TIP
本文主要是介绍 数据可视化-基本处理流程 。
# 数据可视化的基本流程
大多数人对数据可视化的第一印象,可能就是各种图形,比如Excel图表模块中的柱状图、条形图、折线图、饼图、散点图等等,就不一一列举了。以上所述,只是数据可视化的具体体现,但是数据可视化却不止于此。
数据可视化不是简单的视觉映射,而是一个以数据流向为主线的一个完整流程,主要包括数据采集、数据处理和变换、可视化映射、用户交互和用户感知。一个完整的可视化过程,可以看成数据流经过一系列处理模块并得到转化的过程,用户通过可视化交互从可视化映射后的结果中获取知识和灵感。
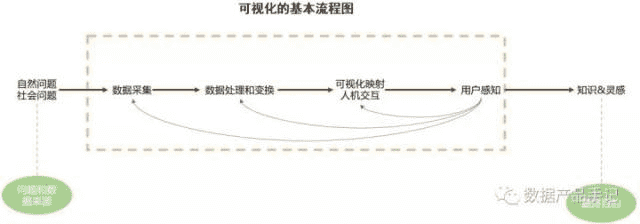
图1 可视化的基本流程图
可视化主流程的各模块之间,并不仅仅是单纯的线性连接,而是任意两个模块之间都存在联系。例如,数据采集、数据处理和变换、可视化编码和人机交互方式的不同,都会产生新的可视化结果,用户通过对新的可视化结果的感知,从而又会有新的知识和灵感的产生。
下面,对数据可视化主流程中的几个关键步骤进行说明。
# 01数据采集
数据采集是数据分析和可视化的第一步,俗话说“巧妇难为无米之炊”,数据采集的方法和质量,很大程度上就决定了数据可视化的最终效果。
数据采集的分类方法有很多,从数据的来源来看,可以分为内部数据采集和外部数据采集。
# 1.内部数据采集:
指的是采集企业内部经营活动的数据,通常数据来源于业务数据库,如订单的交易情况。如果要分析用户的行为数据、APP的使用情况,还需要一部分行为日志数据,这个时候就需要用「埋点」这种方法来进行APP或Web的数据采集。
# 2.外部数据采集:
指的数通过一些方法获取企业外部的一些数据,具体目的包括,获取竞品的数据、获取官方机构官网公布的一些行业数据等。获取外部数据,通常采用的数据采集方法为「网络爬虫」。
以上的两类数据采集方法得来的数据,都是二手数据。通过调查和实验采集数据,属于一手数据,在市场调研和科学研究实验中比较常用,不在此次探讨范围之内。
# 02数据处理和变换
数据处理和数据变换,是进行数据可视化的前提条件,包括数据预处理和数据挖掘两个过程。
一方面,通过前期的数据采集得到的数据,不可避免的含有噪声和误差,数据质量较低;另一方面,数据的特征、模式往往隐藏在海量的数据中,需要进一步的数据挖掘才能提取出来。
常见的数据质量问题包括:
1.数据收集错误,遗漏了数据对象,或者包含了本不应包含的其他数据对象。
2.数据中的离群点,即不同于数据集中其他大部分数据对象特征的数据对象。
3.存在遗漏值,数据对象的一个或多个属性值缺失,导致数据收集不全。
4.数据不一致,收集到的数据明显不合常理,或者多个属性值之间互相矛盾。例如,体重是负数,或者所填的邮政编码和城市之间并没有对应关系。
5.重复值的存在,数据集中包含完全重复或几乎重复的数据。
正是因为有以上问题的存在,直接拿采集的数据进行分析or可视化,得出的结论往往会误导用户做出错误的决策。因此,对采集到的原始数据进行数据清洗和规范化,是数据可视化流程中不可缺少的一环。
数据可视化的显示空间通常是二维的,比如电脑屏幕、大屏显示器等,3D图形绘制技术解决了在二维平面显示三维物体的问题。
但是在大数据时代,我们所采集到的数据通常具有4V特性:Volume(大量)、Variety(多样)、Velocity(高速)、Value(价值)。如何从高维、海量、多样化的数据中,挖掘有价值的信息来支持决策,除了需要对数据进行清洗、去除噪声之外,还需要依据业务目的对数据进行二次处理。
常用的数据处理方法包括:降维、数据聚类和切分、抽样等统计学和机器学习中的方法。
