TIP
本文主要是介绍 Spark-大数据分析精华总结 。
# Spark快速大数据分析
# 楔子
Spark快速大数据分析 前3章内容,仅作为学习,有断章取义的嫌疑。如有问题参考原书
# Spark快速大数据分析
以下为了打字方便,可能不是在注意大小写
# 1 Spark数据分析导论
# 1.1 Spark是什么
Spark是一个用来实现快速而通用的集群计算的平台。
在速度方面,Spark扩展了广泛使用的MapReduce计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。在处理大规模数据集事,速度是非常重要的。速度就以为这我们可以进行交互式的数据操作,否则我们每次操作就需要等待数分钟甚至数小时。Spark的一个主要特征就是能够在内存中计算,因而更快。不过即便是必须在磁盘上进行复杂计算,也比MapReduce更加高效。
总的来说,Spark使用各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark使我们可以简单而低耗地把各种处理流程整合在一起。。而这样的组合,在实际的数据分析过程中很有意义。不仅如此,Spark的这种特性还大大减轻了原先需要对各种平台分别管理的负担。
Spark所提供的接口非常丰富。除了提供基与Python,Java、Scala和SQL的简单易用的API以及内建的丰富程序库以外,spark还能和其他大数据工具密切配合使用。
# 1.2 一个大一统的软件栈
Spark项目包含多个紧密集成的组件。Spark的核心是一个对由很多计算任务组成的、运行在多个机器或者一个计算集群上的应用进行调度、分布以及监控的计算引擎。由于Spark的核心引擎有着速度快和通用的特点,因此Spark还支持为各种不同场景专用设计的高级组件,比如SQL和机器学习等。这些组件关系密切并且可以相互调用,这样你就可以像平常软件项目中使用程序那样,组合使用这些的组件。
各组件密切结合的设计原理有这样几个有点。首先,软件栈中所有程序库和高级组件都可以从下层的改进中获益。比如,当Spark的核心引擎新引入一个优化时,SQL和机器学习程序库都能自动获得性能提升。其次,运行整个软件栈的代价变小了。不需要运行5到10套独立的软件系统了,一个机构只需要运行一套软件系统即可。这些代价包括系统的部署、维护、测试、支持等。这也意味着Spark软件栈中每增加一个新的组件,使用spark的机构都能马上试用新加入的组件。这就把原先尝试一种新的数据分析系统所需要的下载、部署并学习一个新软件项目的代价转化为了只需要升级spark。
最后。密切结合的原理的一大优点就是,我们能够构建出无缝整合不同处理模型的应用。例如,利用spark,你可以在一个应用中实现将数据流中数据使用机器学习算法进行实时分类。与此同时,数据分析师也可以通过SQL实时查询结果数据,比如将数据与非结构化的日志文件进行连写操作。不仅如此,有经验的数据工程师和数据科学家还可以通过Python shell 来访问这些数据,进行及时分析。其他人也可以通过独立的批处理应用访问这些数据。IT团队始终只需要维护一套系统即可。

# 1.2.1 Spark Core
spark core实现了spark的基本功能,包含了任务调度、内存管理、错误恢复、与储存系统交互等模块。它还包含了对弹性分布式数据集(简称RDD)的API定义。RDD表示分布在多个计算节点上可以并行操作的元素集合,是Spark主要的编程抽象。Spark core 提供了创建和操作这些集合的多个API。
# 1.2.2 Spark SQL
Spark SQL 是 spark用来操作机构化数据的程序包。通过spark sql,我们可以使用sql或者 hive 来查询数据,spark SQL支持多种数据源,比如hive parquet以及json等。除了spark提供了一个sql接口,spark sql还支持开发者将SQL和传统的RDD编程的数据操作方式结合,不论是使用Python、Java还是Scala,开发者都可以讲单个应用中同时使用SQL和复杂的数据分析。通过与spark所提供的丰富的计算环境进行如此紧密的结合,spark sql得以从其他开源数据仓库工具中脱颖而出。
# 1.2.3 Spark Streaming
spark streaming 是spark提供的对实时数据进行流式计算的组件。比如生产环境中的网页服务器日志,或是网络服务中用户提交的状态更新组成的消息队列。都是数据流。spark streaming提供了用来操作数据流的API,并且与spark core中的RDD API高度对应。这样一来,程序员编写应用时学习的门槛就得以降低。从底层来看,sparkstream 支持与spark core同级别的容错性、吞吐以及可伸缩性。
# 1.2.4 MLib
spark 中还包含一个提供常见的机器学习(ML)功能的程序库,叫做MLlib,它提供了很多机器学习算法,包括分类,回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。MLlib还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化算法。所有这些方法都被实际为可以在集群上轻松伸缩的结构。
# 1.2.5 GrapX
它是用来操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算。与Spark streaming和spark SQL类似,GrapX也扩展了RDD的API,能用来创建一个顶点和边都包含任意属性的有向图。GrapX还支持各针对图的操作以及一些常用图算法。
# 1.3 spark的用户和用途
spark是一个用于集群计算的通用计算框架,因此被用于各种各样的应用程序。
spark应用在数据科学和数据处理应用。
# 1.6 Spark的储存层次
Spark不仅可以将任何Hadoop分布式文件系统HDFS上的文件读取为分布式数据集,也可以支持其他Hadoop接口的系统,比如本地文件、亚马逊S3,hive 、hbase等。hadoop并非spark的必要条件,spark支持任何实现了hadoop接口的存储系统,spark支持的hadoop输入格式包括文本文件、sequencefile、Avro、Parquet等
# 2 spark下载入门
spark本身是用Scala写的。
spark1.4.0 起支持了R语言
Spark1.4.0 起支持了Python3
下面操作是基于Windows操作的。操作和代码仅限于Java
# 2.2spark中的shell
上述操作仅仅是解压后执行.\bin\spark-shell出现的。下载后没配置任何文件
Windows上命令行可以尝试使用cmder这款工具
Scala统计行数
scala> val lines=sc.textFile("README.md")### 创建一个名为lines的RDD
scala> lines.count()## 统计RDD中元素的个数
res2: Long = 3
scala> lines.first()#这个RDD中第一个元素,也就是第一行
res5: String = ## Apache Spark
要退出任一shell CTRL+D
# 2.3 Spark核心概念简介
从上层来看,每个Spark应用都由一个驱动器程序来发起集群上的各种并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作,在前面的例子中。实际的驱动器程序就是Spark shell本身,只要输入想要运行的操作就可以了。
驱动器程序通过一个SparkContext对象来访问Spark。这个对象代表计算集群的一个连接。shell启动时已经自动创建了一个SparkContext对象,是一个叫做sc的变量。可以通过下面的方法尝试输出sc来查看它的类型
scala> sc
res6: org.apache.spark.SparkContext = org.apache.spark.SparkContext@5dd1526e
一旦有了SparkContext,你就可以用它来创建RDD。sc.textFile()来创建一个代表文件中各行文本的RDD。我们可以在这些行上进行各种操作。
要执行这些操作,驱动器程序一般要管理多个执行器节点。比如,如果我们在集群上运行count操作,那么不同的节点会统计文件的不同部分的行数。由于我们刚才是在本地模式运行Spark shell。因此所有的工作会在单个节点上执行,如果将这个shell连接到集群上来进行并行的数据分析,下图展示Spark如何在一个集群上运行。
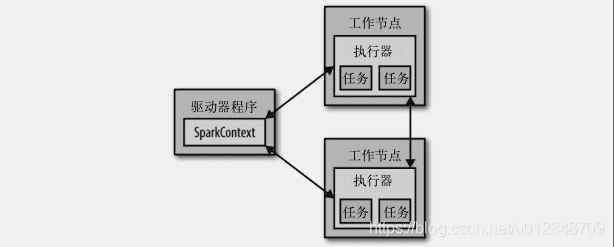
最后,我们有很多用来传递函数的API,可以将对应操作运行在集群上
Scala版筛选的例子
scala> var lines=sc.textFile("README.md")
lines: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[15] at textFile at <console>:24
