 /flink-1.5.3/flink-checkpoints/11bbc5d9933e4ff7e25198a760e9792e/chk-862
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:58 /flink-1.5.3/flink-checkpoints/11bbc5d9933e4ff7e25198a760e9792e/chk-863
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:59 /flink-1.5.3/flink-checkpoints/11bbc5d9933e4ff7e25198a760e9792e/chk-864
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:55 /flink-1.5.3/flink-checkpoints/11bbc5d9933e4ff7e25198a760e9792e/shared
drwxr-xr-x - hadoop supergroup 0 2018-09-01 10:55 /flink-1.5.3/flink-checkpoints/11bbc5d9933e4ff7e25198a760e9792e/taskowned
从上面我们可以看到,前面Flink Job的ID为582e17d2cc343e6c56255d111bae0191,所有的Checkpoint文件都在以Job ID为名称的目录里面,当Job停掉后,重新从某个Checkpoint点(chk-860)进行恢复时,重新生成Job ID(这里是11bbc5d9933e4ff7e25198a760e9792e),而对应的Checkpoint编号会从该次运行基于的编号继续连续生成:chk-861、chk-862、chk-863等等。
# 第二部分: Flink的Savepoint
# 1.Flink的Savepoint原理介绍
Savepoint会在Flink Job之外存储自包含(self-contained)结构的Checkpoint,它使用Flink的Checkpoint机制来创建一个非增量的Snapshot,里面包含Streaming程序的状态,并将Checkpoint的数据存储到外部存储系统中。
Flink程序中包含两种状态数据,一种是用户定义的状态(User-defined State),他们是基于Flink的Transformation函数来创建或者修改得到的状态数据;另一种是系统状态(System State),他们是指作为Operator计算一部分的数据Buffer等状态数据,比如在使用Window Function时,在Window内部缓存Streaming数据记录。为了能够在创建Savepoint过程中,唯一识别对应的Operator的状态数据,Flink提供了API来为程序中每个Operator设置ID,这样可以在后续更新/升级程序的时候,可以在Savepoint数据中基于Operator ID来与对应的状态信息进行匹配,从而实现恢复。当然,如果我们不指定Operator ID,Flink也会我们自动生成对应的Operator状态ID。 而且,强烈建议手动为每个Operator设置ID,即使未来Flink应用程序可能会改动很大,比如替换原来的Operator实现、增加新的Operator、删除Operator等等,至少我们有可能与Savepoint中存储的Operator状态对应上。另外,保存的Savepoint状态数据,毕竟是基于当时程序及其内存数据结构生成的,所以如果未来Flink程序改动比较大,尤其是对应的需要操作的内存数据结构都变化了,可能根本就无法从原来旧的Savepoint正确地恢复。
