TIP
本文主要是介绍 Flink-电商实时热门商品统计 。
# 转载:基于flink的电商用户行为数据分析【2】| 实时热门商品统计
本文已收录github:https://github.com/BigDataScholar/TheKingOfBigData,里面有大数据高频考点,Java一线大厂面试题资源,上百本免费电子书籍,作者亲绘大数据生态圈思维导图…持续更新,欢迎star!
# 前言
# 在上一期内容中,菌哥已经为大家介绍了电商用户行为数据分析的主要功能和模块介绍。本期内容,我们需要介绍的是实时热门商品统计模块的功能开发。
首先要实现的是实时热门商品统计,我们将会基于UserBehavior数据集来进行分析。
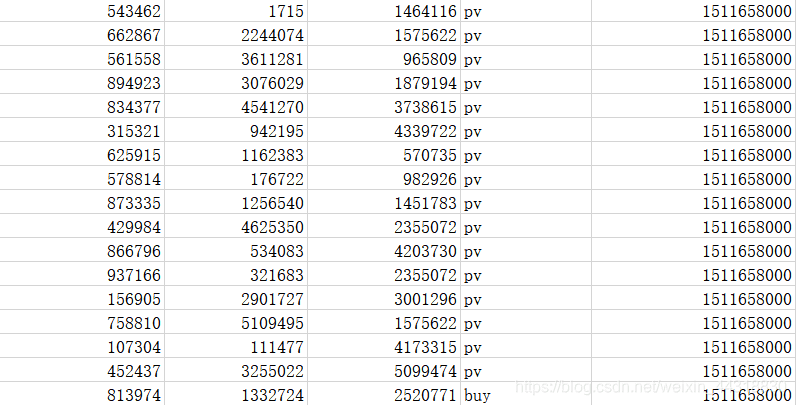
项目主体用Scala编写,采用IDEA作为开发环境进行项目编写,采用maven作为项目构建和管理工具。首先我们需要搭建项目框架。
# 创建Maven项目
# 项目框架搭建
打开IDEA,创建一个maven项目,命名为UserBehaviorAnalysis。由于包含了多个模块,我们可以以UserBehaviorAnalysis作为父项目,并在其下建一个名为HotItemsAnalysis的子项目,用于实时统计热门top N商品。
在UserBehaviorAnalysis下新建一个 maven module作为子项目,命名为HotItemsAnalysis。
父项目只是为了规范化项目结构,方便依赖管理,本身是不需要代码实现的,所以UserBehaviorAnalysis下的src文件夹可以删掉。
# 声明项目中工具的版本信息
我们整个项目需要的工具的不同版本可能会对程序运行造成影响,所以应该在最外层的UserBehaviorAnalysis中声明所有子模块共用的版本信息。
在pom.xml中加入以下配置:
<properties>
<flink.version>1.7.2</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<kafka.version>2.2.0</kafka.version>
</properties>
# 添加项目依赖
对于整个项目而言,所有模块都会用到flink相关的组件,所以我们在UserBehaviorAnalysis中引入公有依赖:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_${scala.binary.version}</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
同样,对于maven项目的构建,可以引入公有的插件:
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>
jar-with-dependencies
</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
在HotItemsAnalysis子模块中,我们并没有引入更多的依赖,所以不需要改动pom文件。
# 数据准备
在src/main/目录下,可以看到已有的默认源文件目录是java,我们可以将其改名为scala。将数据文件UserBehavior.csv复制到资源文件目录src/main/resources下,我们将从这里读取数据。
至此,我们的准备工作都已完成,接下来可以写代码了。
# 模块代码实现
我们将实现一个“实时热门商品”的需求,可以将“实时热门商品”翻译成程序员更好理解的需求:每隔5分钟输出最近一小时内点击量最多的前N个商品。将这个需求进行分解我们大概要做这么几件事情:
- 抽取出业务时间戳,告诉Flink框架基于业务时间做窗口
- 过滤出点击行为数据
- 按一小时的窗口大小,每5分钟统计一次,做滑动窗口聚合(Sliding Window)
- 按每个窗口聚合,输出每个窗口中点击量前N名的商品
# 程序主体
在src/main/scala下创建HotItems.scala文件,新建一个单例对象。定义样例类UserBehavior和ItemViewCount,在main函数中创建StreamExecutionEnvironment 并做配置,然后从UserBehavior.csv文件中读取数据,并包装成UserBehavior类型。代码如下:
/*