scala> var pythonLines=lines.filter(line=>line.contains("Python"))
pythonLines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[16] at filter at <console>:26
scala> pythonLines.first()
res8: String = high-level APIs in Scala, Java, Python, and R, and an optimized engine that
向Spark传递参数
上述例子中的lambda或者==>语法不熟悉,后面介绍。
# 2.4 独立应用
除了交互式应用之外,Spark也可以在Java、Scala或者Python的独立程序中被连接使用,这些与shell中使用主要区别是你要自行初始化SparkContext。
我使用的是spark2.1.1版本,其他语言我不涉及,我下面仅仅是Java版本
# 2.4.1 初始化SaprkContext
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
public class SparkDemo {
static SparkConf conf;
static JavaSparkContext sc;
/**
* 初始化sparkContext
*
*/
static {
// TODO 创建SparkContext
// 的最基本方法,只需要传递2个参数https://www.cnblogs.com/Forever-Road/p/7351245.html
/**
* 1:集群URL 告诉spark如何连接到集群上,这个实例中使用local,这个特殊的值可以让spark运行在
* 单机单线程上而不需要连接到集群 2:应用名:当连接到一个集群时,这个值可以帮助你在集群管理器的用户界面中找到你的应用
*/
conf = new SparkConf().setMaster("local").setAppName("sparkDemo");
sc = new JavaSparkContext(conf);
}
public static void main(String[] args) {
System.out.println(sc);
}
}
/**
* 关闭spark
*/
public static void closeContext() {
sc.close();
// 或者
System.exit(0);
}
spark官方快速入门指南 (opens new window)
# 2.4.2 构建独立应用
下面是一个用sb以及meavn来构建并打包一个简单的统计单词的过程。
package cn.zhuzi.spark;
import java.io.File;
import java.io.IOException;
import java.util.Arrays;
import java.util.Iterator;
import org.apache.commons.io.FileUtils;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
/**
* @Title: SparkDemoWordCount.java
* @Package cn.zhuzi.spark
* @Description: TODO(spark 统计单词)
* @author 作者 grq
* @version 创建时间:2018年11月15日 下午2:54:44
*
*/
public class SparkDemoWordCount {
public static void main(String[] args) throws IOException {
String base_path = "E:/had/spark/";
String inputPath = base_path + "12.txt";
String outputpath = base_path + "out/a_wc";
File file = FileUtils.getFile(outputpath);
if (file.exists()) {
FileUtils.deleteDirectory(file);
}
wordCount(inputPath, outputpath);
}
@SuppressWarnings("serial")
public static <U> void wordCount(String inputPath, String outputpath) {
// 创建spark context
JavaSparkContext sc = SparkUtils.getContext();
// 读取输入的数据
JavaRDD<String> input = sc.textFile(inputPath);
// 切分为单词
JavaRDD<String> words = input.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String t) throws Exception {
Iterator<String> iterator = Arrays.asList(t.split(" ")).iterator();
return iterator;
}
});
// 转换为键值对并基数
JavaPairRDD<String, Integer> counts = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String t) throws Exception {
return new Tuple2<String, Integer>(t, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer x, Integer y) throws Exception {
return x + y;
}
});
// 输出到文件。文件必须不存在
counts.saveAsTextFile(outputpath);
sc.close();
}
}
package cn.zhuzi.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
/**
* @Title: SparkUtils.java
* @Package cn.zhuzi.spark
* @Description: TODO(SparkUtils )
* @author 作者 grq
* @version 创建时间:2018年11月15日 下午2:49:33
*
*/
public class SparkUtils {
static SparkConf conf;
static JavaSparkContext sc;
/**
* 初始化sparkContext
*
*/
static {
// TODO 创建SparkContext
// 的最基本方法,只需要传递2个参数https://www.cnblogs.com/Forever-Road/p/7351245.html
/**
* 1:集群URL 告诉spark如何连接到集群上,这个实例中使用local,这个特殊的值可以让spark运行在
* 单机单线程上而不需要连接到集群
* <p/>
* 2:应用名:当连接到一个集群时,这个值可以帮助你在集群管理器的用户界面中找到你的应用
*/
buildContext();
}
private static void buildContext() {
conf = new SparkConf().setMaster("local").setAppName("sparkDemo");
sc = new JavaSparkContext(conf);
}
/**
* 关闭spark
*/
public static void closeContext() {
sc.close();
// 或者
System.exit(0);
}
private SparkUtils() throws Exception {
throw new Exception("不允许实例化工具类");
}
public static JavaSparkContext getContext() {
if (sc == null) {
buildContext();
}
return sc;
}
}
但是在书中,看着代码比Scala的代码多多了,Scala代码反而简单
书在 40页
# 3 RDD编程
RDD对数据的核心抽象——弹性分布式数据集(简称RDD)。RDD其实就是分布式的元素集合。在Spark中,对数据的所有操作不外乎创建RDD,转化已有的RDD以及调用RDD操作进行求值,而这一切的背后,Spark会自动将RDD中的数据分发到集群上,并操作并行执行。