下面,我们以Flink官网文档中给定的例子,来看下如何设置Operator ID,代码如下所示:
DataStream<String> stream = env.
// 有状态的source ID (例如:Kafka)
.addSource(new StatefulSource())
.uid("source-id") // source操作的ID
.shuffle()
// 有状态的mapper ID
.map(new StatefulMapper())
.uid("mapper-id") // mapper的ID
// 无状态sink打印
.print(); // 自动生成ID
# 2.创建Savepoint
创建一个Savepoint,需要指定对应Savepoint目录,有两种方式来指定: 一种是,需要配置Savepoint的默认路径,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,设置Savepoint存储目录,例如如下所示:
state.savepoints.dir: hdfs://namenode01.td.com/flink-1.5.3/flink-savepoints
另一种是,在手动执行savepoint命令的时候,指定Savepoint存储目录,命令格式如下所示:
bin/flink savepoint :jobId [:targetDirectory]
例如,正在运行的Flink Job对应的ID为40dcc6d2ba90f13930abce295de8d038,使用默认state.savepoints.dir配置指定的Savepoint目录,执行如下命令:
bin/flink savepoint 40dcc6d2ba90f13930abce295de8d038
可以看到,在目录hdfs://namenode01.td.com/flink-1.5.3/flink-savepoints/savepoint-40dcc6-4790807da3b0下面生成了ID为40dcc6d2ba90f13930abce295de8d038的Job的Savepoint数据。 为正在运行的Flink Job指定一个目录存储Savepoint数据,执行如下命令:
bin/flink savepoint 40dcc6d2ba90f13930abce295de8d038 hdfs://namenode01.td.com/tmp/flink/savepoints
可以看到,在目录 hdfs://namenode01.td.com/tmp/flink/savepoints/savepoint-40dcc6-a90008f0f82f下面生成了ID为40dcc6d2ba90f13930abce295de8d038的Job的Savepoint数据。
# 3.从Savepoint恢复
现在,我们可以停掉Job 40dcc6d2ba90f13930abce295de8d038,然后通过Savepoint命令来恢复Job运行,命令格式如下所示:
bin/flink run -s :savepointPath [:runArgs]
以上面保存的Savepoint为例,恢复Job运行,执行如下命令:
bin/flink run -s hdfs://namenode01.td.com/tmp/flink/savepoints/savepoint-40dcc6-a90008f0f82f flink-app-jobs.jar
可以看到,启动一个新的Flink Job,ID为cdbae3af1b7441839e7c03bab0d0eefd。
# 4. Savepoint目录结构
下面,我们看一下Savepoint目录下面存储内容的结构,如下所示:
hdfs dfs -ls /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b
Found 5 items
-rw-r--r-- 3 hadoop supergroup 4935 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/50231e5f-1d05-435f-b288-06d5946407d6
-rw-r--r-- 3 hadoop supergroup 4599 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/7a025ad8-207c-47b6-9cab-c13938939159
-rw-r--r-- 3 hadoop supergroup 4976 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/_metadata
-rw-r--r-- 3 hadoop supergroup 4348 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/bd9b0849-aad2-4dd4-a5e0-89297718a13c
-rw-r--r-- 3 hadoop supergroup 4724 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/be8c1370-d10c-476f-bfe1-dd0c0e7d498a
如上面列出的HDFS路径中,11bbc5是Flink Job ID字符串前6个字符,后面bd967f90709b是随机生成的字符串,然后savepoint-11bbc5-bd967f90709b作为存储此次Savepoint数据的根目录,最后savepoint-11bbc5-bd967f90709b目录下面_metadata文件包含了Savepoint的元数据信息,其中序列化包含了savepoint-11bbc5-bd967f90709b目录下面其它文件的路径,这些文件内容都是序列化的状态信息。
参考
- http://shiyanjun.cn/archives/1855.html
- https://www.colabug.com/2259405.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/ops/state/savepoints.html
