TIP
本文主要是介绍 Spark-SparkSQL总结 。
# 一.概述
# 1 spark历史
前身: shark (即Hive on Spark)
hive 进程维护 , shark 线程维护
新入口:SparkSession
RDD----->DataFrame------->Dataset
基本数据类型:Row,schema,StructType,StructField
支持: scala,Java python,R
shark:
执行计划优化完全依赖于Hive,不方便添加新的优化策略;
Spark是线程级并行,而MapReduce是进程级并行。
Spark在兼容Hive的实现上存在线程安全问题,导致Shark
不得不使用另外一套独立维护的打了补丁的Hive源码分支;
Spark SQL:
作为Spark生态的一员继续发展,而不再受限于Hive,
只是兼容Hive;Hive on Spark作为Hive的底层引擎之一
Hive可以采用Map-Reduce、Tez、Spark等引擎
# 2 Spark-SQL 概述
# 2.1 特点
- 数据兼容:不仅兼容Hive,还可以从RDD、parquet文件、Json文件获取数据、支持从RDBMS获取数据
- 性能优化:采用内存列式存储、自定义序列化器等方式提升性能;
- 组件扩展:SQL的语法解析器、分析器、优化器都可以重新定义和扩展
- 兼容: Hive兼容层面仅依赖HiveQL解析、Hive元数据。 从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了,Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
- 支持: 数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据; Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范;
# 2.2 作用
- Spark 中用于处理结构化数据的模块;
- 相对于RDD的API来说,提供更多结构化数据信息和计算方法
- 可以通过SQL或DataSet API方式同Spark SQL进行交互,
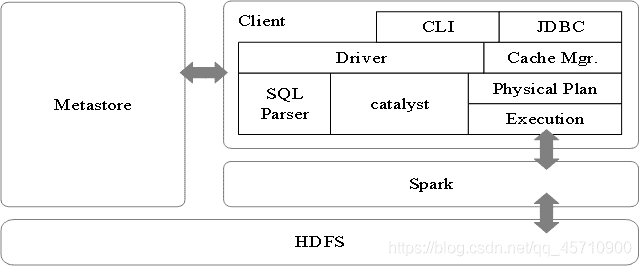
# 2.3 Spark SQL架构图
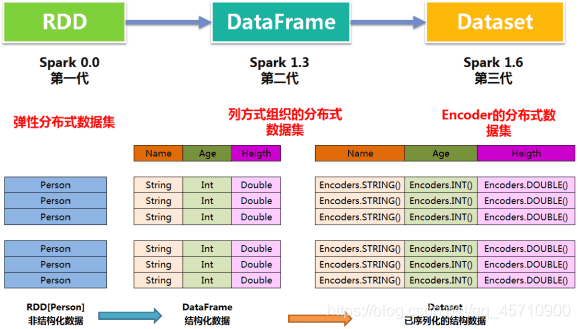
# 3 Dataset演进历史
RDD------------------->DataFrame-------------------->Dataset
0.0 1.3 1.6
12
# 3.1 RDD
# 3.1.1 优点
- 编译时类型安全,编译时就能检查出类型错误;
- 面向对象的编程风格,直接通过class.name的方式来操作数据;
idAge.filter(*.age > “”) // 编译时报错, int不能跟与String比较
idAgeRDDPerson.filter(*.age > 25) // 直接操作一个个的person对象
# 3.1.2 缺点
- 序列化和反序列化的性能开销,无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化反序列化;
- GC的性能开销,频繁的创建和销毁对象, 势必会增加GC
# 3.2 DataFrame
# 3.2.1 优点
- off-heap类似于地盘, schema类似于地图, 有自己地盘了, 不再受JVM的限制, 也就不再受GC的困扰了
- 通过schema和off-heap, DataFrame克服了RDD的缺点。对比RDD提升计算效率、减少数据读取、底层计算优化;
# 3.2.2 缺点
- DataFrame克服了RDD的缺点,但是却丢了RDD的优点。
- DataFrame不是类型安全的,API也不是面向对象风格的。
// API不是面向对象的
idAgeDF.filter(idAgeDF.col(“age”) > 25)
// 不会报错, DataFrame不是编译时类型安全的
idAgeDF.filter(idAgeDF.col(“age”) > “”)
# 3.2.3 核心特征
- DataFrame的前身是SchemaRDD,不继承RDD,自己实现了RDD的大部分功能,在DataFrame上调用RDD的方法转化成另外一个RDD
- DataFrame可以看做分布式Row对象的集合,DataFrame 不仅有比RDD更多的算子,还可以进行执行计划的优化;
- DataFrame表示为DataSet
[Row],即DataSet的子集
- DataFrame表示为DataSet
- Row :被 DataFrame 自动实现,一行就是一个Row对象
- Schema :包含了以ROW为单位的每行数据的列的信息; Spark通过Schema就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了
- off-heap : Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时, 就直接操作off-heap内存
- Tungsten:新的执行引擎
- Catalyst:新的语法解析框架
# 3.3 Dataset
Spark第三代API:Dataset;Dataset的核心:Encoder
# 3.3.1 区别
DataSet不同于RDD,没有使用Java序列化器或者Kryo进行序列化,而是使用一个特定的编码器进行序列化,这些序列化器可以自动生成,而且在spark执行很多操作(过滤、排序、hash)的时候不用进行反序列化。
# 3.3.2 特点
- 编译时的类型安全检查,性能极大的提升,内存使用极大降低、减少GC、极大的减少网络数据的传输,极大的减少scala和java之间代码的差异性。
- DataFrame每一个行对应了一个Row。而Dataset的定义更加宽松,每一个record对应了一个任意的类型。DataFrame只是Dataset的一种特例。
- 不同于Row是一个泛化的无类型JVM object, Dataset是由一系列的强类型JVM object组成的,Scala的case class或者Java class定义。因此Dataset可以在编译时进行类型检查
- Dataset以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式被存储,不需要反序列化就可以执行sorting、shuffle等操作。
- Dataset创立需要一个显式的Encoder,把对象序列化为二进制。
# 4 SparkSQL API
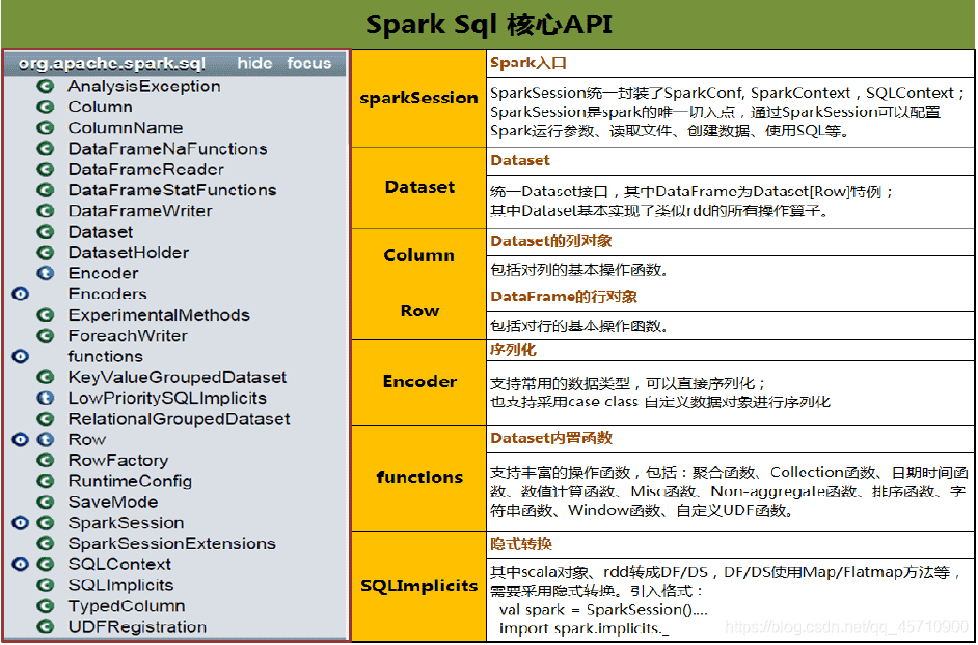 SparkSession:Spark的一个全新的切入点,统一Spark入口;
SparkSession:Spark的一个全新的切入点,统一Spark入口;
# 4.1创建SparkSession
val spark = SparkSession.builder
.appName()
.enableHiveSupport()
.getOrCreate()
.master()
spark.conf.set(“spark.sql.shuffle.partitions”,6)
spark.conf.set(“spark.executor.memory”, “2g”)
# 4.2 核心API
1、sparkSession: spark入口
统一封装SparkConf,SparkContext,SQLContext, 配置运行参数,读取文件,创建数据,使用SQL
2、Dataset:
统一Dataset接口,其中DataFrame==Dataset[Row]
基本实现了类似RDD的所有算子