# 3.1RDD基础
Spark中RDD就是一个不可变的分布式对象集合,每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上,RDD包括Python、Java、Scala中任意类型的对象,甚至可以包含用户自定义的对象。
用户创建RDD的两个方法:读取一个外部数据集,或在驱动器程序里分发驱动器程序中的对象集合(例如list 和set)。
创建出来RDD后,支持两种类型的操作:转化操作和行动操作。
转化操作会由一个RDD生成一个新的RDD。
行动操作会对RDD计算一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储启动中。
默认情况下,spark的RDD会在每次对他们进行行动操作是重新计算,如果想在多个行动操作中重用一个RDD,可以使用RDD.persist()让Spark把这个RDD换成下载。我们可以把数据持久化到许多不同的地方
实际的操作中,经常会使用persist把数据的一部分读取到内存中,并反复查询这部分数据。
# 3.2 创建RDD
spark提供了两种创建RDD的方式:读取外部数据集,以及在驱动器程序中对一个集合进行并行化。
创建RDD最简单的方式就是把程序中一个已有的集合传递SparkContext的parallelize方法。然后对这些RDD进行操作,不过,除了开发原型和测试时,这种方法使用的不多。
Scala方法中的parallelize
scala> var lines=sc.parallelize(List("panda","shuai"))
java中的parallelize
JavaRDD<String> parallelize = sc.parallelize(Arrays.asList("shuai", "feng"));
# 3.3 RDD操作
RDD的操作:转化和行动操作
# 3.3.1转化操作
RDD的转化是返回新RDD的操作。转化出来的RDD是惰性求值的,只有在行动操作中用到这些RDD时才会被计算。许多转化操作都是针对各个元素的,也就是说,这些转化操作每次只会操作RDD中一个元素。不过并不是所有的转化操作都是这样的。
Java实现filter转化操作
public static void main(String[] args) {
JavaRDD<String> textFile = sc.textFile(base_path + readmeFile);
JavaRDD<String> filter = textFile.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String v1) throws Exception {
return v1.contains("Python");
}
});
closeContext();
}
/**
* 关闭spark
*/
public static void closeContext() {
sc.close();
// 或者
System.exit(0);
}
filter操作不会改变已有的textFile中的数据,实际上,该操作会返回一个全新的RDD,textFile会在后面的程序中继续使用,比如我们可以从中搜索个别单词。
通过已有的RDD派生出来的新的RDD,spark会使用谱系图来记录这些不同的RDD之间的依赖关系,Spark需要用这些信息来按需计算每个RDD,也可以依赖谱系图在持久化的RDD丢失部分数据时恢复所丢失的数据。谱系图 如下
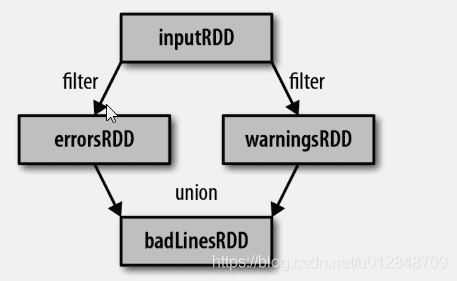
# 3.3.2 行动操作
Java中使用行动操作对错误进行技术
/**
* 统计包含INFO的行数
*
* @throws IOException
*/
public static void infoCount() throws IOException {
File asFile = Resources.getResourceAsFile("info.txt");
JavaRDD<String> inputRDD = sc.textFile(asFile.getAbsolutePath());
JavaRDD<String> infoRDD = inputRDD.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String x) throws Exception {
return x.contains("INFO");
}
});
System.out.println("包含INFO的行数有:" + infoRDD.count());
// INFO的行数是38行,下面的数字40>38程序不会报错,只是打印了全部包含INFO的行
for (String line : infoRDD.take(40)) {
System.out.println(line);
}
}
使用take()获取了RDD中的小量元素,然后在本地遍历,并在驱动器端打印出来。RDD还有一个collect函数,用来获取整个RDD的数据。如果你的程序把RDD筛选到一个很小的规模,并且你想在本地处理这事数据时,就可以使用它。记住,只有当你的整个数据集能在单台机器的内存放得下时,才能使用collect,因此collect不能用在大规模数据集上
多数情况下,RDD不能通过collect手记到驱动器进程中,因为他们一般很大。因此,通常要把数据写到存储诸如HDFS等分布式文件系统中。或者保存为任各种带格式。
# 3.3.3 惰性求值
惰性求值意味着当我们对RDD调用转化操作时,操作不会立即执行,相反,spark会内部记录下所要求执行的操作相关信息。我们不应该把RDD看做存放特定数据的数据集,而最好把每个RDD当做我们转化操作构建出来的,记录如何计算数据的指令列表。
# 3.4 向Spark传递函数
spark的大部分转化操作和一部分行动操作,都需要依赖用户传递的函数来计算。
# 3.4.1 Java中

在Java中使用匿名内部类传递函数
/**
* Java中使用匿名内部类进行函数传递
*/
public static void fun1() {
JavaRDD<String> textFile = sc.textFile(base_path);
JavaRDD<String> filter = textFile.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String v1) throws Exception {
return v1.contains("Python");
}
});
}
在Java中使用具名类进行函数传递
/**
* 在Java中使用具名类进行函数传递
* <p/>
* 顶级具名类通常在组织大型程序时显得比较清晰,使用顶级函数的另一个好处是 可以给他们的构造函数添加参数
*/
public static void fun2() {
JavaRDD<String> lines = sc.textFile(base_path);
JavaRDD<String> filter = lines.filter(new ContainsStr("Python"));
}
}
class ContainsStr implements Function<String, Boolean> {
private String query;
public ContainsStr(String query) {
this.query = query;
}
@Override
public Boolean call(String v1) throws Exception {
return v1.contains(query);
}
}
在Java8中使用lamdba表达式进行函数传递
/**
* 在Java8中使用lamdba表达式进行函数传递
*/
public static void fun3() {
JavaRDD<String> lines = sc.textFile(base_path);
lines.filter(s -> s.contains("Python"));
}
匿名类和lamdba表达式都可以应用方法中封装的任意final变量,因此可以像Python和Scala中一样把这些变量传递给spark
# 3.5 常见的转化操作和行动操作
# 3.5.1 基本RDD
先讲述哪些转化操作和行动操作受任意数据类型的RDD支持
# 1 针对各个元素的转化操作
最常用的转化操作是map()和filter()。转化操作map接收一个函数,把这个函数用于RDD中的每个元素,将函数返回的结果作为结果RDD中对应元素的值。而转化操作filter()则接收一个函数,并将RDD中满足该函数的元素放入新的RDD中返回。如下图
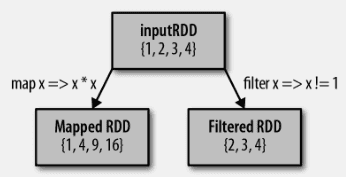
我们可以使用map()来做 各种各样的事情:可以把URL集合中每个RUL对应的主机名提取出来,也可以见到到只是针对各个数字求平方值。map()的返回值类型不需要和输入类型一样。
以下是一个简单的例子,用map()对RDD中所有数求平方
/**
