TIP
本文主要是介绍 Spark-综合精华总结(一) 。
# spark基础知识总结
# 1. 概述
# 1.1. 简介
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。
Spark为我们提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。
利用内存数据存储和接近实时的处理能力,Spark比其他的大数据处理技术的性能要快很多倍。
# 1.2. Mapreduce和Spark
MapReduce是一路计算的优秀解决方案,不过对于需要多路计算和算法的用例来说,并非十分高效。
如果想要完成比较复杂的工作,就必须将一系列的MapReduce作业串联起来然后顺序执行这些作业。每一个作业都是高时延的,而且只有在前一个作业完成之后下一个作业才能开始启动。
在下一步开始之前,上一步的作业输出数据必须要存储到分布式文件系统中。因此,复制和磁盘存储会导致这种方式速度变慢。
而Spark则允许程序开发者使用有向无环图(DAG)开发复杂的多步数据管道。而且还支持跨作业的内存数据共享,以便不同的作业可以共同处理同一个数据。
Spark将中间结果保存在内存中而不是将其写入磁盘,当需要多次处理同一数据集时,这一点特别实用。
Spark会尝试在内存中存储尽可能多的数据然后将其写入磁盘。它可以将某个数据集的一部分存入内存而剩余部分存入磁盘。从而Spark可以用于处理大于集群内存容量总和的数据集。
# 1.3. Hadoop为什么慢
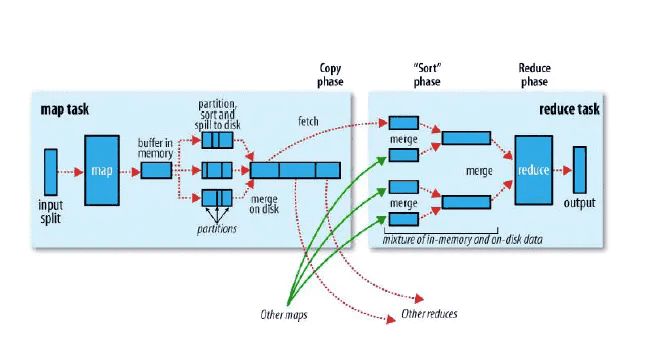
spark_base_1_3.png
Spark因为其处理数据的方式不一样,会比MapReduce快上很多。MapReduce是分步对数据进行处理的: ”从集群中读取数据,进行一次处理,将结果写到集群,从集群中读取更新后的数据,进行下一次的处理,将结果写到集群,等等…“ Booz Allen Hamilton的数据科学家Kirk Borne如此解析。
反观Spark,它会在内存中以接近“实时”的时间完成所有的数据分析:“从集群中读取数据,完成所有必须的分析处理,将结果写回集群,完成,” Born说道。Spark的批处理速度比MapReduce快近10倍,内存中的数据分析速度则快近100倍。
如果需要处理的数据和结果需求大部分情况下是静态的,且你也有耐心等待批处理的完成的话,MapReduce的处理方式也是完全可以接受的。
但如果你需要对流数据进行分析,比如那些来自于工厂的传感器收集回来的数据,又或者说你的应用是需要多重数据处理的,那么你也许更应该使用Spark进行处理。
大部分机器学习算法都是需要多重数据处理的。此外,通常会用到Spark的应用场景有以下方面:实时的市场活动,在线产品推荐,网络安全分析,机器日记监控等。
# 1.4. mapreduce和spark对比
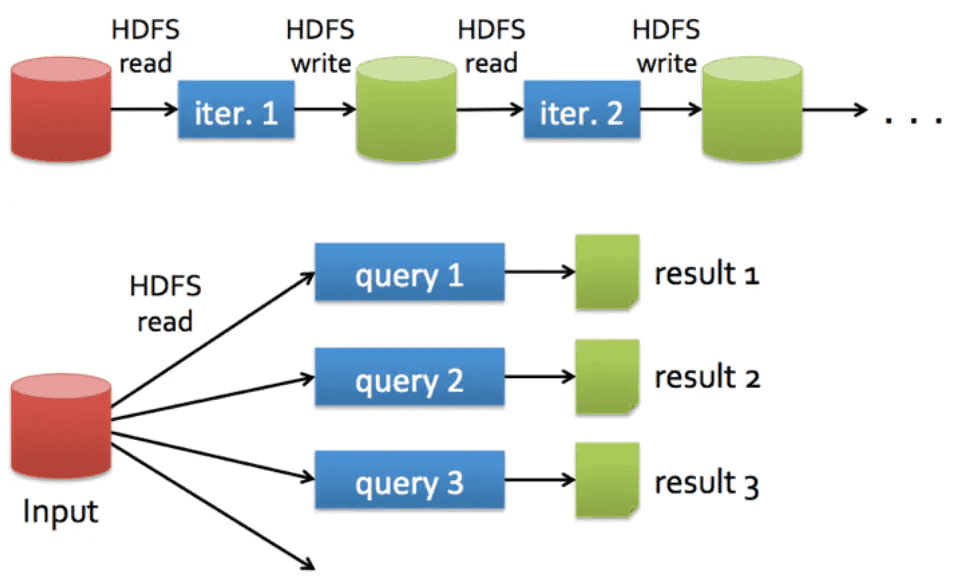
spark_base_1_4_1.png
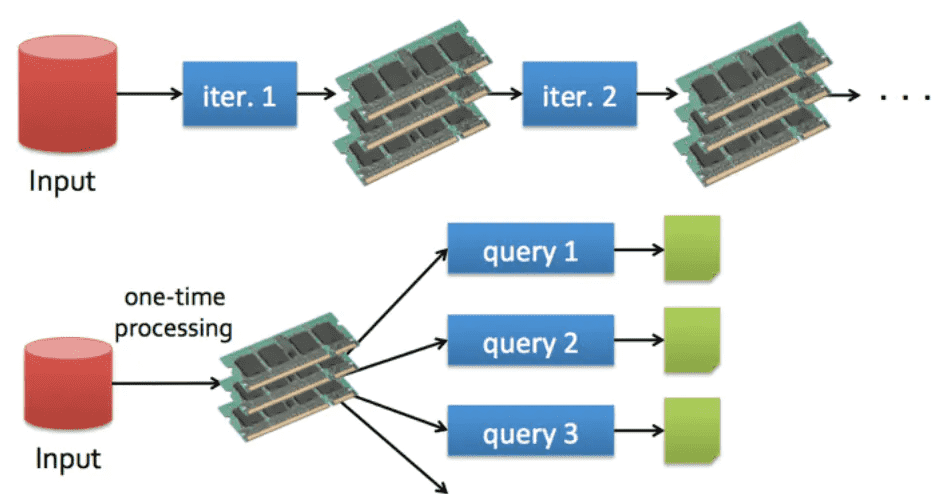
spark_base_1_4_2.png
# 1.5. spark的其他特性
- 1、支持比Map和Reduce更多的函数。
- 2、可以通过延迟计算帮助优化整体数据处理流程。
- 3、提供简明、一致的Scala,Java和Python API。
- 4、提供交互式Scala和Python Shell。帮助进行原型验证和逻辑测试 (目前暂不支持Java)