# 03可视化映射
对数据进行清洗、去噪,并按照业务目的进行数据处理之后,接下来就到了可视化映射环节。可视化映射是整个数据可视化流程的核心,是指将处理后的数据信息映射成可视化元素的过程。
可视化元素由3部分组成:可视化空间+标记+视觉通道
# 1.可视化空间
数据可视化的显示空间,通常是二维。三维物体的可视化,通过图形绘制技术,解决了在二维平面显示的问题,如3D环形图、3D地图等。
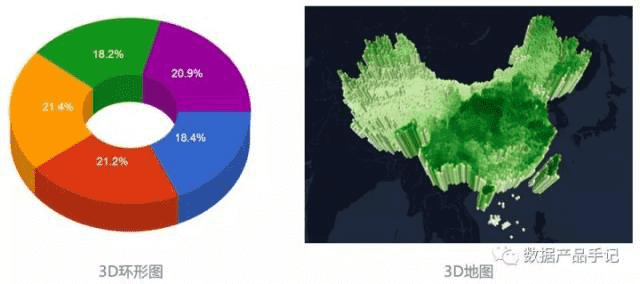
图2 可视化空间示例
# 2.标记
标记,是数据属性到可视化几何图形元素的映射,用来代表数据属性的归类。
根据空间自由度的差别,标记可以分为点、线、面、体,分别具有零自由度、一维、二维、三维自由度。如我们常见的散点图、折线图、矩形树图、三维柱状图,分别采用了点、线、面、体这四种不同类型的标记。
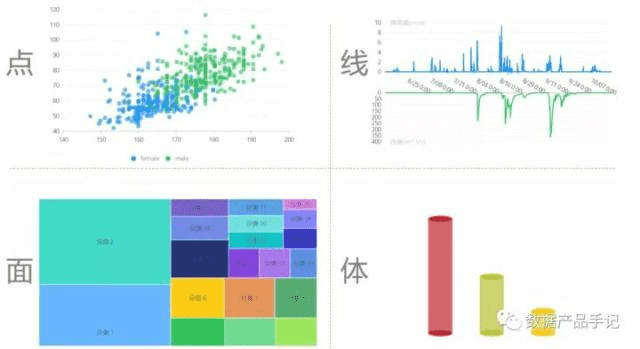
图3 标记类型示例
# 3.视觉通道
数据属性的值到标记的视觉呈现参数的映射,叫做视觉通道,通常用于展示数据属性的定量信息。
常用的视觉通道包括:标记的位置、大小(长度、面积、体积...)、形状(三角形、圆、立方体...)、方向、颜色(色调、饱和度、亮度、透明度...)等。
图3中的四个图形示例,就很好的利用了位置、大小、颜色等视觉通道来进行数据信息的可视化呈现。
「标记」、「视觉通道」是可视化编码元素的两个方面,两者的结合,可以完整的将数据信息进行可视化表达,从而完成可视化映射这一过程。
关于可视化编码元素的优先级,以及如何根据数据的特征选择合适的可视化表达,下次会专题来分享下。
# 04人机交互
可视化的目的,是为了反映数据的数值、特征和模式,以更加直观、易于理解的方式,将数据背后的信息呈现给目标用户,辅助其作出正确的决策。
但是通常,我们面对的数据是复杂的,数据所蕴含的信息是丰富的。
如果在可视化图形中,将所有的信息不经过组织和筛选,全部机械的摆放出来,不仅会让整个页面显得特别臃肿和混乱,缺乏美感;而且模糊了重点,分散用户的注意力,降低用户单位时间获取信息的能力。
# 常见的交互方式包括:
1.滚动和缩放:当数据在当前分辨率的设备上无法完整展示时,滚动和缩放是一种非常有效的交互方式,比如地图、折线图的信息细节等。但是,滚动与缩放的具体效果,除了与页面布局有关系外,还与具体的显示设备有关。
2.颜色映射的控制:一些可视化的开源工具,会提供调色板,如D3。用户可以根据自己的喜好,去进行可视化图形颜色的配置。这个在自助分析等平台型工具中,会相对多一点,但是对一些自研的可视化产品中,一般有专业的设计师来负责这项工作,从而使可视化的视觉传达具有美感。
3.数据映射方式的控制:这个是指用户对数据可视化映射元素的选择,一般一个数据集,是具有多组特征的,提供灵活的数据映射方式给用户,可以方便用户按照自己感兴趣的维度去探索数据背后的信息。这个在常用的可视化分析工具中都有提供,如tableau、PowerBI等。
4.数据细节层次控制:比如隐藏数据细节,hover或点击才出现。
# 05用户感知
可视化的结果,只有被用户感知之后,才可以转化为知识和灵感。
用户在感知过程,除了被动接受可视化的图形之外,还通过与可视化各模块之间的交互,主动获取信息。
如何让用户更好的感知可视化的结果,将结果转化为有价值的信息用来指导决策,这个里面涉及到的影响因素太多了,心理学、统计学、人机交互等多个学科的知识。
# 参考文章
- https://baijiahao.baidu.com/s?id=1643907732485376899&wfr=spider&for=pc