* 计算RDD中各值得平方
*/
private static void calc() {
JavaSparkContext sc = SparkUtils.getContext();
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> result = rdd.map(x -> x * x);
System.out.println(StringUtils.join(result.collect(), " "));
}
有时候,我们希望每个输入元素生成多个输出元素。实现该功能的操作叫做flatMap()。和map()类似。我们提供给flatMap()的函数分别被应用到了输入RDD的每个元素上。不过返回的不是一个元素,而是一个返回值序列的迭代器。输出的RDD倒不是迭代器组成的。我们得到的是一个包含各个迭代器可以访问的所有元素的RDD。flatMap的一个简单用途就是把输入的字符串切割分为单词。例如下面
/**
* Java 中的 flatMap() 将行数据切分为单词
*/
public static void faltMap() {
JavaRDD<String> lines = sc.parallelize(Arrays.asList("hello Spark"));
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String t) throws Exception {
return Arrays.asList(t.split(" ")).iterator();
}
});
System.out.println(words.first());// hello
System.out.println(words.collect().toString());// [hello, Spark]
}
/**
* Java 中的 flatMap() 将行数据切分为单词 Lamdba版本
*/
public static void faltMapLamdba() {
JavaRDD<String> lines = sc.parallelize(Arrays.asList("hello Spark"));
JavaRDD<String> words = lines.flatMap(w -> Arrays.asList(w.split(" ")).iterator());
System.out.println(words.first());// hello
System.out.println(words.collect().toString());// [hello, Spark]
}
flatMap()和map()的区别。可以把flatMap()看做将返回的迭代器”拍扁“,这样就得到了一个由哥列表中的元素组成的RDD,而不是一个由列表组成的RDD。
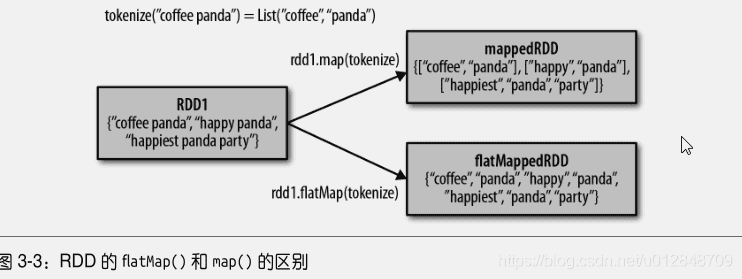
# 2 伪集合操作
尽管RDD本身不是严格意义上的集合,但他支许多数学上的结合操作。比如合并和相交操作。(这些操作都要求操作的RDD是相同的数据类型)
我们的RDD操作最常缺失的集合属性是元素的唯一性,因为常常有重复的元素。如果只要求唯一的元素。我们可以使用RDD.distinct()转化操作来生成一个只包含不同元素的新RDD。但是distinct()操作的开销恨到,因为它需要将所有的数据通过网络进行混洗(shuffle),以确保每个元素都只是1份。
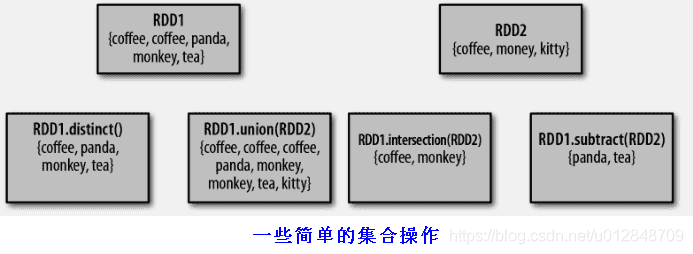
最简单的集合操作是union(other),它会返回一个包含两个RDD中所有元素的RDD。(如果有重复元素也会包含在内)
Spark还提供了intersection(other)方法。只返回两个RDD中都有的元素。它在运行时也会取消所有重复的元素(单个RDD内的重复元素也会一起移除)。intersection()因为要通过网络混洗来发现共有的元素,因此性能差很多。
subtract(other),返回一个由只存在第一个RDD中而不存在第二个RDD中所有元素组成的RDD,它也需要数据混洗。
对数据{1,2,3,3}的RDD基本RDD
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| map() | 将函数应用于RDD中的每个元素,将返回值构成新的RDD | rdd.map(x -> x + 1); | {2, 3, 4, 4} |
| flatMap() | 将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD。通常用来切分单词 | rdd.flatMap(x=>x.to (opens new window)(3)) | {1,2,3,2,3,3} |
| filter() | 返回一个由通过filter()的函数的元素组成的RDD | rdd.filter(x=x!=1) | {2,3,3} |
| distinct | 去重 | rdd.distinct() | {1,2,3} |
| sample | 对RDD采样,以及是否替换 | rdd.sample(false,0.5) | 非确定 |
scala> var ls=sc.parallelize(List(1,2,3,4))
scala> var res=ls.flatMap(x=>x.to(3))
scala> print(res.collect().mkString(","))
1,2,3,2,3,3
对数据分别为{1,2,3}和{3,4,5}的RDD进行针对两个RDD的转化操作
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| union | 生成一个包含两个RDD中所有元素的RDD | rdd.union(other) | {1,2,3,3,4,5} |
| intersection | 求两个RDD的共同元素的RDD | rdd.intersection(other) | {3} |
| subtract | 移除一个RDD中的内容 | rdd.suntract | {1,2} |
| cartesian | 与另一个RDD的笛卡尔积 | rdd.cartesian(other) | {(1,3),(1,4),……,(3,5)} |
# 3 行动操作
RDD最常用的行动操作reduce()。它接收一个函数作为参数,这个函数操作两个RDD的元素类型的数据返回一个同样类型的新元素。一个简单的例子流失函数+,可以用来对我们的RDD进行累加。使用reduce,可以方便的计算出RDD中所有元素的总和,元素的个数以及其他类型的聚合操作。

我总感觉 Java版本最复杂,Scala看着简单,要么就使用Java8的lamdba
fold和reduce类似,接收一个与reduce接收的函数签名相同的函数,在加上一个“初始值”来作为每个分区第一次调用的结果。
fold和reduce都要求函数的返回值类型需要和我们所操作的RDD中的元素类型相同,这很符合像sum这种操作的情况。但有时我么需要返回一个不同类型的值。例如,在计算平均值时,需要记录遍历过程中的计数以及元素的数量,这就需要我们返回一个二元组。我们先对数据使用map操作,把元素转化为该元素和1的二元组。这样reduce就可以以二元组的形式进行归约了。
aggregate函数则把我们发挥值类型必须与操作的RDD类型相同的限制中解放出来。与fold类似,使用该函数时,需要提供我们期待返回的类型的初始值。然后通过一个函数把RDD中的元素合并起来放入累加器,考虑到每个节点是本地进行累加的,最终,还需要提供第二个函数来将累加器两两合并。
此处aggregate没看懂,不清楚代码中的nums是怎么来的

RDD的一些行动操作会以普通集合或者值得形式将RDD的部分或全部数据返回驱动器程序中。
把数据返回驱动器程序中最简单、最常见的操作是collect,它会将整个RDD的内容返回,collect通常在单元测试中使用,因此此时RDD的整个内容不会很大,可以放在内存中,使用collect使得RDD的值与预期结果之间的对比变得很容易。由于需要将数据复制到驱动器进程中,collect要求所有数据都必须能一同放入单台机器内存中。
take(n)返回RDD中的n个元素,并且尝试值访问尽量少的分区,因此该操作会得到一个不均衡的集合。需要注意的是,这些操作返回的元素顺序和预期的可能不一致。
如果数据定义了顺序,就可以使用top()从RDD中获取前几个元素,top()会使用数据的默认顺序,但是我们可以提供了自己的比较函数,来提取前几个元素。
有时我们会对RDD中所有元素应用一个行动操作,但是不把任何结果返回到驱动器程序中,这也是有用的,比如可以用json格式把数据发送到一个网络服务上,或者把数据存储到数据库中。不论哪种情况,都可以使用foreach()行动操作来对RDD中的每个元素进行操作,而不需要把RDD发回本地。
对一个数据为{1,2,3,4}的RDD进行基本的RDD行动操作
