TIP
本文主要是介绍 Spark-数据处理场景介绍 。
# 学习笔记 | 解析 Spark 数据处理与分析场景
# 数据处理场景
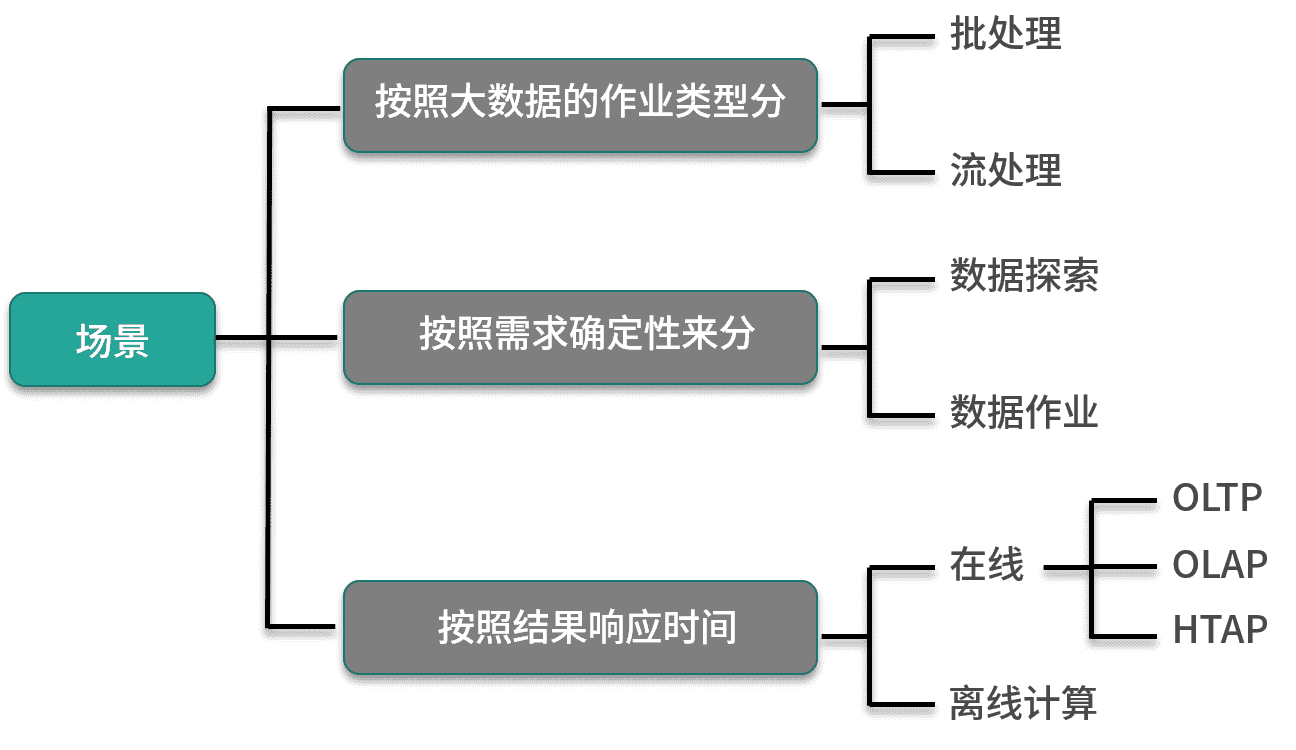
# 按照大数据的作业类型
在数据工程与数据科学中,很大一部分数据处理任务都可以被称为批处理(Batch Processing),所谓批处理,就是对数据进行批量处理,一次性对一定量的数据进行处理,根据数据量的大小,批处理从开始到结束的时间从数十秒到数小时都有可能,当然如果时间花费太长,还是会考虑优化、切分等,因为这样作业执行失败的成本太高了。
- 批处理任务的输入和输出通常都是一批数据,在数据工程中常见的ETL场景中,经常会从数据库中抽取一部分数据进行去重后写入到存储系统,另外机器学习中训练模型都是典型的批处理。对于批处理来说,最大的缺点是数据处理任务延迟较长,无法与在线系统进行实时对接,但对于每条数据来说,消耗的计算成本是最低的。
而与批处理相对应的是流处理(Streaming Processing),与静止在某个系统中的批量数据不同,流处理在处理数据时数据是动态的,源源不断的,而且数据蕴含的价值会随着时间的流逝降低,所以需要对数据流进行实时处理。
- 流处理在数据工程领域运用比较广泛,一般都与在线系统对接,比如实时数据分析、业务系统的消息流转等。但在数据科学中,几乎没有流处理的场景,除了个别如在线训练这种比较特殊的应用。由于流处理可以认为是数据一到来就进行处理,所以对于每条数据来说,虽然延迟很低,但消耗计算成本是最高的。
这里举一个批处理与流处理结合的场景,比如模型分析师用机器学习算法对一批数据进行训练,得到一个模型,测试完毕后,数据工程师会将这个模型部署到线上环境对数据流进行实时预测。这也是数据科学与数据工程相结合的一个场景。
# 按照需求确定性
对于数据工程师与数据科学家来说,想要了解新的数据集最好的方式就是按照自己的习惯对数据进行一些查询处理,虽然这些查询处理的目的与方式都不同,比如数据科学家可能关注的是某一列的分布,从而发现一些有趣的东西,而数据工程师则关心的是某一列的异常值,进而修改自己的处理逻辑。但是这类查询处理都有一个共同点就是不确定,有可能根据数据集的不同而不同,也有可能根据用户的不同而不同,甚至下一个查询是基于上一个查询的结果,这类查询我们称之为数据探索。
- 数据探索的第一个特点是不确定,而第二个特点是时间不能太长,如果太长的话,就会严重影响数据探索的效率也达不到探索的效果了。
与需求不确定的数据探索相对应的就是需求确定的数据处理任务,这类任务一般都会定时、定期运行,是公司、组织以及流程中的一部分,比如数据预处理、按照分析需求生成报表等等,通常再开发这类数据处理任务之前,会进行数据探索。