1. @Author: Alice菌
2. @Date: 2020/11/23 10:38
3. @Description:
电商用户行为数据分析:热门商品实时统计
*/
object HotItems {
// 定义样例类,用于封装数据
case class UserBehavior(userId:Long,itemId:Long,categoryId:Int,behavior:String,timeStamp:Long)
// 中间输出的商品浏览量的样例类
case class ItemViewCount(itemId:Long,windowEnd:Long,count:Long)
def main(args: Array[String]): Unit = {
// 定义流处理环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 为了打印到控制台的结果不乱序,我们配置全局的并发为1,这里改变并发对结果正确性没有影响
env.setParallelism(1)
// 设置时间特征为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 读取文本文件,以 Window 为例
val stream: DataStream[String] = env.readTextFile("YOUR_PATH\\resources\\UserBehavior.csv")
// 对读取到的数据源进行处理
stream.map(data =>{
val dataArray: Array[String] = data.split(",")
// 将数据封装到新建的样例类中
UserBehavior(dataArray(0).trim.toLong,dataArray(1).trim.toLong,dataArray(2).trim.toInt,dataArray(3).trim,dataArray(4).trim.toLong)
})
// 设置waterMark(水印) -- 处理乱序数据
.assignAscendingTimestamps(_.timeStamp * 1000)
// 执行程序
env.execute("HotItems")
这里注意,我们需要统计业务时间上的每小时的点击量,所以要基于EventTime来处理。那么如何让Flink按照我们想要的业务时间来处理呢?这里主要有两件事情要做。
第一件是告诉Flink我们现在按照EventTime模式进行处理,Flink默认使用ProcessingTime处理,所以我们要显式设置如下:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
第二件事情是指定如何获得业务时间,以及生成Watermark。Watermark是用来追踪业务事件的概念,可以理解成EventTime世界中的时钟,用来指示当前处理到什么时刻的数据了。由于我们的数据源的数据已经经过整理,没有乱序,即事件的时间戳是单调递增的,所以可以将每条数据的业务时间就当做Watermark。这里我们用 assignAscendingTimestamps来实现时间戳的抽取和Watermark的生成。
注:真实业务场景一般都是乱序的,所以一般不用assignAscendingTimestamps,而是使用BoundedOutOfOrdernessTimestampExtractor。
.assignAscendingTimestamps(_.timestamp * 1000)
这样我们就得到了一个带有时间标记的数据流了,后面就能做一些窗口的操作。
# 过滤出点击事件
在开始窗口操作之前,先回顾下需求“每隔5分钟输出过去一小时内点击量最多的前N个商品”。由于原始数据中存在点击、购买、收藏、喜欢各种行为的数据,但是我们只需要统计点击量,所以先使用filter将点击行为数据过滤出来。
.filter(_.behavior == "pv")
# 设置滑动窗口,统计点击量
由于要每隔5分钟统计一次最近一小时每个商品的点击量,所以窗口大小是一小时,每隔5分钟滑动一次。即分别要统计[09:00, 10:00), [09:05, 10:05), [09:10, 10:10)…等窗口的商品点击量。是一个常见的滑动窗口需求(Sliding Window)。
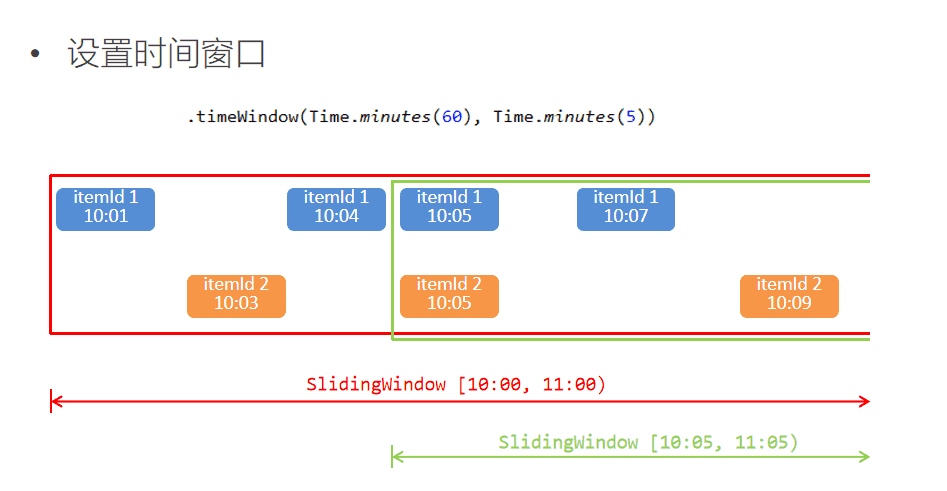