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| collect() | 返回RDD中所有元素 | rdd.collect() | {1,2,3,3} |
| count() | RDD的个数 | rdd.count() | 4 |
| countByValue() | 各元素在RDD出现的次数 | rdd.countByValue() | {(1,1),(2,1),(3,2)} |
| take(num) | 从RDD中返回num个元素 | rdd.take(2) | {1,2} |
| top(num) | 从RDD中返回最前面的num个元素 | rdd.top(2) | {1,2} |
| takeOrdered(num)(ordering) | 从RDD中按照提供的顺序返回最前面的num个元素 | rdd.takeOrdered(2)(myOrdering) | |
| fold(zero)(func) | 和reduce一样,但是需要提供初始值 | rdd.fold(0)((x,y)=>x+y) | 9 |
| foreach(func) | 对RDD中每个元素使用给定的函数 | rdd.foreach(func) |
# 3.5.2 在不同的RDD类型间转换
我是记录Java相关
在Java中,各种RDD的特殊类型间的转化更为明确。Java中有两个专门的类JavaDoubleRDD和JavaPairRDD,来处理特殊类型的RDD。这两个针对对这些类型提供了额外的函数。
要构建出这些特殊类型的RDD,需要使用特殊版本的类来替代一般使用的Function类。如果从T类型的RDD创建出一个DoubleRDD。我们就应当在映射操作中使用DoubleFunction来替代Functon。
Java中针对专门类型的函数接口
| 函数名 | 等价函数 | 用途 |
| -------------------------- | --------------------------------- | ------------------------------------- |
| DoubleFlatMapFunction | Function<T,Iterable> | 用于flatMapToDouble,以生成DoubleRDD |
| DoubleFunction | Function<T,Double> | 用于mapToDouble,以及生成DoubleRDD |
| PairFlatMapFunction<T,K,V> | Function<T,Iterable<tUPLE2<k,v>>> | 用于flatMapToPair,以生成PairRDD<K,V> |
| PairFunction<T,K,V> | Function<T,Tuple2<K,V>> | 用于mapToPair,以生成PairRDD |
用Java创建DoubleRDD
public static void calcMap() {
JavaRDD<Integer> lines = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaDoubleRDD mapToDouble = lines.mapToDouble(x -> x * x);
System.out.println(mapToDouble.collect());// [1.0, 4.0, 9.0, 16.0]
System.out.println(mapToDouble.mean());// 7.5 这个值好像是上面的平均值
}
# 3.6 持久化
如前所述,Saprk RDD是惰性求值的。有时候我们希望多次使用同一个RDD。如果简单地对RDD调用行动操作,Spark每次都会重算RDD以及它的所有依赖,这些迭代算法中小号很大,因此迭代算法常常会多次使用同一组数据。
两次执行
/**
* 两次执行
*/
private void doucleCalc() {
JavaRDD<Integer> lines = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> result = lines.map(x -> x * 5);
System.out.println(result.count());
System.out.println(StringUtils.join(result.collect(), ","));
}
为了避免多次计算同一个RDD,可以让Spark对数据就行持久化。当我们让Spark持久化存储一个RDD时,计算出RDD的节点会分别保存他们所求出的分区数据。如果一个持久化数据的节点发送故障,Spark会在需要用到缓存的数据时重算丢失的数据分区,如果希望节点故障的情况不会拖累我们的执行速度,也可以把数据备份在多个节点上。
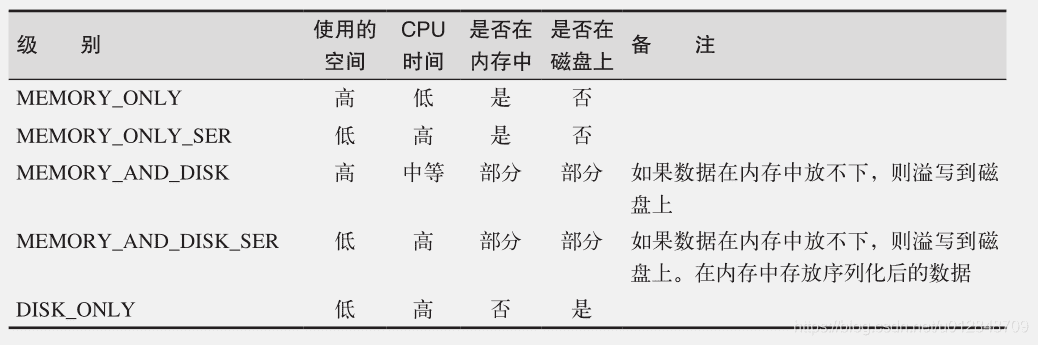
出于不同的目的,我们可以为RDD选择不同的持久化级别。
org.apache.spark.storage.StorageLevel 和 pyspark.StorageLevel 中的持久化级 别;如有必要,可以通过在存储级别的末尾加上“_2”来把持久化数据存为两份
private void doucleCalc() {
JavaRDD<Integer> lines = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> result = lines.map(x -> x * 5);
result.persist(StorageLevel.DISK_ONLY());
System.out.println(result.count());
System.out.println(StringUtils.join(result.collect(), ","));
}
RDD还有一个方法(unpersist),调用该方法可以手动把持久化的RDD从缓存中移除
# 楔子
Spark快速大数据分析 前3章内容,仅作为学习,有断章取义的嫌疑。如有问题参考原书
# 4 键值对操作
# 4.1 动机
Spark为包含键值对类型的RDD提供了一些专业的操作,这些RDD被称为pair RDD,Pair RDD是很多程序的构成要素,因为他们提供了并行操作各个键或跨节点重新进行数据分组的操作接口。例如:pair RDD提供了reduceByKey方法,可以分别归约每个键对应的数据,还有join方法,可以把两个RDD中键相同的元素组合到一起,合并为一个RDD,我们通常用一个RDD中提取某些字段,并使用这些字段作为pair RDD操作中的键。
# 4.2 创建Pair RDD
在Spark中很多种创建pair RDD的方法,很多存储键值对的数据会在读取时直接返回由键值对数据组成的pair RDD。此外,需要把一个普通的RDD转为pair RDD,可以调用map方法实现。
构建键值对对RDD的方法在不同的语言中会有所不同。
在Java中使用一个单词作为键创建一个pair RDD
/**
* java中使用一个单词作为键创建出一个Pair RDD
*/
public static void getPairRDD() {
PairFunction<String, String, String> keyData = new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String t) throws Exception {
return new Tuple2<String, String>(t.split(" ")[0], t);
}
};
JavaSparkContext sc = SparkUtils.getContext();
JavaRDD<String> lines = sc.parallelize(Arrays.asList("hello word", "spark good"));
JavaPairRDD<String, String> javaPairRDD = lines.mapToPair(keyData);
System.out.println(javaPairRDD.collect());
// [(hello,hello word), (spark,spark good)]
}
/**
* java中使用一个单词作为键创建出一个Pair RDD
* https://blog.csdn.net/leen0304/article/details/78743715
*/
public static void getPairRDDLamdba() {
JavaSparkContext sc = SparkUtils.getContext();
JavaRDD<String> lines = sc.parallelize(Arrays.asList("hello word", "spark good"));
// TODO 下面的语句 在new Tuple2 里面写 split 不自动提示,难道 lamdba有部分不提示吗?