# 2. Spark生态系统
除了Spark核心API之外,Spark生态系统中还包括其他附加库,可以在大数据分析和机器学习领域提供更多的能力。
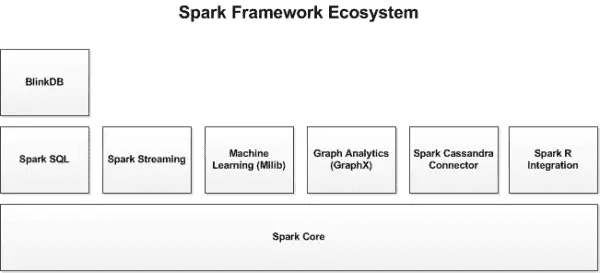
spark_base_2.png
# 2.1. Spark Streaming:
Spark Streaming基于微批量方式的计算和处理,可以用于处理实时的流数据。它使用DStream,简单来说就是一个弹性分布式数据集(RDD)系列,处理实时数据。
# 2.2. Spark SQL:
Spark SQL可以通过JDBC API将Spark数据集暴露出去,而且还可以用传统的BI和可视化工具在Spark数据上执行类似SQL的查询。用户还可以用Spark SQL对不同格式的数据(如JSON,Parquet以及数据库等)执行ETL,将其转化,然后暴露给特定的查询。
# 2.3. Spark MLlib:
MLlib是一个可扩展的Spark机器学习库,由通用的学习算法和工具组成,包括二元分类、线性回归、聚类、协同过滤、梯度下降以及底层优化原语。
# 2.4. Spark GraphX:
GraphX是用于图计算和并行图计算的新的(alpha)Spark API。通过引入弹性分布式属性图(Resilient Distributed Property Graph),一种顶点和边都带有属性的有向多重图,扩展了Spark RDD。
Tachyon是一个以内存为中心的分布式文件系统,能够提供内存级别速度的跨集群框架(如Spark和MapReduce)的可信文件共享。它将工作集文件缓存在内存中,从而避免到磁盘中加载需要经常读取的数据集。通过这一机制,不同的作业/查询和框架可以以内存级的速度访问缓存的文件。
BlinkDB是一个近似查询引擎,用于在海量数据上执行交互式SQL查询。BlinkDB可以通过牺牲数据精度来提升查询响应时间。通过在数据样本上执行查询并展示包含有意义的错误线注解的结果,操作大数据集合。
# 2.5. BDAS
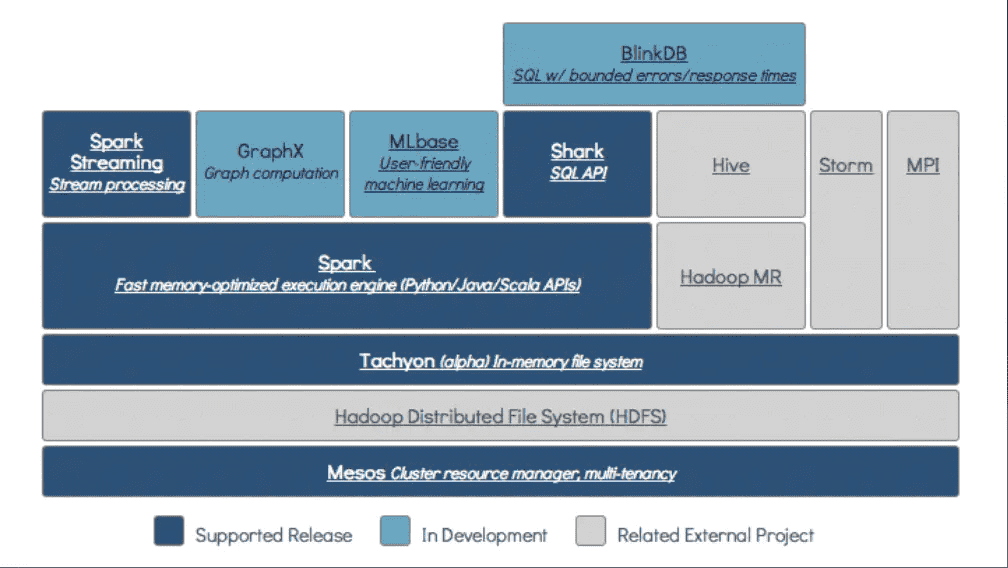
spark_base_2_5.png
# 3. Spark体系架构
Spark体系架构包括如下三个主要组件:
- 数据存储
- API
- 资源管理框架
# 3.1. 资源管理:
Spark既可以部署在一个单独的服务器集群上(Standalone)
也可以部署在像Mesos或YARN这样的分布式计算框架之上。
# 3.2. Spark API:
应用开发者可以用标准的API接口创建基于Spark的应用
Spark提供三种程序设计语言的API:
- Scala
- Java
- Python
# 3.3. 数据存储:
Spark用HDFS文件系统存储数据。它可用于存储任何兼容于Hadoop的数据源,包括HDFS,HBase,Cassandra等。
Spark在对数据的处理过程中,会将数据封装成RDD数据结构
# 4.RDD
- RDD(Resilient Distributed Datasets),弹性分布式数据集, 是分布式内存的一个抽象概念
- RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区,每个分区就是一个dataset片段
- RDD并不保存真正的数据,仅保存元数据信息
- RDD之间可以存在依赖关系
# 4.1. RDD----弹性分布式数据集:核心
- RDD是Spark框架中的核心概念。
- 可以将RDD视作数据库中的一张表。其中可以保存任何类型的数据,可以通过API来处理RDD及RDD中的数据