# 【----------------------------】
# Flink 专题 Checkpoint、Savepoint 机制
# CheckPoint
# 1. checkpoint 保留策略
默认情况下,checkpoint 不会被保留,取消程序时即会删除他们,但是可以通过配置保留定期检查点,根据配置 当作业失败或者取消的时候 ,不会自动清除这些保留的检查点 。 java :
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
ExternalizedCheckpointCleanup 可选项如下:
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION: 取消作业时保留检查点。请注意,在这种情况下,您必须在取消后手动清理检查点状态。
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 取消作业时删除检查点。只有在作业失败时,检查点状态才可用。
# 2. Checkpoint 配置
与SavePoint 类似 ,checkpoint 保留的是元数据文件和一些数据文件 默认情况下checkpoint 只保留 一份最新数据,如果需要进行checkpoint数据恢复 ,可以通过全局设置的方式设置该集群默认的checkpoint 保留数,以保证后期可以从checkpoint 点进行恢复 。 同时为了 及时保存checkpoint状态 还需要在服务级别设置 checkpoint 检查点的 备份速度 。 全局配置: flink-conf.yaml
// 设置 checkpoint全局设置保存点
state.checkpoints.dir: hdfs:///checkpoints/
// 设置checkpoint 默认保留 数量
state.checkpoints.num-retained: 20
注意 如果将 checkpoint保存在hdfs 系统中 , 需要设置 hdfs 元数据信息 : fs.default-scheme:
服务级别设置:
java:
// 设置 checkpoint 保存目录
env.setStateBackend(new RocksDBStateBackend("hdfs:///checkpoints-data/");
// 设置checkpoint 检查点间隔时间
env.enableCheckpointing(5000);
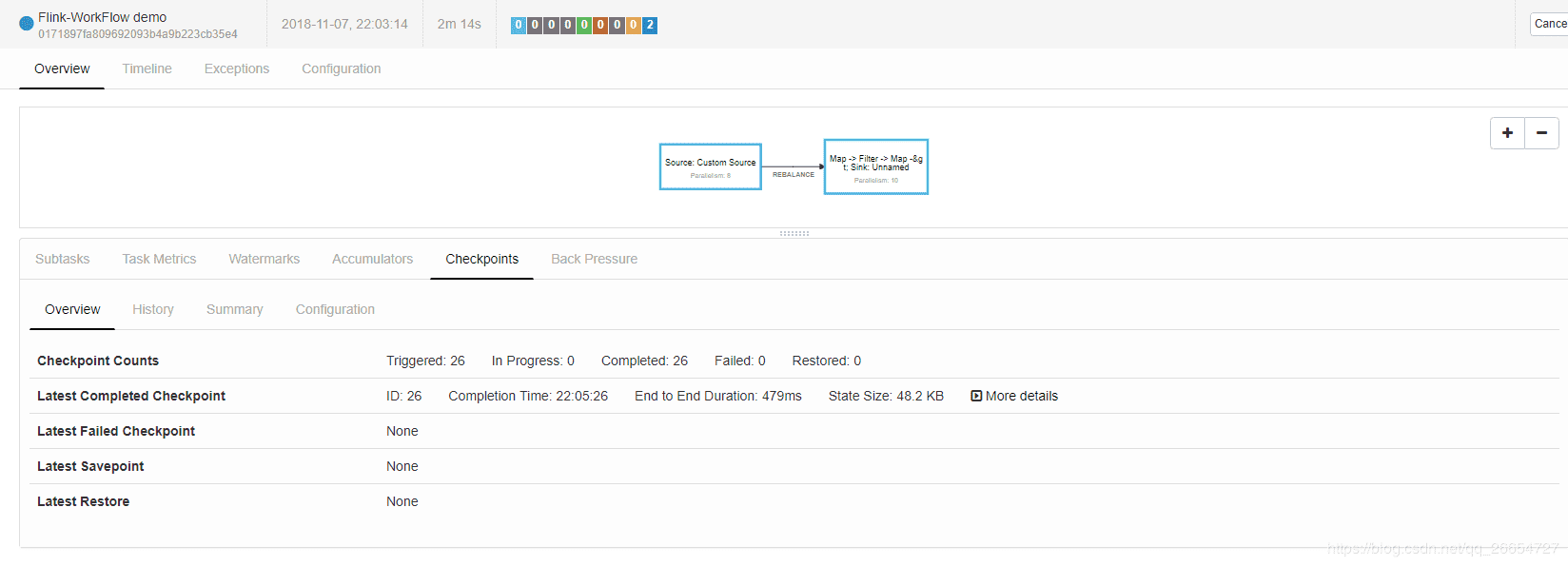
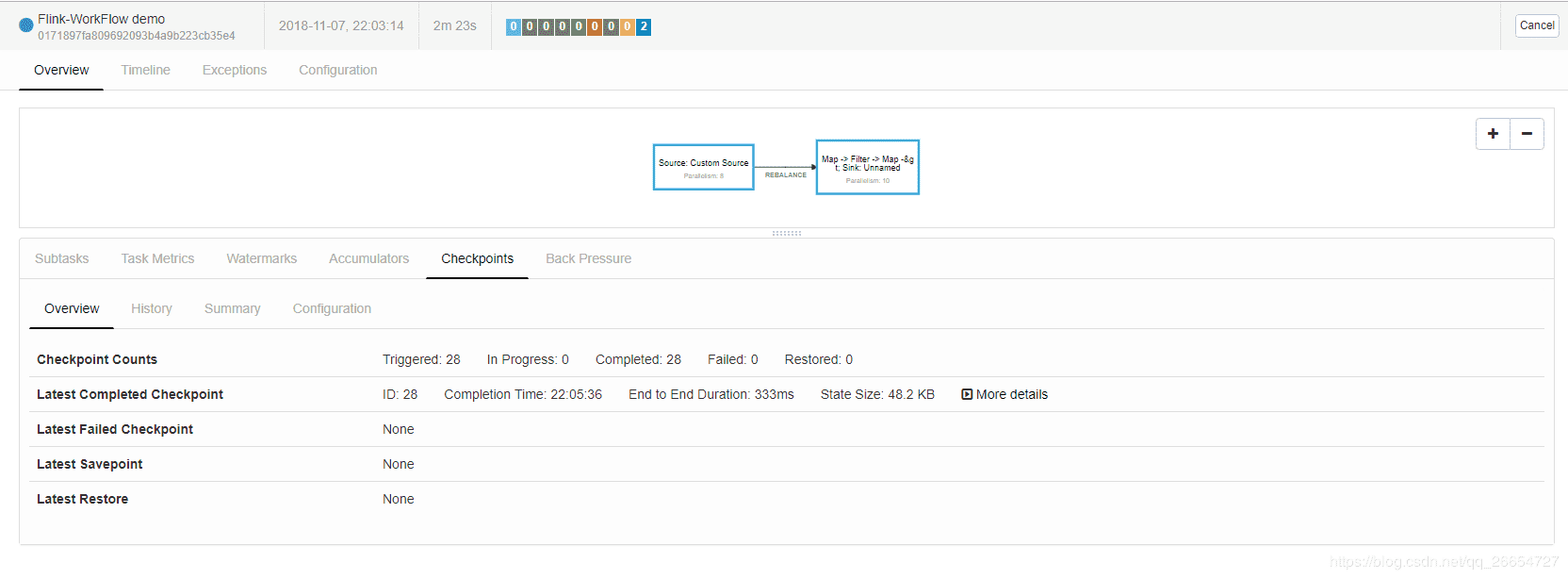
提交任务之后 job 界面 和 hdfs 界面
通过页面可以看出 checkpoint 备份方式是每5秒执行一次 ,保存当前所有task 状态元信息 和状态信息 。
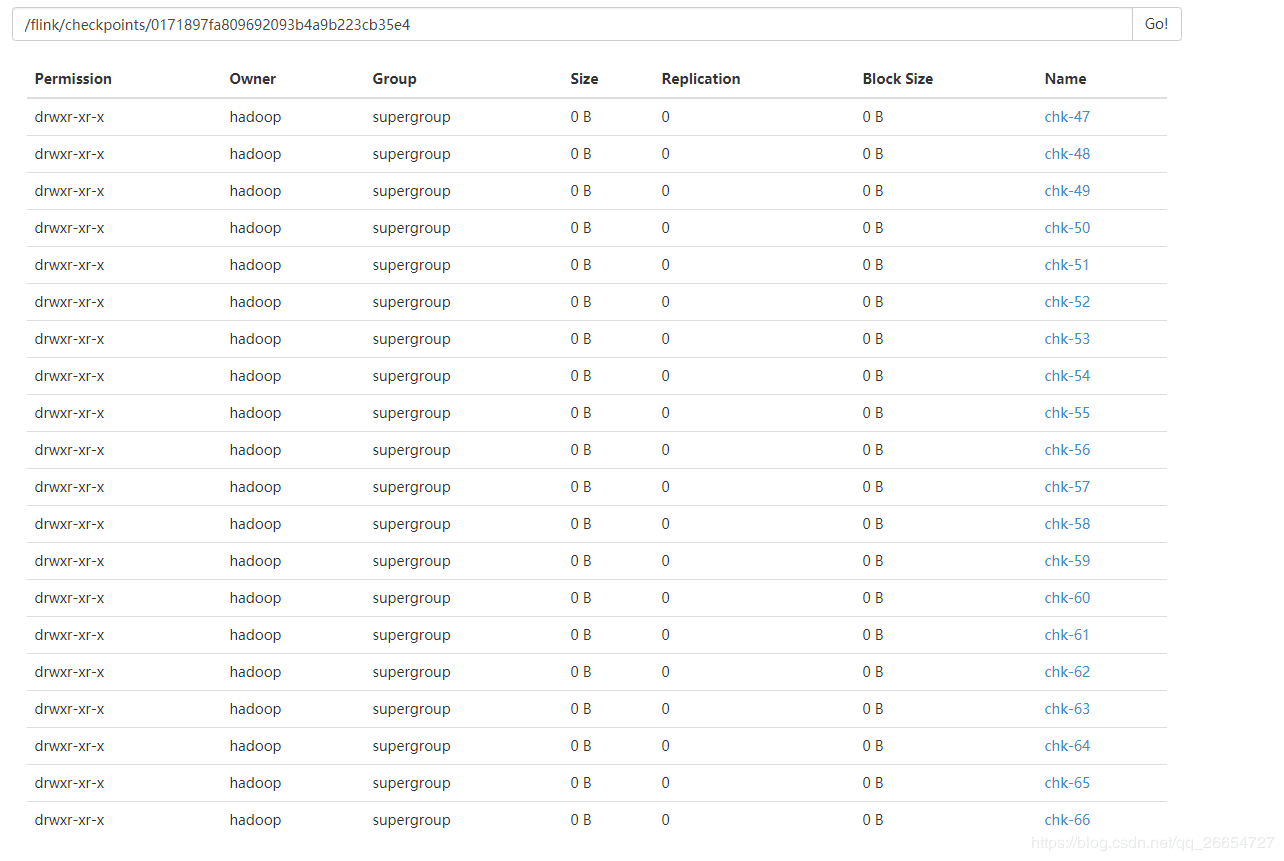
hdfs 信息 保存 jobId 为 0171897fa809692093b4a9b223cb35e4 最新的 20次 checkpoint 信息
# 3. Checkpoint 状态点恢复
因为 flink checkpoint 目录 分别对应的是 jobId , 每通过 flink run 方式 / 页面提交方式 都会重新生成 jobId ,那么如何通过checkpoint 恢复 失败任务或者重新执行保留时间点的 任务?