column: Dataset的列对象
包括对列操作的基本函数
3、ROW : DataFrame的行对象
包括对行操作的基本函数
4、Encoder : 序列化
支持常用的数据类型,可以直接序列化,也支持case class自定义数据对象进行序列化
5、functions: Dataset的内置函数
支持丰富的操作函数(聚合,collection… …)
6、SQlImplict: 隐式转换
其中scala对象RDD转换成DF/DS ,DF/DS使用Map/FlatMap方法等;
要采用的隐式转换格式的
val spark= SparkSession.()
import spark.implicts._
注意 : Dataset是一个类(RDD是一个抽象类,而Dataset不是抽象类),其中有三个参数:
SparkSession(包含环境信息)
QueryExecution(包含数据和执行逻辑)
Encoder[T]:数据结构编码信息(包含序列化、schema、数据类型)
# 5 基本操作
# 5.1 Row
import org.apache.spark.sql.Row
//创建行对象
val row1=Row(1,”ss”,12,2.2)
//访问
row1(0)
row1.getInt(0)//要与数据的类型对应
row1.getAs[Int](https://blog.csdn.net/qq_45710900/article/details/0)
# 5.2 Schema
DataFrame(即带有Schema信息的RDD)Spark通过Schema就能够读懂数据 DataFrame中提供了详细的数据结构信息,从而使得SparkSQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么,DataFrame中的数据结构信息,即为schema。
# 5.3 Schema & StructType & StructField
import org.apache.spark.sql.types._
1. val s=(new StructType)
.add(“列名”,”类型”,可是否为空,”备注”)
.add(“列名”,”类型”,true/false,”备注”)
val s1=(new StructType)
.add(“列名”,IntType,可是否为空,”备注”)
.add(“列名”,StringType,可是否为空,”备注”)
2. val s2=(new StructType)
.add(StructField(“列名”,IntType,false))
.add(StructField(“列名”,StringType,true))
3. val s3=StructType(StructField(“列名”,StringType,true)::
StructField(“列名”,IntType,true)::Nil )
val s4=StructType( (List/Sep)
(StructField(“列名”,StringType,true)::
StructField(“列名”,IntType,true)::Nil ))
# 6 Dataset & DataFrame
Spark提供了一整套用于操纵数据的DSL (DSL :Domain Specified Language,领域专用语言) DSL在语义上与SQL关系查询非常相近
# 6.1 Dataset& DataFrame 的创建


1. 由range生成Dataset
val numDS = spark.range(5, 100, 5)
//降序显示前五个
numDS.orderBy(desc(“id”)).show(5)
//显示总数,平均数,偏差,最大值,最小值
numDS.describe().show
2. 多列由集合生成Dataset
**case class Person(name:String, age:Int, height:Int)**
val seq1 = Seq(Person(“Jack”, 28, 184), Person(“Tom”, 10, 144))
val ds1 = spark.createDataset(seq1)
ds1.show
val seq2 = Seq((“Jack”, 28, 184), (“Tom”, 10, 144))
val ds2 = spark.createDataset(seq2)
ds2.show
3. 集合转成DataFrame,并修改列名必须有类型
val seq1 =[Sep/List] ((“Jack”, 28, 184), (“Tom”, 10, 144), (“Andy”, 16, 165))
val df1 = spark.createDataFrame(seq1)
.withColumnRenamed("_1", “name1”)
.withColumnRenamed("_2",“age1”)
.withColumnRenamed("_3", “height1”)
df1.orderBy(desc(“age1”)).show(10)
val df2 = spark.createDataFrame(seq1).toDF(“name”, “age”, “height”).show
// 简单!2.0.0的新方法
createDataset 无法运用toDS 修改列名
# 6.1.2 read 的格式

import org.apache.spark.sql.types._
val schema2 = StructType( StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("height", IntegerType, false) :: Nil)
options( Map(k,v) )
val df = spark.read.options(Map(("delimiter", ","),
("header", "false")))
.schema(schema2)
.csv("file:///home/spark/t01.csv")
option().option()
val df1=spark.read.option("header", "true")
.option("inferschema","true")
.csv("data/emp.dat")
df.show()
delimiter //分隔符
header //是否要头部作为列名
schema //设置格式列名
inferschema //当不指定schema时自动推测列的格式
val df = spark.read.csv(“file:///home/spark/data/sparksql/t01.csv”)
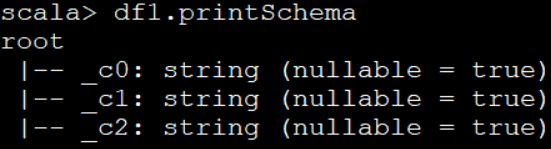
val df = spark.read.option(“inferschema”,“true”).csv(“file:///home/spark/data/sparksql/t01.csv”)

val df = spark.read.options(Map((“delimiter”, “,”), (“header”, “false”))). schema(schema6).csv(“file:///home/spark/data/sparksql/t01.csv”)
val df = spark.read.csv(“file:///home/spark/data/sparksql/t01.csv”)
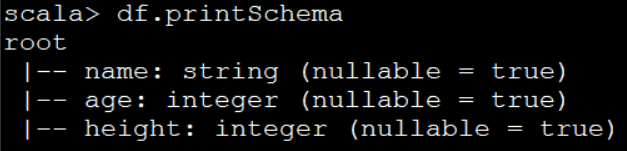
# 6.1.3 ** 从MySQL读取数据 **
// 读取数据库中的数据
val jdbcDF = spark.read.format("jdbc").
