TIP
本文主要是介绍 Flink-电商实时访问流量统计 。
# 转载:基于flink的电商用户行为数据分析【3】| 实时流量统计
本文已收录github:https://github.com/BigDataScholar/TheKingOfBigData,里面有大数据高频考点,Java一线大厂面试题资源,上百本免费电子书籍,作者亲绘大数据生态圈思维导图…持续更新,欢迎star!
# 前言
在上一期内容中,菌哥已经为大家介绍了实时热门商品统计模块的功能开发的过程(👉基于flink的电商用户行为数据分析【2】| 实时热门商品统计 (opens new window))。本期文章,我们要学习的是实时流量统计模块的开发过程。
# 模块创建和数据准备
在UserBehaviorAnalysis下新建一个 maven module作为子项目,命名为NetworkFlowAnalysis。在这个子模块中,我们同样并没有引入更多的依赖,所以也不需要改动pom文件。
在src/main/目录下,将默认源文件目录java改名为scala。将apache服务器的日志文件apache.log复制到资源文件目录src/main/resources下,我们将从这里读取数据。
# 代码实现
我们现在要实现的模块是 “实时流量统计”。对于一个电商平台而言,用户登录的入口流量、不同页面的访问流量都是值得分析的重要数据,而这些数据,可以简单地从web服务器的日志中提取出来。我们在这里实现最基本的“页面浏览数”的统计,也就是读取服务器日志中的每一行log,统计在一段时间内用户访问url的次数。
具体做法为:每隔5秒,输出最近10分钟内访问量最多的前N个URL。可以看出,这个需求与之前“实时热门商品统计”非常类似,所以我们完全可以借鉴此前的代码。
具体分析如下:
热门页面
- 基本需求 – 从 web 服务器的日志中,统计实时的热门访问页面 – 统计每分钟的ip访问量,取出访问量最大的5个地址,每5秒更新一次
- 解决思路 – 将 apache 服务器日志中的时间,转换为时间戳,作为 Event Time – 构建滑动窗口,窗口长度为1分钟,滑动距离为5秒
PV 和 UV
- 基本需求 – 从埋点日志中,统计实时的 PV 和 UV – 统计每小时的访问量(PV),并且对用户进行去重(UV)
- 解决思路 – 统计埋点日志中的 pv 行为,利用 Set 数据结构进行去重 – 对于超大规模的数据,可以考虑用布隆过滤器进行去重
在src/main/scala下创建NetworkFlow.scala文件,新建一个单例对象。定义样例类ApacheLogEvent,这是输入的日志数据流;另外还有UrlViewCount,这是窗口操作统计的输出数据类型。在main函数中创建StreamExecutionEnvironment 并做配置,然后从apache.log文件中读取数据,并包装成ApacheLogEvent类型。
// 输入 log 数据样例类
case class ApacheLogEvent(ip: String, userId: String, eventTime: Long, method: String, url: String)
// 中间统计结果样例类
case class UrlViewCount(url: String, windowEnd: Long, count: Long)
12345
需要注意的是,原始日志中的时间是“dd/MM/yyyy:HH:mm:ss”的形式,需要定义一个DateTimeFormat将其转换为我们需要的时间戳格式:
.map(line => {
val linearray = line.split(" ")
val sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss")
val timestamp = sdf.parse(linearray(3)).getTime
ApacheLogEvent(linearray(0), linearray(2), timestamp,
linearray(5), linearray(6))
})
因为后面部分的逻辑可以说与实时商品统计部分的逻辑是一样的,所以这里小菌就不再带着大家一步步去分析了,完整代码如下:
import java.sql.Timestamp
import java.text.SimpleDateFormat
import java.util
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.collection.mutable.ListBuffer
/*
* @Author: Alice菌
* @Date: 2020/11/23 14:16
* @Description:
电商用户行为数据分析:实时流量统计
<每隔5秒,输出最近10分钟内访问量最多的前N个URL>
*/
object NetworkFlow {
// 输入 log 数据样例类
case class ApacheLogEvent(ip: String, userId: String, eventTime: Long, method: String, url: String)
// 中间统计结果样例类
case class UrlViewCount(url: String, windowEnd: Long, count: Long)
def main(args: Array[String]): Unit = {
// 创建 流处理的 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置时间语义为 eventTime -- 事件创建的时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置任务并行度
env.setParallelism(1)
// 读取文件数据
val stream: DataStream[String] = env.readTextFile("G:\\idea arc\\BIGDATA\\project\\src\\main\\resources\\apache.log")
// 对 stream 数据进行处理
stream.map(data => {
val dataArray: Array[String] = data.split(" ")
// 因为日志文件中的数据格式是 17/05/2015:10:05:03
// 所以我们这里用DataFormat对时间进行转换
val simpleDateFormat: SimpleDateFormat = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss")
val timestamp: Long = simpleDateFormat.parse(dataArray(3).trim).getTime