JavaPairRDD<String, String> counts = lines.mapToPair(t -> (new Tuple2<String, String>(t.split(" ")[0], t)));
System.out.println(counts.collect());
// [(hello,hello word), (spark,spark good)]
}
当Scala和Python从一个内存中的数据集创建pair RDD时,只需要对这个由二元组组成的集合调用SparkContext.patallelize()方法。而要使用Java从内存数据集创建pair RDD的话,则需要使用SparkContext.parallelizePairs()。
# 4.3 Pair RDD的转化操作
Pair RDD可以使用所有标准RDD上的可用额转化操作,之前描述的有关传递函数的规则也适用于 pair RDD。由于 Pair RDD中包含二元组,所以需要传递的函数应当操作二元组而不是独立的元素。
Java中对第二个元素进行筛选
/**
* 对第二个元素进行筛选
*/
public static void selectPairRDD() {
JavaPairRDD<String, String> pairRDD = getPairRDDLamdba();
JavaPairRDD<String, String> filter = pairRDD.filter(new Function<Tuple2<String, String>, Boolean>() {
@Override
public Boolean call(Tuple2<String, String> v1) throws Exception {
return v1._2().length() < 20;
}
});
System.out.println(filter.collect());
// [(hello,hello word), (spark,spark good)]
}
/**
* 对第二个元素进行筛选
*/
public static void selectPairRDDlamdba() {
JavaPairRDD<String, String> pairRDD = getPairRDDLamdba();
// TODO 下面的语句 eclipse没提示?
JavaPairRDD<String, String> filter = pairRDD.filter(t -> t._2().length() < 20);
// [(hello,hello word), (spark,spark good)]
System.out.println(filter.collect());
}
有时,我们只是想访pair RDD的值部分,这是操作二组很麻烦。由于这是一种常见的使用模式,因此Spark提供了mapValues(func)函数,功能类似于map{case (x,y):x,func(y))}
下面依次讨论pairRDD的各种操作
# 4.3.1聚合操作
当数据集以键值对形式组织的时候,聚合具有相同键的元素进行一些统计是很常见的操作。之前讲过在RDD上的fold、combine()、reduce()等操作,pair RDD上则有相应的针对键的转化操作,Spark有一组类似的操作,可以组合具有相同键的值。这些操作返回RDD,因此他们是转化而不是行动操作。
reduceByKey和reduce相当类似:他们都接收一个函数,并使用该函数对值进行合并。reduceByKey会为数据集中的每个键进行并行的归约操作,每个归约操作会将键相同的值合并起来。因为数据集中可能有大量的键,所以reduceByKey没有被实现为向用户程序返回一个值得行动操作。实际上,它会返回一个由键和值归约的结果组成新的RDD
foldByKey和fold相当类似:他们都使用一个与RDD和合并函数中的数据类型相同的零值作为初始值。与fold一样, foldByKey() 操作所使用的合并函数对零值与另一 个元素进行合并,结果仍为该元素。
Java中实现单词统计
/**
* 单词统计
*
* @throws IOException
*/
public static void wc() throws IOException {
JavaSparkContext sc = SparkUtils.getContext();
JavaRDD<String> inputRDD = sc.parallelize(Arrays.asList("hello word", "hello spark"));
JavaRDD<String> words = inputRDD.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
JavaPairRDD<String, Integer> groupByKey = words.mapToPair(w -> new Tuple2<String, Integer>(w, 1)).reduceByKey((x, y) -> x + y);
System.out.println(groupByKey.collect());
// [(spark,1), (word,1), (hello,2)]
}
**事实上,我们可以对第一个 RDD 使用 countByValue() 函数,以更快地实现 单词计数: input.flatMap(x => x.split(" ")).countByValue() **
/**
* 单词统计
*
* @throws IOException
*/
public static void wc2() throws IOException {
JavaSparkContext sc = SparkUtils.getContext();
JavaRDD<String> inputRDD = sc.parallelize(Arrays.asList("hello word", "hello spark"));
Map<String, Long> words = inputRDD.flatMap(x -> Arrays.asList(x.split(" ")).iterator()).countByValue();
System.out.println(words);
// {spark=1, word=1, hello=2}
}
combineByKey()是最常用的基于键进行聚合的函数。大多数基于键聚合的函数都是用它实现的。它可以让用户返回与输入类型不同的返回值。
未完待续,键值对怎么求平均值?