option("url", "jdbc:mysql://localhost:3306/spark").
option("driver","com.mysql.jdbc.Driver").
option("dbtable", "student").
option("user", "hive").
option("password", "hive").load()
jdbcDF.show
jdbcDF.printSchema
备注:
- 1、将jdbc驱动拷贝到
$SPARK_HOME/jars目录下,是最简单的做法; - 2、明白每一个参数的意思,一个参数不对整个结果出不来;
- 3、从数据库从读大量的数据进行分析,不推荐;读取少量的数据是可以接受的,也是常见的做法。
# 7 RDD & DataFrame & DataSet 相互转换
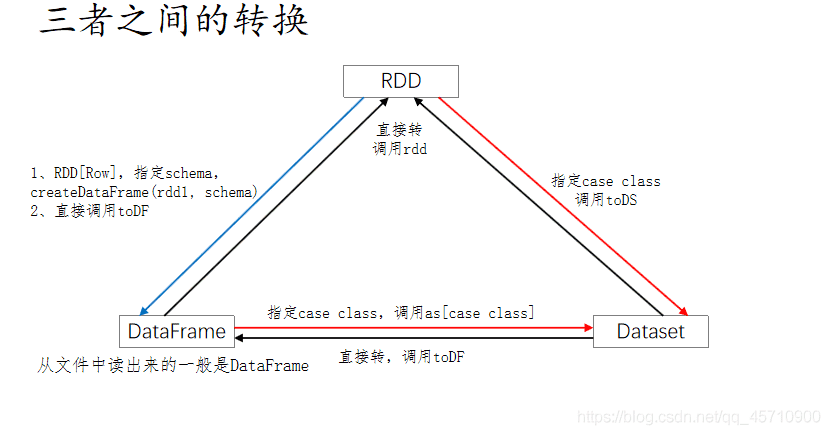
# 7.1 共性
1、RDD、DataFrame、Dataset都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利;
2、三者都有惰性机制。在进行创建、转换时(如map方法),不会立即执行;只有在遇到Action时(如foreach) ,才会开始遍历运算。极端情况下,如果代码里面仅有创建、转换,但后面没有在Action中使用对应的结果,在执行时会被直接跳过;
3、三者都有partition的概念,进行缓存(cache)操作、还可以进行检查点(checkpoint)操作;
4、三者有许多相似的函数,如map、filter,排序等;
5、在对DataFrame和Dataset进行操作时,很多情况下需要 spark.implicits._ 进行支持;
# 7.2 DataFrame
DataFrame(DataFrame 是 Dataset[Row]的别名):
DataFrame = RDD[Row] + schema**
1、与RDD和Dataset不同,DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值;
2、DataFrame与Dataset一般与spark ml同时使用;
3、DataFrame与Dataset均支持sparksql的操作,比如select,groupBy之类,还能注册临时视图,进行sql语句操作;
4、DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然;
# 7.3 Dataset
Dataset = RDD[case class].toDS
1、Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同;
2、DataFrame 定义为 Dataset[Row]。每一行的类型是Row,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用前面提到的getAS方法或者模式匹配拿出特定字段;
3、Dataset每一行的类型都是一个case class,在自定义了case class之后可以很自由的获得每一行的信息;
# 7.3 转换
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换
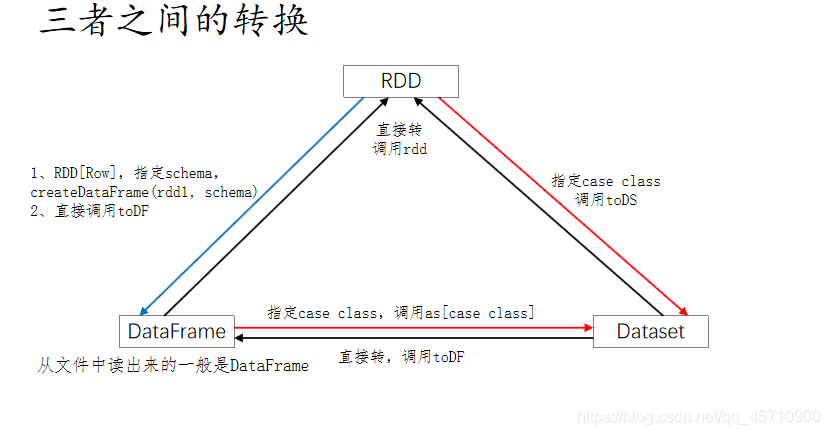
# 7.3.1DataFrame/Dataset 转 RDD:
// 这个转换很简单
val rdd1=testDF.rdd
val rdd2=testDS.rdd
# 7.3.2RDD 转 DataFrame:
// 一般用元组把一行的数据写在一起,然后在toDF中指定字段名
import spark.implicits._
val testDF = rdd.map {line=>
(line._1,line._2)
}.toDF("col1","col2")
# 7.3.3RDD 转 DataSet:
// 核心就是要定义case class
import spark.implicits._
case class Coltest(col1:String, col2:Int)
val testDS = rdd.map{line=>Coltest(line._1,line._2)}.toDS
# 7.3.4Dataset 转 DataFrame:
// 这个转换简单,只是把 case class 封装成Row
import spark.implicits._
val testDF = testDS.toDF
# 7.3.5DataFrame 转 Dataset:
// 每一列的类型后,使用as方法(as方法后面还是跟的case class,这个是核心),转成Dataset。
import spark.implicits._
case class Coltest … …
val testDS = testDF.as[Coltest]
特别注意:
在使用一些特殊操作时,一定要加上import spark.implicits._ 不然toDF、toDS无法使用**
case class Person(name:String, age:Int, height:Int)
val arr = Array(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val rdd1 = sc.makeRDD(arr)
val df = rdd1.toDF()
val df = rdd1.toDF("name", "age", "height")
df.as[Person]
# 二. spark sql 算子
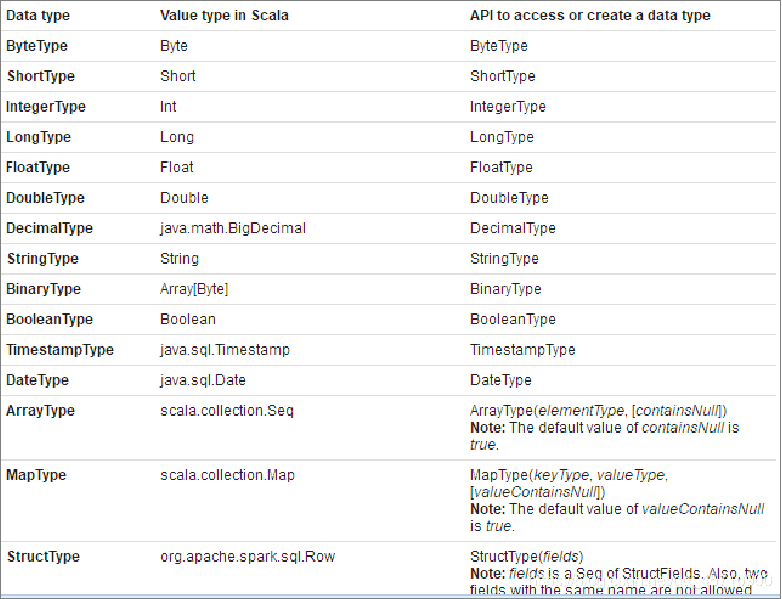
# 1.数据类型
import org.apache.spark.sql.types._
# 2. Actions
df1.count
// 缺省只会显示20行(show里不写时)
df1.union(df1).show()
// 显示2行
df1.show(2)
// 不截断字符
df1.toJSON.show(false)
// 显示10行,不截断字符
df1.toJSON.show(10, false)
spark.catalog.listFunctions.show(10000, false)
// collect返回的是数组, Array[org.apache.spark.sql.Row]
val c1 = df1.collect()
// collectAsList返回的是List, List[org.apache.spark.sql.Row]
val c2 = df1.collectAsList()
// 返回 org.apache.spark.sql.Row
val h1 = df1.head()
val f1 = df1.first()
// 返回 Array[org.apache.spark.sql.Row],长度为3
val h2 = df1.head(3)
val f2 = df1.take(3)
// 返回 List[org.apache.spark.sql.Row],长度为2
val t2 = df1.takeAsList(2)
case class Person(name:String, age:Int, height:Int)
val seq1 = Seq(Person("Jack", 28, 184),
Person("Tom", 10, 144), Person("Andy", 16, 165))
val ds1 = spark.createDataset(seq1)
ds1.reduce{ (f1, f2) => Person("sum", f1.age+f2.age, f1.height+f2.height) }
// 结构属性
df1.columns // 查看列名
df1.dtypes // 查看列名和类型
df1.explain() // 参看执行计划
df1.col("name") // 获取某个列
df1.printSchema // 常用
# 3. Transformations
// map、flatMap操作(与RDD基本类似)
df1.map(row=>row.getAs[Int](0)).show
case class Peoples(age:Int, names:String)
val seq1 = Seq(Peoples(30, "Tom, Andy, Jack"), Peoples(20, "Pand, Gate, Sundy"))