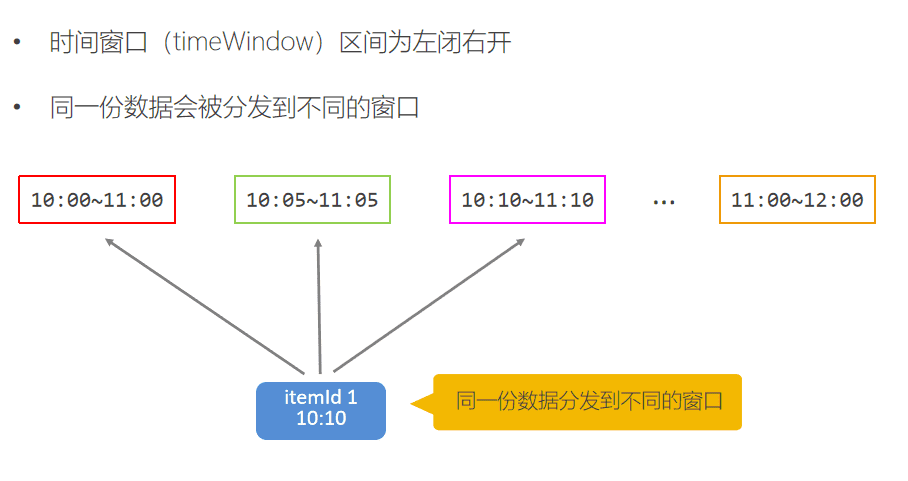
.keyBy("itemId")
.timeWindow(Time.minutes(60), Time.minutes(5))
.aggregate(new CountAgg(), new WindowResultFunction());
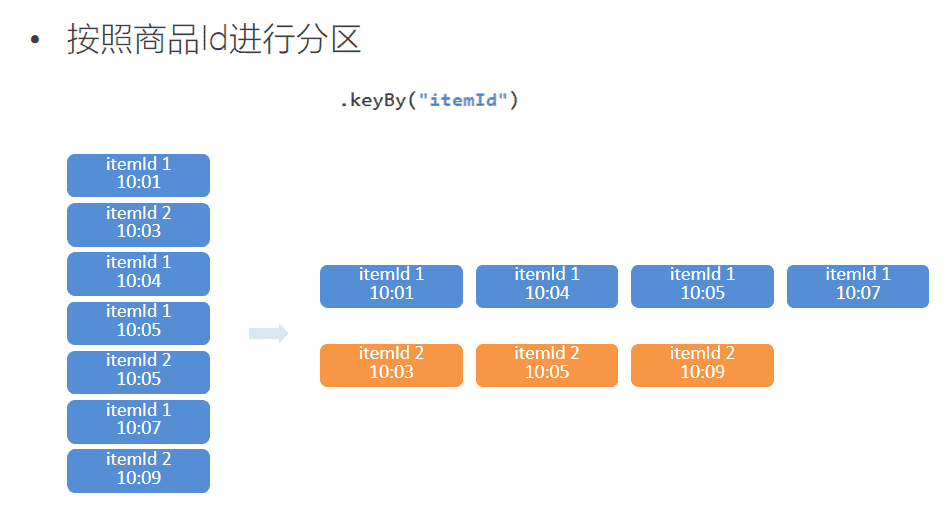
我们使用.keyBy("itemId")对商品进行分组,使用.timeWindow(Time size, Time slide)对每个商品做滑动窗口(1小时窗口,5分钟滑动一次)。然后我们使用 .aggregate(AggregateFunction af, WindowFunction wf)做增量的聚合操作,它能使用AggregateFunction提前聚合掉数据,减少state的存储压力。较之 .apply(WindowFunction wf)会将窗口中的数据都存储下来,最后一起计算要高效地多。这里的CountAgg实现了AggregateFunction接口,功能是统计窗口中的条数,即遇到一条数据就加一。

// COUNT统计的聚合函数实现,每出现一条记录就加一
class CountAgg extends AggregateFunction[UserBehavior, Long, Long] {
override def createAccumulator(): Long = 0L
override def add(userBehavior: UserBehavior, acc: Long): Long = acc + 1
override def getResult(acc: Long): Long = acc
override def merge(acc1: Long, acc2: Long): Long = acc1 + acc2
}
聚合操作.aggregate(AggregateFunction af, WindowFunction wf)的第二个参数WindowFunction将每个key每个窗口聚合后的结果带上其他信息进行输出。我们这里实现的WindowResultFunction将<主键商品ID,窗口,点击量>封装成了ItemViewCount进行输出。
// 商品点击量(窗口操作的输出类型)
case class ItemViewCount(itemId: Long, windowEnd: Long, count: Long)
代码如下:
// 自定义窗口函数,包装成 ItemViewCount输出
class WindowResult() extends WindowFunction[Long,ItemViewCount,Long,TimeWindow] {
override def apply(key: Long, window: TimeWindow, input: Iterable[Long], out: Collector[ItemViewCount]): Unit = {
// 在前面的步骤中,我们根据商品 id 进行了分组,次数的key就是 商品编号
val itemId: Long = key
// 获取 窗口 末尾
val windowEnd: Long = window.getEnd
// 获取点击数大小 【累加器统计的结果 】
val count: Long = input.iterator.next()
// 将获取到的结果进行上传
out.collect(ItemViewCount(itemId,windowEnd,count))
}
}
现在我们就得到了每个商品在每个窗口的点击量的数据流。
为了帮助大家理解,以上几步体现出来的核心思想,小菌这里贴出一张图帮助大家回顾
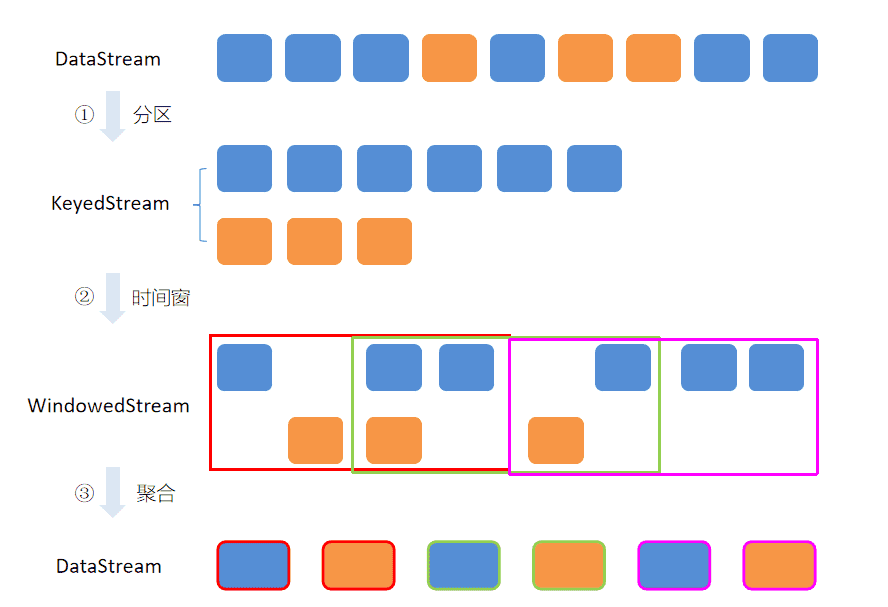
# 计算最热门 TopN 商品
为了统计每个窗口下最热门的商品,我们需要再次按窗口进行分组,这里根据ItemViewCount中的windowEnd进行keyBy()操作。然后使用ProcessFunction实现一个自定义的TopN函数TopNHotItems来计算点击量排名前3名的商品,并将排名结果格式化成字符串,便于后续输出。
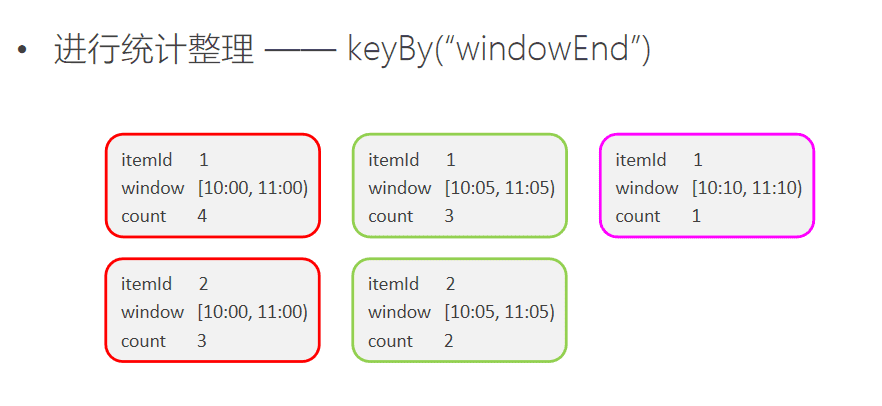
// 按每个窗口聚合
.keyBy(_.windowEnd)