flink 提供了 在启动 之时 通过设置 -s 参数指定checkpoint 目录 , 让新的jobId 读取该checkpoint 元文件信息和状态信息 ,从而达到指定时间节点启动 job 。启动方式如下 :
./bin/flink -s /flink/checkpoints/0171897fa809692093b4a9b223cb35e4/chk-50/_metadata -p @Parallelism -c @Mainclass @jar
# Savepoint
# Savepoint 介绍
Savepoint是通过Flink的检查点机制创建的流作业执行状态的一致图像。您可以使用Savepoints来停止和恢复,分叉或更新Flink作业。保存点由两部分组成:稳定存储(例如HDFS,S3,...)上的(通常是大的)二进制文件和(相对较小的)元数据文件的目录。稳定存储上的文件表示作业执行状态图像的净数据。Savepoint的元数据文件以(绝对路径)的形式包含(主要)指向作为Savepoint一部分的稳定存储上的所有文件的指针。
# savepoint 和 checkpoint 区别
从概念上讲,Flink的Savepoints与Checkpoints的不同之处在于备份与传统数据库系统中的恢复日志不同。检查点的主要目的是在意外的作业失败时提供恢复机制。Checkpoint的生命周期由Flink管理,即Flink创建,拥有和发布Checkpoint - 无需用户交互。作为一种恢复和定期触发的方法,Checkpoint实现的两个主要设计目标是:i)being as lightweight to create (轻量级),ii)fast restore (快速恢复) 。针对这些目标的优化可以利用某些属性,例如,JobCode在执行尝试之间不会改变。
与此相反,Savepoints由用户创建,拥有和删除。他们的用例是planned (计划) 的,manual backup( 手动备份 ) 和 resume(恢复) 。例如,这可能是您的Flink版本的更新,更改您的Job graph ,更改 parallelism ,分配第二个作业,如红色/蓝色部署,等等。当然,Savepoints必须在终止工作后继续存在。从概念上讲,保存点的生成和恢复成本可能更高,并且更多地关注可移植性和对前面提到的作业更改的支持。
# Assigning Operator IDs ( 分配 operator ids)
为了能够在将来升级你的程序在本节中描述。主要的必要更改是通过该uid(String)方法手动指定操作员ID 。这些ID用于确定每个运算符的状态。 java:
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID
如果您未手动指定ID,则会自动生成这些ID。只要这些ID不变,您就可以从保存点自动恢复。生成的ID取决于程序的结构,并且对程序更改很敏感。因此,强烈建议手动分配这些ID。
# Savepoint State
触发保存点时,会创建一个新的保存点目录,其中将存储数据和元数据。可以通过配置默认目标目录或使用触发器命令指定自定义目标目录来控制此目录的位置
# 保存Savepoint
$ bin/flink savepoint :jobId [:targetDirectory]
这将触发具有ID的作业的保存点:jobId,并返回创建的保存点的路径。您需要此路径来还原和部署保存点。
# 在yarn 集群中保存Savepoint
$ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId
这将触发具有ID :jobId和YARN应用程序ID 的作业的保存点:yarnAppId,并返回创建的保存点的路径。
# 使用 Savepoint 取消job
$ bin/flink cancel -s [:targetDirectory] :jobId
这将以原子方式触发具有ID的作业的保存点:jobid并取消作业。此外,您可以指定目标文件系统目录以存储保存点。该目录需要可由JobManager和TaskManager访问。
# Resuming Savepoint
$ bin/flink run -s :savepointPath [:runArgs]
这将提交作业并指定要从中恢复的保存点。您可以指定保存点目录或_metadata文件的路径。
# 允许未恢复状态启动
$ bin/flink run -s :savepointPath -n [:runArgs]
默认情况下,resume操作将尝试将保存点的所有状态映射回要恢复的程序。如果删除了运算符,则可以通过--allowNonRestoredState(short -n:)选项跳过无法映射到新程序的状态:
# 全局配置
您可以通过state.savepoints.dir 配置文件设置默认savepoint 位置 。触发保存点时,此目录将用于存储保存点。您可以通过使用触发器命令指定自定义目标目录来覆盖默认值(请参阅:targetDirectory参数)。 flink-conf.yaml
## Default savepoint target directory
state.savepoints.dir: hdfs:///flink/savepoints
参考地址:
- https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/state/state_backends.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/state/checkpoints.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/state/savepoints.html
- http://ju.outofmemory.cn/entry/370841
# 参考文章
- https://blog.csdn.net/nazeniwaresakini/article/details/104649508
- https://blog.csdn.net/hxcaifly/article/details/84673292
- https://www.cnblogs.com/auguszero/p/9926394.html