val ds1 = spark.createDataset(seq1)
val ds2 = ds1.map(x => (x.age+1, x.names))
ds2.show
val ds3 = ds1.flatMap{ x =>
val a = x.age
val s = x.names.split(",").map(name => (a, name.trim))
s
}
ds3.show
// filter
df1.filter("sal>3000").show
// randomSplit(与RDD类似,将DF、DS按给定参数分成多份)
val df2 = df1.randomSplit(Array(0.5, 0.6, 0.7))
df2(0).count
df2(1).count
df2(2).count
// 取10行数据生成新的DataSet
val df2 = df1.limit(10)
// distinct,去重
val df2 = df1.union(df1)
df2.distinct.count
// dropDuplicates,按列值去重
df2.dropDuplicates.show
df2.dropDuplicates("mgr", "deptno").show
df2.dropDuplicates("mgr").show
df2.dropDuplicates("deptno").show
// 返回全部列的统计(count、mean、stddev、min、max)
ds1.describe().show
// 返回指定列的统计
ds1.describe("sal").show
ds1.describe("sal", "comm").show
// 存储相关的方法,与RDD的方法一致
import org.apache.spark.storage.StorageLevel
spark.sparkContext.setCheckpointDir("hdfs://node1:8020/checkpoint")
df1.show()
df1.checkpoint()
df1.cache()
df1.persist(StorageLevel.MEMORY_ONLY)
df1.count()
df1.unpersist(true)
# 4. select相关
// 列的多种表示方法(5种)。使用""、$""、'、col()、ds("")
// 注意:不要混用;必要时使用spark.implicitis._;并非每个表示在所有的地方都有效
df1.select($"ename", $"hiredate", $"sal").show
df1.select("ename", "hiredate", "sal").show
df1.select('ename, 'hiredate, 'sal).show
df1.select(col("ename"), col("hiredate"), col("sal")).show
df1.select(df1("ename"), df1("hiredate"), df1("sal")).show
// 下面的写法无效,其他列的表示法有效
df1.select("ename", "hiredate", "sal"+100).show
df1.select("ename", "hiredate", "sal+100").show
// 可使用expr表达式(expr里面只能使用引号)
df1.select(expr("comm+100"), expr("sal+100"), expr("ename")).show
df1.selectExpr("ename as name").show
df1.selectExpr("power(sal, 2)", "sal").show
//四舍五入,负数取小数点以前的位置,正数取小数点后的位数
df1.selectExpr("round(sal, -3) as newsal", "sal", "ename").show
drop、withColumn、 withColumnRenamed、casting
// drop 删除一个或多个列,得到新的DF
df1.drop("mgr")
df1.drop("empno", "mgr")
// withColumn,修改列值
val df2 = df1.withColumn("sal", $"sal"+1000)
df2.show
// withColumnRenamed,更改列名
df1.withColumnRenamed("sal", "newsal")
// 备注:drop、withColumn、withColumnRenamed返回的是DF
df1.selectExpr("cast(empno as string)").printSchema
import org.apache.spark.sql.types._
df1.select('empno.cast(StringType)).printSchema
# 5.where 相关
// where操作
df1.filter("sal>1000").show
df1.filter("sal>1000 and job=='MANAGER'").show
// filter操作
df1.where("sal>1000").show
df1.where("sal>1000 and job=='MANAGER'").show
1234567
# 6. groupBy 相关
// groupBy、max、min、mean、sum、count(与df1.count不同)
df1.groupBy("列名").sum("sal").show
df1.groupBy("Job").max("sal").show
df1.groupBy("Job").min("sal").show
df1.groupBy("Job").avg("sal").show
df1.groupBy("Job").count.show
// agg
df1.groupBy().agg("sal"->"max", "sal"->"min", "sal"->"avg", "sal"->"sum", "sal"->"count").show
df1.groupBy("Job").agg("sal"->"max", "sal"->"min", "sal"->"avg", "sal"->"sum", "sal"->"count").show
df1.groupBy("deptno").agg("sal"->"max", "sal"->"min", "sal"->"avg", "sal"->"sum", "sal"->"count").show
// 这种方式更好理解
df1.groupBy("Job").agg(max("sal"), min("sal"), avg("sal"), sum("sal"), count("sal")).show
// 给列取别名
df1.groupBy("Job").agg(max("sal"), min("sal"), avg("sal"), sum("sal"), count("sal")).withColumnRenamed("min(sal)", "min1").show
// 给列取别名,最简便
df1.groupBy("Job").agg(max("sal").as("max1"), min("sal").as("min2"), avg("sal").as("avg3"), sum("sal").as("sum4"), count("sal").as("count5")).show
# 7. orderBy、sort 相关
// orderBy
df1.orderBy("sal").show
df1.orderBy($"sal").show
df1.orderBy($"sal".asc).show
df1.orderBy('sal).show
df1.orderBy(col("sal")).show
df1.orderBy(df1("sal")).show
//降序
df1.orderBy($"sal".desc).show
df1.orderBy(-'sal).show
df1.orderBy(-'deptno, -'sal).show
// sort,以下语句等价
df1.sort("sal").show
df1.sort($"sal").show
df1.sort($"sal".asc).show
df1.sort('sal).show