// 输出每个窗口中点击量前N名的商品
.process(new TopNHotItems(3))
ProcessFunction是Flink提供的一个low-level API,用于实现更高级的功能。它主要提供了定时器timer的功能(支持EventTime或ProcessingTime)。本案例中我们将利用timer来判断何时收齐了某个window下所有商品的点击量数据。由于Watermark的进度是全局的,在processElement方法中,每当收到一条数据ItemViewCount,我们就注册一个windowEnd+1的定时器(Flink框架会自动忽略同一时间的重复注册)。windowEnd+1的定时器被触发时,意味着收到了windowEnd+1的Watermark,即收齐了该windowEnd下的所有商品窗口统计值。我们在onTimer()中处理将收集的所有商品及点击量进行排序,选出TopN,并将排名信息格式化成字符串后进行输出。
这里我们还使用了ListState<ItemViewCount>来存储收到的每条ItemViewCount消息,保证在发生故障时,状态数据的不丢失和一致性。ListState是Flink提供的类似Java List接口的State API,它集成了框架的checkpoint机制,自动做到了exactly-once的语义保证。
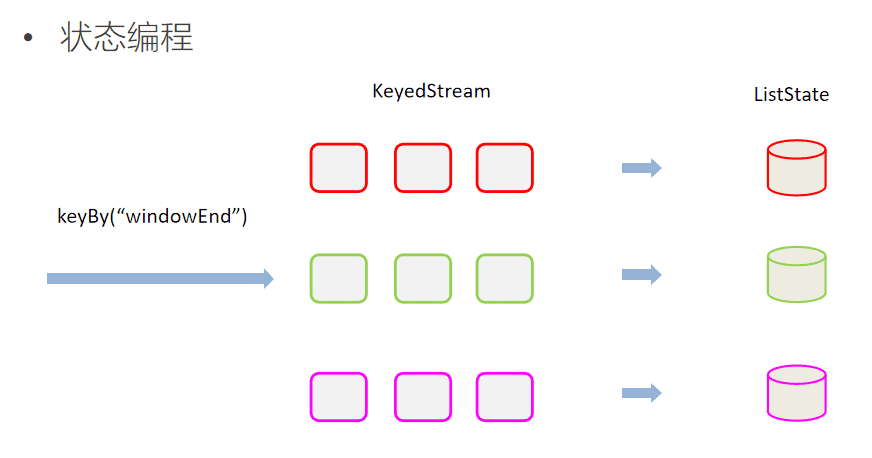
代码如下:
// 自定义 process function,排序处理数据
class TopNHotItems(nSize:Int) extends KeyedProcessFunction[Long,ItemViewCount,String] {
// 定义一个状态变量 list state,用来保存所有的 ItemViewCont
private var itemState: ListState[ItemViewCount] = _
// 在执行processElement方法之前,会最先执行并且只执行一次 open 方法
override def open(parameters: Configuration): Unit = {
// 初始化状态变量
itemState = getRuntimeContext.getListState(new ListStateDescriptor[ItemViewCount]("itemState", classOf[ItemViewCount]))
}
// 每个元素都会执行这个方法
override def processElement(value: ItemViewCount, ctx: KeyedProcessFunction[Long, ItemViewCount, String]#Context, collector: Collector[String]): Unit = {
// 每一条数据都存入 state 中
itemState.add(value)
// 注册 windowEnd+1 的 EventTime Timer, 延迟触发,当触发时,说明收齐了属于windowEnd窗口的所有商品数据,统一排序处理
ctx.timerService().registerEventTimeTimer(value.windowEnd + 100)
}
// 定时器触发时,会执行 onTimer 任务
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, ItemViewCount, String]#OnTimerContext, out: Collector[String]): Unit = {
// 已经收集到所有的数据,首先把所有的数据放到一个 List 中
val allItems: ListBuffer[ItemViewCount] = new ListBuffer()
import scala.collection.JavaConversions._
for (item <- itemState.get()) {
allItems += item
}
// 将状态清除
itemState.clear()
// 按照 count 大小 倒序排序
val sortedItems: ListBuffer[ItemViewCount] = allItems.sortBy(_.count)(Ordering.Long.reverse).take(nSize)