# 4.3.2数据分组
对于有键的数据,一个常见的用例是将数据根据键进行分组——比如查看一个客户的所有订单。
如果数据已经以预期的方式提供了键,groupByKey()就会使用RDD的键来对数据进行分组。对于一个由类型K的键和类型V的值组成的RDD,所得到的结果RDD类型会是[K,Interable[V]]。
groupBy()可以用于未成对的数据上,也可以根据键相同以外的条件进行分组。它可以接受一个函数,对源RDD中的每个元素使用该函数,将返回结果作为键在进行分组。
# 4.3.3 连接
将有键的数据与另一组有键的数据一起使用是对键值对数据执行最有用的操作之一。连接数据可能是pair RDD最常用的操作之一,连接方式多种多样:右外连接、左外连接、交叉连接、内连接。
普通的 join 操作符表示内连接 。只有在两个 pair RDD 中都存在的键才叫输出。当一个输 入对应的某个键有多个值时,生成的 pair RDD 会包括来自两个输入 RDD 的每一组相对应 的记录。 有时,我们不希望结果中的键必须在两个 RDD 中都存在。例如,在连接客户信息与推荐时,如果一些客户还没有收到推荐,我们仍然不希望丢掉这些顾客。 leftOuterJoin(other)和 rightOuterJoin(other) 都会根据键连接两个 RDD,但是允许结果中存在其中的一个pair RDD 所缺失的键。
在使用 leftOuterJoin() 产生的 pair RDD 中,源 RDD 的每一个键都有对应的记录。每个键相应的值是由一个源 RDD 中的值与一个包含第二个 RDD 的值的 Option (在 Java 中为Optional )对象组成的二元组。在 Python 中,如果一个值不存在,则使用 None 来表示;而数据存在时就用常规的值来表示,不使用任何封装。和 join() 一样,每个键可以得到多条记录;当这种情况发生时,我们会得到两个 RDD 中对应同一个键的两组值的笛尔积。
# 4.3.4 数据排序
如果键有已定义的顺序,就可以对这种键值对RDD进行排序。当把数据排序好之后,后续对数据形成collect()和save()等操作都会得到有序的数据。
我们经常要将 RDD 倒序排列,因此 sortByKey() 函数接收一个叫作 ascending 的参数,表示我们是否想要让结果按升序排序(默认值为 true )。有时我们也可能想按完全不同的排序依据进行排序。要支持这种情况,我们可以提供自定义的比较函数
/**
* 排序
* <p>
* Java中以字符串顺序自定义排序
*/
public static void orderBy() {
JavaSparkContext sc = SparkUtils.getContext();
JavaRDD<String> inputRDD = sc.parallelize(Arrays.asList("hello word", "hello spark"));
JavaRDD<String> words = inputRDD.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
JavaPairRDD<String, Integer> result = words.mapToPair(w -> new Tuple2<String, Integer>(w, 1)).reduceByKey((x, y) -> x + y);
System.out.println(result.collect());
// [(spark,1), (word,1), (hello,2)]
class Compa implements Serializable, Comparator<String> {
private static final long serialVersionUID = 1L;
@Override
public int compare(String a, String b) {
return a.compareTo(b);
}
}
Compa compa = new Compa();
JavaPairRDD<String, Integer> sortByKey = result.sortByKey(compa);
System.err.println(sortByKey.collect());
// [(hello,2), (spark,1), (word,1)]
sc.close();
}
# 4.4 Pair RDD行动操作
所有基础RDD支持的传统操作也都在pair RDD上可用。pair RDD还提供了一些额外的行动操作。
Pair RDD的行动操作(以键值对集合{(1,2),(3,4),(3,6)})为例
| 函数 | 描述 | 实例 | 结果 |
|---|---|---|---|
| countByKey() | 对每个键值对分别计数 | rdd.countByKey() | {(1,1),)(3,2)} |
| collectAsMap() | 将结果以映射的形式返回,以便查询 | rdd.cokkectAsMap | Map{(1,2),(3,4),(3,6)} |
| lookuo(key) | 返回给定键的所有值 | rdd.lookup(3) | [4,6] |
# 5 数据读取和保存
# 5.1 动机
到目前为止,所有的示例都是从本地集合或普通文件中进行数据读取和保存。但是有时候,数据量可能大到无法放在同一台机器中,这就需要探索别的数据读取和保存方法了。
Spark及其生态系统提供了很多可选方案。下面介绍常见的3中数据源
- 文件格式和文件系统
- Spark SQL中结构化数据源
- 数据库与键值存储
1 文件格式和文件系统
对于存储在本地文件系统或者分布式文件系统(比如NFS、hdfs等)中的数据,Spark可以范文很多不同的文件格式,包括文本文件、JSON、SequenceFile以及protocol buff。Spark针对不同的文件系统的配置和压缩选项。
Spark SQL中结构化数据源
Spark SQL,它包括了JSON和Hive在内的结构化数据源,为我们提供了一套更加简洁高效地API。
数据库与键值存储
Spark自带的库和一些第三方库,可以用来连接 Cassandra、HBase、Elasticsearch 以及 JDBC 源。
# 5.2 文件格式
Spark对很多种文件格式的读取和保存方式都很简单。从诸如文本文件的非结构化文件、以及诸如JSON格式的半结构化文件,再到SequenceFile这样的结构化文件,Spark都支持。
Spark支持的一些常见格式
| 格式名称 | 结构化 | 备注 |
|---|---|---|
| 文本文件 | 否 | 普通文本文件,每行一条记录 |
| JSON | 半结构化 | 常见的基于文本的格式,半结构化,多数数库都要求每行一条记录 |
| CSV | 是 | 基于文本的格式,通常在电子表格中使用 |
| SequenceFiles | 是 | 一种用于键值对数据的常见Hadoop文件格式 |
| Protocol buffers | 是 | 一种快速、节约空间的跨语言格式 |
| 对象文件 | 是 | 用来将Spark作业中的数据存储下来以让共享的代码读取,改变类的结构它会失效,因为它依赖Java序列化 |
# 5.2.1 文本文件
在Spark中读写文本文件很容易。当我们将一个文本文件读取为RDD时,输入的每一行都会成为RDD中的一个元素。也可以将多个完整的文本文件一次性读取为一个pair RDD,其中键是文件名,值是文本内容。
# 1 读取文本文件
只需要SparkContext 中textFile函数,如果要控制分区数的话,可以指定 minPartitions。
sc.textFile("c:/info.txt");//支持统配符
如果多个输入文件以一个包含数据所有部分的目录的形式出现,可以用两种方式来处理。可以仍使用textFile函数,传递目录作为参数,这样它会把各部分都读取到RDD中。有时候必要知道数据的各部分分别来自哪个文件,有时候则希望同时处理整个文件。如果文件足够小,那么可以使用SparkContext.wholeTextFiles()方法,该方法会返回一个pair RDD,其中键是输入文件的文件名。
wholeTextFiles()在每个文件表示一个特定时间段内的数据是非常有用。
# 2 保存文本文件
输出文本文件也相当简单。saveAsTextFile()方法接收一个路劲,并将RDD中的内容输入到路劲对应的文件中。Spark将传入的路劲作为目录对待,会在那个目录输出多个文件。这样,Spark就可以从多个节点上并行输出了。在这个方法中,我们不能控制数据的那一部分输出到哪个文件中,不过有些输出格式支持控制。
# 5.2.2 JSON
读取JSON数据的最简单的方式是将数据作为文本文件读取,然后使用JSON解析器来对RDD中的值进行映射操作。
# 1 读取JSON
这种方法假设文件中每一行都是一条JSON记录。如果你有跨行的JSON数据,你就只能读入整个文件,然后对每个文件进行解析。如果在你使用的语言中构建一个JSON解析器的开销较大,你可以使用mapPartitions()来重用解析器。