df1.sort(col("sal")).show
df1.sort(df1("sal")).show
//降序
df1.sort($"sal".desc).show
df1.sort(-'sal).show
df1.sort(-'deptno, -'sal).show
# 8. 集合相关(交、并、差)
// union、unionAll、intersect、except。集合的交、并、差
val ds3 = ds1.select("sname")
val ds4 = ds2.select("sname")
// union 求并集,不去重
ds3.union(ds4).show
// unionAll、union 等价;unionAll过期方法,不建议使用
ds3.unionAll(ds4).show
// intersect 求交
ds3.intersect(ds4).show
// except 求差
ds3.except(ds4).show
# 9. join 相关(DS在join操作之后变成了DF)
// 10种join的连接方式(下面有9种,还有一种是笛卡尔积)
ds1.join(ds2, "sname").show
ds1.join(ds2, Seq("sname"), "inner").show
ds1.join(ds2, Seq("sname"), "left").show
ds1.join(ds2, Seq("sname"), "left_outer").show
ds1.join(ds2, Seq("sname"), "right").show
ds1.join(ds2, Seq("sname"), "right_outer").show
ds1.join(ds2, Seq("sname"), "outer").show
ds1.join(ds2, Seq("sname"), "full").show
ds1.join(ds2, Seq("sname"), "full_outer").show
ds1.join(ds2, Seq("sname"), "left_semi").show
ds1.join(ds2, Seq("sname"), "left_anti").show
备注:DS在join操作之后变成了DF
val ds1 = spark.range(1, 10)
val ds2 = spark.range(6, 15)
// 类似于集合求交
ds1.join(ds2, Seq("id"), "left_semi").show
// 类似于集合求差
ds1.join(ds2, Seq("id"), "left_anti").show
# 10.空值处理
// NaN 非法值
math.sqrt(-1.0); math.sqrt(-1.0).isNaN()
df1.show
// 删除所有列的空值和NaN
df1.na.drop.show
// 删除某列的空值和NaN
df1.na.drop(Array("mgr")).show
// 对全部列填充;对指定单列填充;对指定多列填充
df1.na.fill(1000).show
df1.na.fill(1000, Array("comm")).show
df1.na.fill(Map("mgr"->2000, "comm"->1000)).show
// 对指定的值进行替换
df1.na.replace("comm" :: "deptno" :: Nil, Map(0 -> 100, 10 -> 100)).show
// 查询空值列或非空值列。isNull、isNotNull为内置函数
df1.filter("comm is null").show
df1.filter($"comm".isNull).show
df1.filter(col("comm").isNull).show
df1.filter("comm is not null").show
df1.filter(col("comm").isNotNull).show
# 11. 时间日期函数
// 各种时间函数
df1.select(year($"hiredate")).show
df1.select(weekofyear($"hiredate")).show
df1.select(minute($"hiredate")).show
df1.select(date_add($"hiredate", 1), $"hiredate").show
df1.select(current_date).show
df1.select(unix_timestamp).show
val df2 = df1.select(unix_timestamp as "unixtime")
df2.select(from_unixtime($"unixtime")).show
// 计算年龄
df1.select(round(months_between(current_date, $"hiredate")/12)).show
# 12. json 数据源 建表
// 读数据(txt、csv、json、parquet、jdbc)
val df2 = spark.read.json("data/employees.json")
df2.show
// 备注:SparkSQL中支持的json文件,文件内容必须在一行中
// 写文件
df1.select("ename", "sal").write.format("csv").save("data/t2")
df1.select("ename", "sal").write
.option("header", true)
.format("csv").save("data/t2")
建表:
val data =spark.read.json("/project/weibo/*.json")
data.createOrReplaceTempView("t2")
spark.sql("create table sparkproject.weibo as select * from t2")
spark.sql("select * from sparkproject.weibo limit 5").show
# 13. DF、DS对象上的SQL语句
// 注册为临时视图。
// 有两种形式:createOrReplaceTempView / createTempView
df1.createOrReplaceTempView("temp1")
spark.sql("select * from temp1").show
df1.createTempView("temp2")
spark.sql("select * from temp2").show
// 使用下面的语句可以看见注册的临时表
spark.catalog.listTables.show
备注:
1、spark.sql返回的是DataFrame;
2、如果TempView已经存在,使用createTempView会报错;
3、SQL的语法与HQL兼容;
# 三 窗体函数 (不断地累计计算)
# 1. 语法形式
分析函数的语法结构一般是:
分析函数名(参数) OVER (PARTITION BY子句 ORDER BY子句 ROWS/RANGE子句)
分析函数名:sum、max、min、count、avg等聚集函数,或lead、lag行比较函数 或 排名函数等;
over:关键字,表示前面的函数是分析函数,不是普通的集合函数;
分析子句:over关键字后面挂号内的内容;分析子句又由以下三部分组成:
partition by:分组子句,表示分析函数的计算范围,不同的组互不相干;
ORDER BY:排序子句,表示分组后,组内的排序方式;
ROWS/RANGE:窗口子句,是在分组(PARTITION BY)后,组内的子分组(也称窗口),是分析函数的计算范围窗口。窗口有两种,ROWS和RANGE;

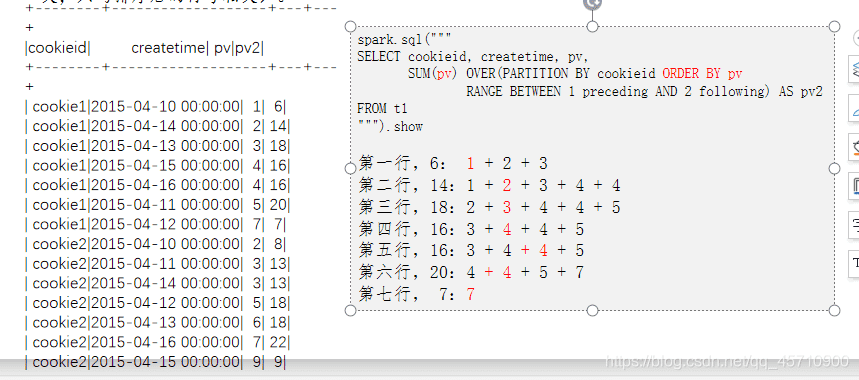
spark.sql("""
SELECT cookieid, createtime, pv,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS pv1,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2
FROM t1
“”").show
ROWS BETWEEN,也叫做Window子句
当同一个select查询中存在多个窗口函数时,他们相互之间是没有影响的.每个窗口函数应用自己的规则;