// 将数据排名信息格式化成 String,方便打印输出
val result: StringBuilder = new StringBuilder()
result.append("======================================================\n")
// 触发定时器时,我们多设置了0.1秒的延迟,这里我们将时间减去0.1获取到最精确的时间
result.append("时间:").append(new Timestamp(timestamp - 100)).append("\n")
// 每一个商品信息输出 (indices方法获取索引)
for( i <- sortedItems.indices){
val currentTtem: ItemViewCount = sortedItems(i)
result.append("No").append(i + 1).append(":")
.append("商品ID=").append(currentTtem.itemId).append(" ")
.append("浏览量=").append(currentTtem.count).append(" ")
.append("\n")
}
result.append("======================================================\n")
// 设置休眠时间
Thread.sleep(1000)
// 收集数据
out.collect(result.toString())
}
}
这部分的内容也可以通过流程图来表示:

最后我们可以在main函数中将结果打印输出到控制台,方便实时观测:
.print();
至此整个程序代码全部完成,我们直接运行main函数,就可以在控制台看到不断输出的各个时间点统计出的热门商品。
 基于flink的电商用户行为数据分析【2】_ 实时热门商品统计_Alice菌的博客-CSDN博客_files/20201124195051615.png')" alt="wxmp">
# 完整代码
最终的完整代码如下:
import java.sql.Timestamp
import com.hypers.HotItems.{ItemViewCount, UserBehavior}
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.collection.mutable.ListBuffer
/*
* @Author: Alice菌
* @Date: 2020/11/23 10:38
* @Description:
电商用户行为数据分析:热门商品实时统计
*/
object HotItems {
// 定义样例类,用于封装数据
case class UserBehavior(userId:Long,itemId:Long,categoryId:Int,behavior:String,timeStamp:Long)
// 中间输出的商品浏览量的样例类
case class ItemViewCount(itemId:Long,windowEnd:Long,count:Long)
def main(args: Array[String]): Unit = {
// 定义流处理环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置并行度
env.setParallelism(1)
// 设置时间特征为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 读取文本文件
val stream: DataStream[String] = env.readTextFile("G:\\idea arc\\BIGDATA\\project\\src\\main\\resources\\UserBehavior.csv")
// 对读取到的数据源进行处理
stream.map(data =>{
val dataArray: Array[String] = data.split(",")
// 将数据封装到新建的样例类中
UserBehavior(dataArray(0).trim.toLong,dataArray(1).trim.toLong,dataArray(2).trim.toInt,dataArray(3).trim,dataArray(4).trim.toLong)