- 类似于Mapreduce,RDD也有分区的概念
- RDD是不可变的,可以用变换(Transformation)操作RDD,但是这个变换所返回的是一个全新的RDD,而原有的RDD仍然保持不变
# 4.2. RDD创建的三种方式
- 集合并行化
val arr = Array(1,2,3,4,5,6,7,8)
val rdd1 = sc.parallelize(arr, 2) //2代表分区数量
- 从外部文件系统
分布式文件系统:如hdfs文件系统,S3:
val rdd2 = sc.textFile("hdfs://node1:9000/words.txt")
- 从父RDD转换成新的子RDD
通过Transformation操作
# 4.3. RDD----弹性分布式数据集
RDD支持两种类型的操作:
- 变换(Transformation) 变换:变换的返回值是一个新的RDD集合,而不是单个值。调用一个变换方法,不会有任何求值计算,它只获取一个RDD作为参数,然后返回一个新的RDD。Transformation是lazy模式,延迟执行
变换函数包括:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe和coalesce。
- 行动(Action) 行动:行动操作计算并返回一个新的值。当在一个RDD对象上调用行动函数时,会在这一时刻计算全部的数据处理查询并返回结果值。
行动操作包括:reduce,collect,count,first,take,countByKey以及foreach。
# 4.4. RDD操作流程示意
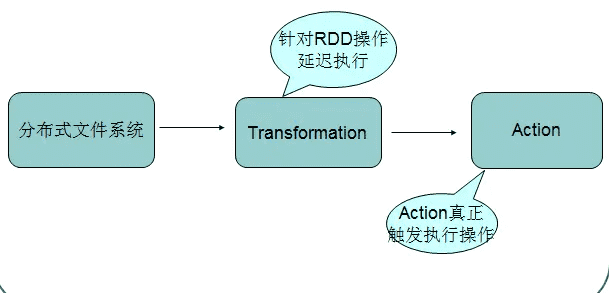
spark_base_4_4.png
# 4.5. RDD的转换与操作
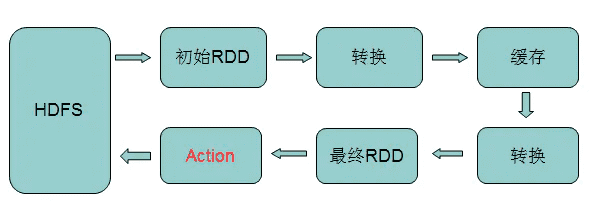
spark_base_4_5.png
# 4.6. RDD ---- 源码中的注释
Internally, each RDD is characterized by five main properties:
A list of partitions
A function for computing each split
A list of dependencies on other RDDs
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
# 4.7. 安装spark集群(Standalone)
见文档
# 4.8. spark交互式shell
spark提供一个scala-shell提供交互式操作
启动spark-shell
bin/spark-shell --master [spark://masterip:port](spark://masterip:port)(7077) 集群运行模式
bin/spark-shell --master local local运行模式
wordcount示例
scala>sc.textFile("[hdfs://namenode:port/data](hdfs://namenode:port/data)").flatMap(*.split("\t")).map((*,1)).reduceByKey().collect
# 5. spark命令
# 5.1. 查看spark的文档常见操作
- action操作

spark_base_action.png
- transformation操作

spark_base_transformation.png
