TIP
本文主要是介绍 Spark-SparkShell介绍 。
# Spark Shell简单使用
# 基础
Spark的shell作为一个强大的交互式数据分析工具,提供了一个简单的方式学习API。它可以使用Scala(在Java虚拟机上运行现有的Java库的一个很好方式)或Python。在Spark目录里使用下面的方式开始运行:
./bin/spark-shell
在Spark Shell中,有一个专有的SparkContext已经为您创建好了,变量名叫做sc。自己创建的SparkContext将无法工作。可以用--master参数来设置SparkContext要连接的集群,用--jars来设置需要添加到CLASSPATH的jar包,如果有多个jar包,可以使用逗号分隔符连接它们。例如,在一个拥有4核的环境上运行spark-shell,使用:
./bin/spark-shell --master local[4]
或在CLASSPATH中添加code.jar,使用:
./bin/spark-shell --master local[4] --jars code.jar
可以执行spark-shell --help获取完整的选项列表。
Spark最主要的抽象是叫Resilient Distributed Dataset(RDD)的弹性分布式集合。RDDs可以使用Hadoop InputFormats(例如HDFS文件)创建,也可以从其他的RDDs转换。让我们在Spark源代码目录里从README.md文本文件中创建一个新的RDD。
scala> val textFile = sc.textFile("file:///home/hadoop/hadoop/spark/README.md")
16/07/24 03:30:53 INFO storage.MemoryStore: ensureFreeSpace(217040) called with curMem=321016, maxMem=280248975
16/07/24 03:30:53 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 212.0 KB, free 266.8 MB)
16/07/24 03:30:53 INFO storage.MemoryStore: ensureFreeSpace(20024) called with curMem=538056, maxMem=280248975
16/07/24 03:30:53 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 19.6 KB, free 266.7 MB)
16/07/24 03:30:53 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:43303 (size: 19.6 KB, free: 267.2 MB)
16/07/24 03:30:53 INFO spark.SparkContext: Created broadcast 2 from textFile at <console>:21
textFile: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at textFile at <console>:21
注意:1. 其中2~7行是日志信息,暂且不必关注,主要看最后一行。之后的运行日志信息将不再贴出。用户也可以进入到spark目录/conf文件夹下,此时有一个log4j.properties.template文件,我们执行如下命令将其拷贝一份为log4j.properties,并对log4j.properties文件进行修改。
cp log4j.properties.template log4j.properties
vim log4j.properties
如下图所示,将INFO改为WARN,这样就不输出蓝色部分的日志信息:
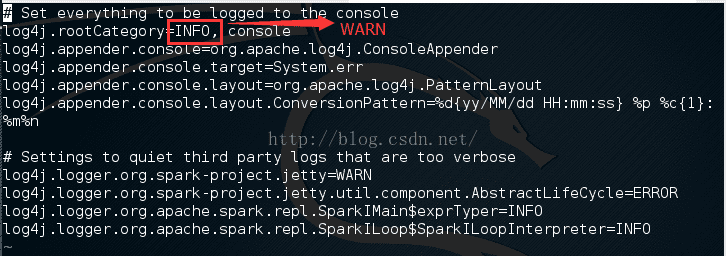
- 另外,file:///home/hadoop/hadoop/spark/README.md,首部的file代表本地目录,注意file:后有三个斜杠(/);中间红色部分是我的spark安装目录,读者可根据自己的情况进行替换。
RDD的actions (opens new window)从RDD中返回值,transformations (opens new window)可以转换成一个新RDD并返回它的引用。下面展示几个action:
scala> textFile.count()
res0: Long = 98
scala> textFile.first()
res1: String = # Apache Spark
其中,count代表RDD中的总数据条数;first代表RDD中的第一行数据。
下面使用一个transformation,我们将使用filter函数对textFile这个RDD进行过滤,取出包含字符串"Spark"的行,并返回一个新的RDD:
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:23
当然也可以把actions和transformations连接在一起使用:
scala> textFile.filter(line => line.contains("Spark")).count()
res2: Long = 19
上面这条语句表示有多少行包括字符串"Spark"。
# 更多RDD操作
RDD actions和transformations能被用在更多的复杂计算中。比如想要找到一行中最多的单词数量:
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
res3: Int = 14
首先将行映射成一个整型数值产生一个新的RDD。在这个新的RDD上调用reduce找到行中最大的单词数个数。map和reduce的参数是Scala的函数串(闭包),并且可以使用任何语言特性或者Scala/Java类库。例如,我们可以很方便地调用其他的函数声明。我们使用Math.max()函数让代码更容易理解:
scala> import java.lang.Math
import java.lang.Math
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))
res4: Int = 14
大家都知道,Hadoop流行的一个通用数据流模式是MapReduce。Spark能够很容易地实现MapReduce:
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[8] at reduceByKey at <console>:24
这里,我们结合了flatMap、map和reduceByKey来计算文件里每个单词出现的数量,它的结果是包含一组(String, Int)键值对的RDD。我们可以使用collect操作收集单词的数量:
scala> wordCounts.collect()
res5: Array[(String, Int)] = Array((package,1), (For,2), (Programs,1), (processing.,1), (Because,1), (The,1), (cluster.,1), (its,1), ([run,1), (APIs,1), (have,1), (Try,1), (computation,1), (through,1), (several,1), (This,2), ("yarn-cluster",1), (graph,1), (Hive,2), (storage,1), (["Specifying,1), (To,2), (page](http://spark.apache.org/documentation.html),1), (Once,1), (application,1), (prefer,1), (SparkPi,2), (engine,1), (version,1), (file,1), (documentation,,1), (processing,,2), (the,21), (are,1), (systems.,1), (params,1), (not,1), (different,1), (refer,2), (Interactive,2), (given.,1), (if,4), (build,3), (when,1), (be,2), (Tests,1), (Apache,1), (all,1), (./bin/run-example,2), (programs,,1), (including,3), (Spark.,1), (package.,1), (1000).count(),1), (Versions,1), (HDFS,1), (Data.,1), (>...
# 缓存
Spark支持把数据集缓存到内存之中,当要重复访问时,这是非常有用的。举一个简单的例子:
scala> linesWithSpark.cache()
res6: linesWithSpark.type = MapPartitionsRDD[2] at filter at <console>:23
scala> linesWithSpark.count()
res7: Long = 19
scala> linesWithSpark.count()
res8: Long = 19
scala> linesWithSpark.count()
res9: Long = 19
首先缓存linesWithSpark数据集,然后重复访问count函数返回的值。当然,我们并不能察觉明显的查询速度变化,但是当在大型的数据集中使用缓存,将会非常显著的提升相应的迭代操作速度。
# 参考文章
- https://blog.csdn.net/universe_ant/article/details/52014068