})
// 设置waterMark(水印) -- 处理乱序数据
.assignAscendingTimestamps(_.timeStamp * 1000)
// 过滤出 “pv”的数据 -- 过滤出点击行为数据
.filter(_.behavior == "pv")
// 因为需要统计出每种商品的个数,这里先对商品id进行分组
.keyBy(_.itemId)
// 需求: 统计近1小时内的热门商品,每5分钟更新一次 -- 滑动窗口聚合
.timeWindow(Time.hours(1),Time.minutes(5))
// 预计算,统计出每种商品的个数
.aggregate(new CountAgg(),new WindowResult())
// 按每个窗口聚合
.keyBy(_.windowEnd)
// 输出每个窗口中点击量前N名的商品
.process(new TopNHotItems(3))
.print("HotItems")
// 执行程序
env.execute("HotItems")
}
}
// 自定义预聚合函数,来一个数据就加一
class CountAgg() extends AggregateFunction[UserBehavior,Long,Long]{
// 定义累加器的初始值
override def createAccumulator(): Long = 0L
// 定义累加规则
override def add(value: UserBehavior, accumulator: Long): Long = accumulator + 1
// 定义得到的结果
override def getResult(accumulator: Long): Long = accumulator
// 合并的规则
override def merge(a: Long, b: Long): Long = a + b
}
/**
* WindowFunction [输入参数类型,输出参数类型,Key值类型,窗口类型]
* 来处理窗口中的每一个元素(可能是分组的)
*/
// 自定义窗口函数,包装成 ItemViewCount输出
class WindowResult() extends WindowFunction[Long,ItemViewCount,Long,TimeWindow] {
override def apply(key: Long, window: TimeWindow, input: Iterable[Long], out: Collector[ItemViewCount]): Unit = {
// 在前面的步骤中,我们根据商品 id 进行了分组,次数的key就是 商品编号
val itemId: Long = key
// 获取 窗口 末尾
val windowEnd: Long = window.getEnd
// 获取点击数大小 【累加器统计的结果】
val count: Long = input.iterator.next()
// 将获取到的结果进行上传
out.collect(ItemViewCount(itemId,windowEnd,count))
}
}
// 自定义 process function,排序处理数据
class TopNHotItems(nSize:Int) extends KeyedProcessFunction[Long,ItemViewCount,String] {
// 定义一个状态变量 list state,用来保存所有的 ItemViewCont
private var itemState: ListState[ItemViewCount] = _
// 在执行processElement方法之前,会最先执行并且只执行一次 open 方法
override def open(parameters: Configuration): Unit = {
// 初始化状态变量
itemState = getRuntimeContext.getListState(new ListStateDescriptor[ItemViewCount]("itemState", classOf[ItemViewCount]))
}
// 每个元素都会执行这个方法