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:
ROWS BETWEEN … AND …(开始到结束,位置不能交换)
UNBOUNDED PRECEDING:从第一行开始
CURRENT ROW:当前行
第一行:UNBOUNDED PRECEDING
最后一行:UNBOUNDED FOLLOWING
前 n 行:n PRECEDING
后 n 行:n FOLLOWING

# 2. rows & range
range是逻辑窗口,是指定当前行对应值的范围取值,行数不固定,
只要行值在范围内,对应列都包含在内。
rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算
(与当前行的值无关,只与排序后的行号相关)。
“ROWS” 是按照行数进行范围定位的,
而“RANGE”则是按照值范围进行定位的,
这两个不同的定位方式 主要用来处理并列排序的情况 前后遇到相同的值的时候会进行累加
# 3.partition by & order by的组合
同时存在
spark.sql(""" SELECT cookieid, createtime, pv, SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS pv1 FROM t1 """).show
正常显示
- partition by出现
spark.sql("""
SELECT cookieid, createtime, pv,
SUM(pv) OVER(PARTITION BY cookieid ) AS pv1
FROM t1
""").show
没有排序仅分组内没有一个个迭代计算
都是分组的计算值
order by 出现 只有排序 两两相加再加上,上一个的和(两两是计算机分组的数)
都没有 显示总计算值
# 4. 排名函数
row_number() 是没有重复值的排序(即使两行记录相等也是不重复的) rank() 是跳跃排序,两个第二名下来就是第四名 dense_rank() 是连续排序,两个第二名仍然跟着第三名 NTILE(n),用于将分组数据按照顺序切分成n片
spark.sql("""
SELECT cookieid, createtime, pv,
row_number() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1,
rank() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank2,
dense_rank() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank3,
ntile(3) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank4
FROM t1
""").show
# 5. 行函数:lag、lead
lag(field, N) 取前N行的值
lead(field, N) 取后N行的值
注意:取前/后N行的值是当前行往前/后数第n行的值
first_value,取分组内排序后,截止到当前行,第一个值
根据组内排序获得第一行的
last_value,取分组内排序后,截止到当前行,最后一个值
也就是当前行的值
spark.sql("""
select cookieid, createtime, pv,
lag(pv) over (PARTITION BY cookieid ORDER BY pv) as col1,
lag(pv, 1) over (PARTITION BY cookieid ORDER BY pv) as col2,
lag(pv, 2) over (PARTITION BY cookieid ORDER BY pv) as col3
from t1
order by cookieid""").show
spark.sql("""
select cookieid, createtime, pv,
lead(pv) over (PARTITION BY cookieid ORDER BY pv) as col1,
lead(pv, 1) over (PARTITION BY cookieid ORDER BY pv) as col2,
lead(pv, 2) over (PARTITION BY cookieid ORDER BY pv) as col3
from t1
order by cookieid""").show
spark.sql("""
select cookieid, createtime, pv,
lead(pv, -2) over (PARTITION BY cookieid ORDER BY pv) as col1,
lag(pv, 2) over (PARTITION BY cookieid ORDER BY pv) as col2
from t1
order by cookieid""").show
# 6. first_value、last_value
first_value,取分组内排序后,截止到当前行,第一个值 根据组内排序获得第一行的 last_value,取分组内排序后,截止到当前行,最后一个值 也就是当前行的值
// first_value,取分组内排序后,截止到当前行,第一个值
spark.sql("""
SELECT cookieid, createtime, pv,
row_number() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1,
first_value(createtime) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank2,
first_value(pv) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank3
FROM t1
""").show
// last_value,取分组内排序后,截止到当前行,最后一个值
spark.sql("""
SELECT cookieid, createtime, pv,
row_number() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1,
last_value(createtime) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank2,
last_value(pv) OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank3
FROM t1
""").show
// 备注:lag、lead、first_value、last_value 不支持窗口子句
# 7.合并记录(collect_set,concat_ws,collect_list)
都是内置的函数
concat_ws:实现多行记录合并成一行
collect_set:对记录去重
collect_list:不对记录去重 案例:
案例:
case class UserAddress(userid:String, address:String)
val userinfo = Seq(UserAddress("a", "address1"), UserAddress("a", "address2"), UserAddress("a", "address2"), UserAddress("b", "address3"), UserAddress("c", "address4"))
val ds1 = spark.createDataset(userinfo)
ds1.createOrReplaceTempView("t1")
// SQL语句
val df2 = spark.sql("""
select userid, concat_ws(';', collect_set(address)) as addSet,
concat_ws(',', collect_list(address)) as addList,
collect_list(address) as addSet1,
collect_list(address) as addList1
from t1
group by userid
""")
df2.printSchema
df2.show
// DSL语法
ds1.groupBy($"userid").