- 通过并行化scala集合创建RDD
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
- 查看该rdd的分区数量
rdd1.partitions.length
- 更改分区,因为rdd是只读的,所以重新分区后会生成新的rdd来使用新的分区
val rdd2 = sc.parallelize(Array(1,2,3,4,5,6,7,8),2)val rdd3 = rdd2.repartition(3)rdd3.partitions.length
- union求并集,注意类型要一致
val rdd6 = sc.parallelize(List(5,6,4,7))val rdd7 = sc.parallelize(List(1,2,3,4))val rdd8 = rdd6.union(rdd7)rdd8.distinct.sortBy(x=>x).collect
- intersection求交集
val rdd9 = rdd6.intersection(rdd7)
- join:keyvalue形式的值,key相同join出来
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2)))val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))val rdd3 = rdd1.join(rdd2)
- groupByKey
val rdd3 = rdd1 union rdd2rdd3.groupByKeyrdd3.groupByKey.map(x=>(x._1,x._2.sum))
- WordCount
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collectsc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).groupByKey.map(t=>(t._1, t._2.sum)).collect
- cogroup:在自己的集合中分组,将分组的结果和其他集合中的结果取并集
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))val rdd3 = rdd1.cogroup(rdd2)val rdd4 = rdd3.map(t=>(t._1, t._2._1.sum + t._2._2.sum))
- cartesian笛卡尔积
val rdd1 = sc.parallelize(List("tom", "jerry"))
val rdd2 = sc.parallelize(List("tom", "kitty", "shuke"))
val rdd3 = rdd1.cartesian(rdd2)
spark action操作
- 并行化创建rdd
val rdd1 = sc.parallelize(List(1,2,3,4,5))
- collect:将rdd的数据计算,转换成scala的集合打印控制台,数据量小时用。
rdd1.collect
- reduce:将元素进行reduce计算,直接显示结果
val rdd2 = rdd1.reduce(_+_)
- count:求个数
rdd1.count
- top:取rdd中的最大的前两个
rdd1.top(2)
- take:取前几个
rdd1.take(2)
- first:取集合的第一个元素,相当于take(1)
rdd1.first