override def processElement(value: ItemViewCount, ctx: KeyedProcessFunction[Long, ItemViewCount, String]#Context, collector: Collector[String]): Unit = {
// 每一条数据都存入 state 中
itemState.add(value)
// 注册 windowEnd+1 的 EventTime Timer, 延迟触发,当触发时,说明收齐了属于windowEnd窗口的所有商品数据,统一排序处理
ctx.timerService().registerEventTimeTimer(value.windowEnd + 100)
}
// 定时器触发时,会执行 onTimer 任务
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, ItemViewCount, String]#OnTimerContext, out: Collector[String]): Unit = {
// 已经收集到所有的数据,首先把所有的数据放到一个 List 中
val allItems: ListBuffer[ItemViewCount] = new ListBuffer()
import scala.collection.JavaConversions._
for (item <- itemState.get()) {
allItems += item
}
// 将状态清除
itemState.clear()
// 按照 count 大小 倒序排序
val sortedItems: ListBuffer[ItemViewCount] = allItems.sortBy(_.count)(Ordering.Long.reverse).take(nSize)
// 将数据排名信息格式化成 String,方便打印输出
val result: StringBuilder = new StringBuilder()
result.append("======================================================\n")
// 触发定时器时,我们多设置了0.1秒的延迟,这里我们将时间减去0.1获取到最精确的时间
result.append("时间:").append(new Timestamp(timestamp - 100)).append("\n")
// 每一个商品信息输出 (indices方法获取索引)
for( i <- sortedItems.indices){
val currentTtem: ItemViewCount = sortedItems(i)
result.append("No").append(i + 1).append(":")
.append("商品ID=").append(currentTtem.itemId).append(" ")
.append("浏览量=").append(currentTtem.count).append(" ")
.append("\n")
}
result.append("======================================================\n")
// 设置休眠时间
Thread.sleep(1000)
// 收集数据
out.collect(result.toString())
}
}
为了让小伙伴们更好理解,菌哥基本每行代码都写上了注释,就冲这波细节,还不给安排一波三连😎开个玩笑,回到主题上,我们再来讨论一个问题。
实际生产环境中,我们的数据流往往是从Kafka获取到的。如果要让代码更贴近生产实际,我们只需将source更换为Kafka即可:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
当然,根据实际的需要,我们还可以将Sink指定为Kafka、ES、Redis或其它存储,这里就不一一展开实现了。
# 参考
B站视频:https://www.bilibili.com/video/BV1y54y127h2 (opens new window)
# 参考文章
- https://alice.blog.csdn.net/article/details/110024317