agg(collect_list($"address").alias("address1"),
collect_set($"address").alias("address2")).show
# 8.展开记录(explode)

//合并
val ds2 = ds1.groupBy($"userid").agg(collect_set($"address") as "address")
// 拆分
// SQL语句
ds2.createOrReplaceTempView("t2")
// explode:将一行中复杂的array或者map结构拆分成多行
spark.sql("select userid, explode(address) from t2").show
// DSL语法
ds2.select($"userid", explode($"address")).show
# 9.left semi & anti join
半连接:左半连接实现了类似in、exists的查询语义,输出符合条件的左表内容;
反连接:两表关联,只返回主表的数据,并且只返回主表与子表没关联上的数据,这种连接就叫反连接。反连接一般就是指的 not in 和 not exists;
// 等价的SQL(左半连接、in、exists)这几个等价
// 效率最低
sql("""
(select id from t1
intersect
select id from t2)
order by id
""").show
spark.sql("""
select t1.id
from t1 left semi join t2 on (t1.id=t2.id)
""").show
spark.sql("""
select t1.id
from t1
where t1.id in (select id from t2)
""").show
spark.sql("""
select t1.id
from t1
where exists (select id from t2 where t1.id = t2.id)
""").show
备注:三条查询语句使用了相同的执行计划

// 等价的SQL(左反连接、in、exists)
spark.sql("""
select t1.id
from t1 left anti join t2 on (t1.id=t2.id)
""").show
spark.sql("""
select t1.id
from t1
where t1.id not in (select id from t2)
""").show
spark.sql("""
select t1.id
from t1
where not exists (select id from t2 where t1.id = t2.id)
""").show
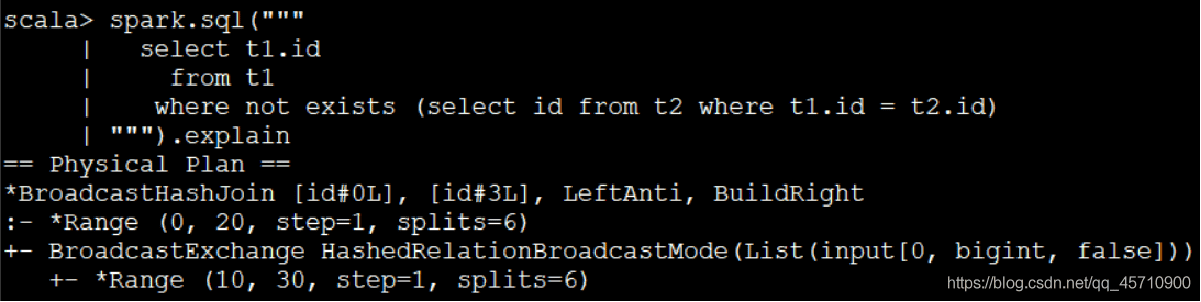 备注:
- 1、Hive在0.13版本中才实现(not) in/exists功能。在低版本的Hive中只能使用left semi/anti join;
- 2、传统的数据库中,历史上exists先执行外层查询,再执行内层查询,与in相反;现在的优化引擎一般情况下能够做出正确的选择;
- 3、在数据量小的情况下,三者等同。数据量大推荐使用join,具体还要看执行计划
备注:
- 1、Hive在0.13版本中才实现(not) in/exists功能。在低版本的Hive中只能使用left semi/anti join;
- 2、传统的数据库中,历史上exists先执行外层查询,再执行内层查询,与in相反;现在的优化引擎一般情况下能够做出正确的选择;
- 3、在数据量小的情况下,三者等同。数据量大推荐使用join,具体还要看执行计划
# 四.UDF
UDF: 自定义函数。函数的输入、输出都是一条数据记录,类似于Spark SQL中普通的数学或字符串函数,从实现上看就是普通的Scala函数; 为了解决一些复杂的计算,并在SQL函数与Scala函数之间左右逢源 UDF的参数视为数据表的某个列; 书写规范:
# 1.注册版
1. import spark.implicits._
2. def funName(参数:类型)={函数体} //自定义函数
3. spark.udf.register(“fun1”, funName _ )
fun1 :是sql中要用的函数
funName _ :自定义的函数名+空格+下划线
// 注册函数
4)val x=spark.sql(“select id, fun1(colname) from tbName ”)
# 2.非注册版
1. import org.apache.spark.sql.functions._
import spark.implicits._
2. val fun2=udf((参数:类型,length:Int)=>参数.length>length)
3. val getData=DataFrame类型数据.filter(fun2($ ”参数”,lit(10)))
$ : 可以接收的数据会当成Column对象($符号来包裹一个字符串表示一个Column)
当不用注册时要有udf包住自定义函数—>udf函数
# 3. 案例
import org.apache.spark.sql.{Row, SparkSession}
object UDFDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("UDFDemo")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val data = List(("scala", "author1"), ("spark", "author2"), ("hadoop", "author3"), ("hive", "author4"), ("strom", "author5"), ("kafka", "author6"))
val df = spark.createDataFrame(data).toDF("title", "author")
df.createTempView("books")
// 定义函数并注册
def len1(bookTitle: String):Int = bookTitle.length
spark.udf.register("len1", len1 _)
// UDF可以在select语句、where语句等多处使用
spark.sql("select title, author, len1(title) from books").show
spark.sql("select title, author from books where len1(title)>5").show
// UDF可以在DataFrame、Dataset的API中使用
import spark.implicits._
df.filter("len1(title)>5").show
// 不能通过编译
//df.filter(len1($"title")>5).show
// 能通过编译,但不能执行
//df.select("len1(title)").show
// 不能通过编译
//df.select(len1($"title")).show
// 如果要在DSL语法中使用$符号包裹字符串表示一个Column,需要用udf方法来接收函数。这种函数无需注册
import org.apache.spark.sql.functions._
val len2 = udf((bookTitle: String) => bookTitle.length)
df.filter(len2($"title")>5).show
df.select(len2($"title")).show
// 不使用UDF
df.map{case Row(title: String, author: String) => (title, author, title.length)}.show
spark.stop()
}
}
# 五. UDAF
UDAF :用户自定义聚合函数。函数本身作用于数据集合,能够在聚合操作的基础上进行自定义操作(多条数据输入,一条数据输出);类似于在group by之后使用的sum、avg等函数
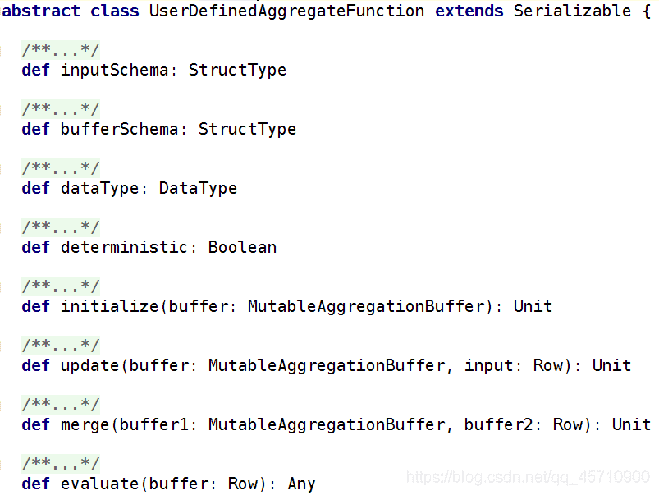

abstract class UserDefinedAggregateFunction extends Serializable{
def inputSchema : StructType
//inputSchema用于定义与DataFrame列有关的输入样式
def bufferSchema : StructType
//bufferSchema用于定义存储聚合运算时产生的中间数据结果的Schema;
def dataType : DataFrame
//dataType标明了UDAF函数的返回值类型;