# 5.2.3 逗号分隔值与制表符分隔值
在Scala和Java中则使用opencsv库 (opens new window)
# 5.3 文件系统
# 5.4 Spark SQL中的结构化数据
在各种情况下,我们把一条SQL查询给Spark SQL,让它对于一个数据源执行查询(选出一些字段或者对字段使用一些函数),然后得到有ROW对象组成的RDD,每个row对象表示一条记录,在Java和Scala中,row对象的访问时基于下标的。每个Row都有一个get方法,返回一个一般类型都我们进行类型转换。
# 5.4.1 Apache Hive
Spark SQL可以读取到Hive支持的任何表。
要把Spark SQL连接到已有的Hive上,你需要提供Hive的配置文件,需要将hive-site.xml文件复制到Saprk的conf目录下,这样之后,在创建出HiveContext对象,也就是Saprk SQL的入口,然后可以用Hive查询语句来对你的表进行查询,并由行组成的RDD的形式拿到返回的数据。
/**
* Java创建hiveContext并查询数据
*/
public static void connHive() {
// 我使用到这个是spark 2.1.1版本,HiveContext已经过时了
HiveContext hiveContext = new HiveContext(SparkUtils.getContext());
Dataset<Row> rows = hiveContext.sql("select name,age from user");
Row first = rows.first();
System.out.println(first.getString(0));// 字段0是name字段
}
# 5.4.2 JSON
如果记录结构一致的JSON数据,Spark SQL也可以自动推断出他们的结构信息,并将这些数据读取为记录,这样就可以使得提取字段操作变得简单。要读取JSON数据,首先要和HIVE一样创建一个HiveContext。(不过这种情况不需要我们安装好hive,也就是说你不需要hive-site.xml文件)。然后使用HiveContext.jsonFile方法从整个文件中获取ow对象组成的RDD,除了整个RDD对象,你也可以将RDD注册为一张表,然后从中选出特定的字段。
JSONS示例

# 5.5 数据库
通过数据库提供的 Hadoop 连接器或者自定义的 Spark 连接器,Spark 可以访问一些常用的数据库系统。本节来展示四种常见的连接器。
# 5.5.1 Java数据库连接器
Spark可以从任何支持Java数据库连接JDBC关系型数据库中读取数据,包括MySQL、postgre等系统。要访问这些数据。需要构建一个org.apache.spark.rdd.JdbcRDD,将SparkContext和其他参数一起传给它。
# 5.5.2 Cassandra
# 5.5.4 HBase
# 6 Spark编程进阶
介绍两种类型的共享变量:累加器和广播变量
累加器
用来对信息进行聚合,而广播变量用来高效分发较大的对象。
在已有的 RDD 转化操作的基础上,我们为类似查询数据库这样需要很大配置代价的任务引入了批操作。为了扩展可用的工具范围,本章会介绍 Spark 与外部程序交互的方式,比如如何与用 R 语言编写的脚本进行交互。
# 6.2 累加器
通过在向Spark传递函数是,比如使用map函数或者filter传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中对应的变量。Spark的两个共享变量,累加器和广播变量,分别为结果聚合与广播这两种常见的同学模式突破了这一限制。
累加器,提供了将工作节点中的值聚合到驱动器程序中的简单语法。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。
/**
* 累加器,计算空白行
*/
public static void callamdba() {
JavaSparkContext sc = SparkUtils.getContext();
JavaRDD<String> file = sc.textFile("c://info.txt");
Accumulator<Integer> blankLines = sc.accumulator(0);// 创建并初始化为0
JavaRDD<String> call = file.flatMap(line -> {
if (line.length() == 0) {
// 累加器加1
blankLines.add(1);
}
System.out.println("======|" + line + "|");
return Arrays.asList(line.split(" ")).iterator();
});
System.out.println(call.count());
System.out.println("空白行有:" + blankLines);
sc.close();
}
/**
* 累加器,计算空白行
*/
public static void cal() {
JavaSparkContext sc = SparkUtils.getContext();
JavaRDD<String> file = sc.textFile("c://info.txt");
Accumulator<Integer> blankLines = sc.accumulator(0);// 创建并初始化为0
JavaRDD<String> call = file.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String t) throws Exception {
if (t.length() == 0) {
blankLines.add(1);
}
return Arrays.asList(t.split(" ")).iterator();
}
});
System.out.println(call.count());
System.out.println("空白行有:" + blankLines);
sc.close();
}
上述代码中只有使用或者保存了结果RDD,才能看到空白行输出,因为flatMap是惰性的。
累加器如法如下:
- 通过在驱动器中调用SparkContext.accumulator()方法,创建出存有初始值的累加器。
- Saprk闭包里的执行器代码可以使用累加器的+=方法增加累加器的值
- 驱动器程序可以调用累加器的value的属性来访问累加器的值。
# 6.2.1 累加器与容错性
Spark会自动重新执行失败的或者较慢的任务来应对有错误的或者比较慢的机器。即使该节点没有崩溃,而只是处理的比其他节点慢很多,Spark也可以抢占式德在另一节点上启动一个投机型的任务副本,如果该任务更早结束就可以直接获取结果。即使没有节点失败,Spark 有时也需要重新运行任务来获取缓存中被移除出内存的数据。因此最终结果就是同一个函数可能对同一个数据运行了多次,这取决于集群发生了什么。
如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach这样的行动操作中。
# 6.2.2 自定义累加器
自定义累加器需要扩展 AccumulatorParam
# 6.3 广播变量
Spark 的第二种共享变量类型是广播变量,它可以让程序高效地向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。
广播变量使用的过程
- 通过一个类型T的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。任何可序列化的类型都可以这么实现。
- 通过value属性访问该对象的值
- 变量只会被发到各个节点一次,应作为只读值处理
# 6.6 数值RDD的操作
Spark 的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建出模型。这些统计数据都会在调用 stats() 时通过一次遍历数据计算出来,并以 StatsCounter 对象返回.
StatsCounter 中可用的汇总统计数据
| 方法 | 含义 |
|---|---|
| count | RDD元素个数 |
| mean | 元素平均值 |
| sum/max/min | 总和/最大、最小 |
| variance | 元素的方差 |
| stdev | 标准差 |
# 参考文章
- https://blog.csdn.net/u012848709/article/details/84134342
- https://blog.csdn.net/u012848709/article/details/84147136