- takeOrdered:取排序的前几个
rdd1.takeOrdered(3)
- 将结果保存成文本文件
saveAsTextFile(“路径 or hdfs”)
# 5.2. spark shell
- 启动local模式的spark shell
./bin/spark-shell
- 启动集群的spark shell
./bin/spark-shell --master spark://master1:7077
- 启动集群的spark shell,配置参数
./bin/spark-shell --master spark://master1:7077 --executor-memory 512m --total-executor-cores 3
参数解释:
spark://master1:7077 : 指定主机
--executor-memory 512m:每个work使用多大内存
--total-executor-cores 3:指定work总共使用的核数
# 5.3. spark的演示
- sc: spark context,启动spark会自动创建的对象,客户端和spark交互的桥梁
- 创建RDD:
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
- 查看RDD的分区:
rdd1.partitions.length
- 转换:
rdd1.filter(_%2==0)
- 执行:
res1.collect
- map:
rdd1. filter(_%2==0).map(_*10).collect
- sortby:
rdd1. filter(_%2==0).map(_*10).sortBy(x=>x,false).collect
# 6. spark api wordcount
# 6.1. 创建项目
# 6.2. 导包
# 6.3. 写wordcount
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
class WordCount {
}
object WordCount {
def main(args: Array[String]) {
//创建配置,设置app的name
val conf = new SparkConf().setAppName("WordCount")
//创建sparkcontext,将conf传进来
val sc = new SparkContext(conf)
//从文件中读取数据,做wordcount,写到文件系统
sc.textFile(args(0)).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile(args(1))
//停止
sc.stop()
}
}
# 6.4. 打jar包
使用maven打包
# 6.5. 提交
注意提交的时候,涉及到ip的地方尽量用域名,否则报错
spark-submit --class WordCount --master spark://master1:7077 --executor-memory 512m --total-executor-cores 3 /home/hadoop/wordcount.jar hdfs://master1ha:9000/core-site.xml hdfs://master1ha:9000/out1
# 7. spark源码分析
待更新
# 参考文章
- https://www.jianshu.com/p/8e4981f231b2