def deterministic : Boolean
//deterministic是一个布尔值,用以标记针对给定的一组输入,UDAF是否总是生成相同的结果;
def initialize ( buffer : MutableAggregationBuffer) : Unit
//initialize对聚合运算中间结果的初始化;
def update ( buffer : MutableAggregationBuffer , input :Row) :Unit
//update函数的第一个参数为bufferSchema中两个Field的索引,默认以0开始;
UDAF的核心计算都发生在update函数中;
update函数的第二个参数input: Row对应的并非DataFrame的行,
而是被inputSchema投影了的行;
def merge (buffer1 : MutableAggregationBuffer , buffer2 : Row):Unit
//merge函数负责合并两个聚合运算的buffer,再将其存储到MutableAggregationBuffer中;
def evluate ( buffer :Row ): Any
//evaluate函数完成对聚合Buffer值的运算,得到最终的结果
}
普通的UDF不支持数据的聚合运算。如当要对销售数据执行年度同比计算,就需要对当年和上一年的销量分别求和,然后再利用同比公式进行计算。
书写UDAF 先继承UserDefinedAggregateFunction接口
在重写他的方法
def update ( buffer : MutableAggregationBuffer , input :Row) :Unit
// UDAF的核心计算都发生在update函数中。
// 扫描每行数据,都会调用一次update,输入buffer(缓存中间结果)、input(这一行的输入值)
// update函数的第一个参数为bufferSchema中两个Field的索引,默认以0开始
// update函数的第二个参数input: Row对应的是被inputSchema投影了的行。
// 本例中每一个input就应该只有两个Field的值,input(0)代表销量,input(1)代表销售日期
# 案例
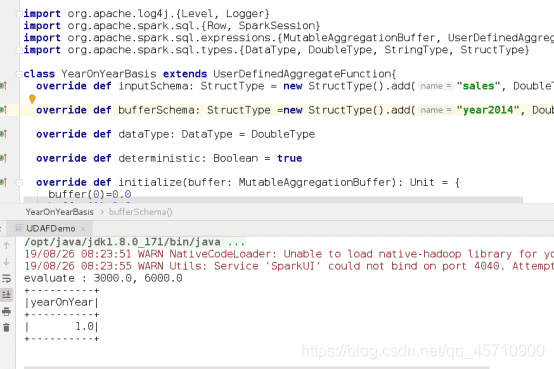
class YearOnYearBasis extends UserDefinedAggregateFunction {
// UDAF与DataFrame列有关的输入样式
override def inputSchema: StructType
= new StructType()
.add("sales", DoubleType)
.add("saledate", StringType)
// UDAF函数的返回值类型
override def dataType: DataType = DoubleType
// 缓存中间结果
override def bufferSchema: StructType
= new StructType()
.add("year2014", DoubleType)
.add("year2015", DoubleType)
// 布尔值,用以标记针对给定的一组输入,UDAF是否总是生成相同的结果。通常用true
override def deterministic: Boolean = true
// initialize就是对聚合运算中间结果的初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0.0
buffer(1) = 0.0
}
// UDAF的核心计算都发生在update函数中。
// 扫描每行数据,都会调用一次update,输入buffer(缓存中间结果)、input(这一行的输入值)
// update函数的第一个参数为bufferSchema中两个Field的索引,默认以0开始
// update函数的第二个参数input: Row对应的是被inputSchema投影了的行。
// 本例中每一个input就应该只有两个Field的值,input(0)代表销量,input(1)代表销售日期
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
val salenumber = input.getAs[Double](0)
input.getString(1).take(4) match {
case "2014" => buffer(0) = buffer.getAs[Double](0) + salenumber
case "2015" => buffer(1) = buffer.getAs[Double](1) + salenumber
case _ => println("ERROR!")
}
}
// 合并两个分区的buffer1、buffer2,将最终结果保存在buffer1中
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getDouble(0) + buffer2.getDouble(0)
buffer1(1) = buffer1.getDouble(1) + buffer2.getDouble(1)
}
// 取出buffer(缓存的值)进行运算,得到最终结果
override def evaluate(buffer: Row): Double = {
println(s"evaluate : ${buffer.getDouble(0)}, ${buffer.getDouble(1)}")
if (buffer.getDouble(0) == 0.0) 0.0
else (buffer.getDouble(1) - buffer.getDouble(0)) / buffer.getDouble(0)
}
}
object UDAFDemo {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val spark = SparkSession.builder()
.appName(s"${this.getClass.getCanonicalName}")
.master("local[*]")
.getOrCreate()
val sales = Seq(
(1, "Widget Co", 1000.00, 0.00, "AZ", "2014-01-02"),
(2, "Acme Widgets", 2000.00, 500.00, "CA", "2014-02-01"),
(3, "Widgetry", 1000.00, 200.00, "CA", "2015-01-11"),
(4, "Widgets R Us", 2000.00, 0.0, "CA", "2015-02-19"),
(5, "Ye Olde Widgete", 3000.00, 0.0, "MA", "2015-02-28") )
val salesDF = spark.createDataFrame(sales).toDF("id", "name", "sales", "discount", "state", "saleDate")
salesDF.createTempView("sales")
val yearOnYear = new YearOnYearBasis
spark.udf.register("yearOnYear", yearOnYear)
spark.sql("select yearOnYear(sales, saleDate) as yearOnYear from sales").show()
spark.stop()
}
}
# 六. 从MySQL读取数据
// 读取数据库中的数据
val jdbcDF = spark.read.format("jdbc").
option("url", "jdbc:mysql://localhost:3306/spark").
option("driver","com.mysql.jdbc.Driver").
option("dbtable", "student").
option("user", "hive").
option("password", "hive").load()
jdbcDF.show
jdbcDF.printSchema
备注:
- 1、将jdbc驱动拷贝到
$SPARK_HOME/jars目录下,是最简单的做法; - 2、明白每一个参数的意思,一个参数不对整个结果出不来;
- 3、从数据库从读大量的数据进行分析,不推荐;读取少量的数据是可以接受的,也是常见的做法。
# 参考文章
- https://blog.csdn.net/qq_45710900/article/details/102560025