# 按照结果响应时间
在这个维度下,按照结果响应时间分类,可以分为两类:
- 可以在线响应;
- 不能在线响应。
第 1 类通常指的是基于数据库操作或者是基于支持某种查询语言的工具(例如SQL)进行操作,并且实时返回结果,主要有两类:OLTP和OLAP。
- OLTP(Online Transaction Processing)通常指的是业务系统中常见的事务处理,对应数据库的增删改查操作。
- OLAP(Online Analytic Processing)主要指的是在线分析处理,对应数据库的查询操作,但不仅限于数据库,主要帮助分析人员可以迅速地、一致地、可交互地查询数据,也被称作交互式查询。
OLAP 与 OLTP 代表对数据处理两种截然不同的方式,但它们有个共同点,就是在线,这里在线意味着查询返回的结果不能太长,并且一般要能够支持在线应用,所以可以统称为在线处理。通常来说事务处理与分析处理分别代表了写优化与读优化两种方向,很难完全共存。
目前业界提出了一个新的场景和解决方案 HTAP(Hybrid Transaction and Analytical Process,混合事务与分析处理)系统,例如 TiDB 和阿里云的 AnalyticDB,既可以进行事务处理也可以进行分析处理,这里不展开介绍。
对于不能在线响应的场景,也就是第2类,这里笼统的称为离线计算或者离线处理,这里注意离线处理与在线处理界限并不是绝对的,对于同一个场景,如果全方位的进行优化,例如提升大幅度提升计算能力或者对数据进行预处理等,那么可以让原有的离线处理场景变为在线处理场景。
前面说到,这种分类方法存在一些概念的交叉与重合,很容易想到的,例如在数据探索中,会非常频繁地进行 OLAP,那么这类操作,我们一般称为即席(ad-hoc 查询)查询。在数据探索中,通常也可以忍受进行 1 分钟(或者更多)时间的批处理;数据处理任务中有可能有批处理,也有可能有流处理。
在上面的图中,除了 Spark 一般不会用于在线处理部分(OLTP、OLAP与HTAP)之外,在其他所有场景下,都能够很好的满足企业与用户的需求,但值得一提的是 Spark 与 OLAP 并不是完全没有关系,这里举一个例子:
在历史订单数据库中,保存了极其巨量的数据(从过去到现在的所有订单),而用户只关心历史某个品类的月度销量数据,但是由于原始数据过于巨大,所以导致普通的查询及其缓慢,在这里,可以用 Spark 将数据从数据库抽取出来并按照时间与品类维度进行转换和汇总(批处理),处理后的数据的大小与原始数据相比可能是上万倍的差距,用户就能很容易地进行在线分析了。
# 参考文章
- https://blog.csdn.net/qq_34170700/article/details/106878792