// 将解析的数据存放至我们定义好的样例类中
ApacheLogEvent(dataArray(0).trim, dataArray(1).trim, timestamp, dataArray(5).trim, dataArray(6).trim)
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[ApacheLogEvent](Time.seconds(60)) {
override def extractTimestamp(element: ApacheLogEvent): Long = element.eventTime
})
// 因为我们需要统计出每种url的出现的次数,故这里将 url 作为 key 进行分组
.keyBy(_.url)
// 滑动窗口聚合 -- 每隔5秒,输出最近10分钟内访问量最多的前N个URL
.timeWindow(Time.minutes(10), Time.seconds(5))
// 预计算,统计出每个 URL 的访问量
.aggregate(new CountAgg(),new WindowResult())
// 根据窗口结束时间进行分组
.keyBy(_.windowEnd)
// 输出每个窗口中访问量最多的前5个URL
.process(new TopNHotUrls(5)) //
.print()
// 执行程序
env.execute("network flow job")
}
// 自定义的预聚合函数
class CountAgg() extends AggregateFunction[ApacheLogEvent, Long, Long] {
override def createAccumulator(): Long = 0L
override def add(value: ApacheLogEvent, accumulator: Long): Long = accumulator + 1
override def getResult(accumulator: Long): Long = accumulator
override def merge(a: Long, b: Long): Long = a + b
}
// 自定义的窗口处理函数
class WindowResult() extends WindowFunction[Long, UrlViewCount, String, TimeWindow] {
override def apply(url: String, window: TimeWindow, input: Iterable[Long], out: Collector[UrlViewCount]): Unit = {
// 输出结果
out.collect(UrlViewCount(url, window.getEnd, input.iterator.next()))
}
}
// 自定义 process function,实现排序输出
class TopNHotUrls(nSize: Int) extends KeyedProcessFunction[Long, UrlViewCount, String] {
// 定义一个状态列表,保存结果
lazy val urlState: ListState[UrlViewCount] = getRuntimeContext.getListState( new ListStateDescriptor[UrlViewCount]( "urlState", classOf[UrlViewCount] ) )
override def processElement(value: UrlViewCount, ctx: KeyedProcessFunction[Long, UrlViewCount, String]#Context, collector: Collector[String]): Unit = {
// 将数据添加至 状态 列表中
urlState.add(value)
// 根据窗口结束时间windowEnd,设置定时器
ctx.timerService().registerEventTimeTimer(value.windowEnd + 1)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, UrlViewCount, String]#OnTimerContext, out: Collector[String]): Unit = {
// 新建一个ListBuffer,用于存放状态列表中的数据
val allUrlViews: ListBuffer[UrlViewCount] = new ListBuffer[UrlViewCount]()
// 获取到状态列表
val iter: util.Iterator[UrlViewCount] = urlState.get().iterator()
while ( iter.hasNext ) {
allUrlViews += iter.next()
}
// 清除状态
urlState.clear()
// 按照 count 大小排序
val sortedUrlViews: ListBuffer[UrlViewCount] = allUrlViews.sortWith(_.count > _.count).take(nSize)
// 格式化成String打印输出
val result: StringBuilder = new StringBuilder()
result.append("=========================================\n")
// 触发定时器时,我们设置了一个延迟时间,这里我们减去延迟
result.append("时间: ").append(new Timestamp(timestamp - 1)).append("\n")
for ( i <- sortedUrlViews.indices){
val currentUrlView: UrlViewCount = sortedUrlViews(i)
// 拼接打印结果
result.append("No").append(i+1).append(":")
.append(" URL=").append(currentUrlView.url).append(" ")
.append(" 流量=").append(currentUrlView.count).append("\n")
}
result.append("=========================================\n")
// 设置休眠时间
Thread.sleep(1000)
// 输出结果
out.collect(result.toString())
}
}
# 运行效果
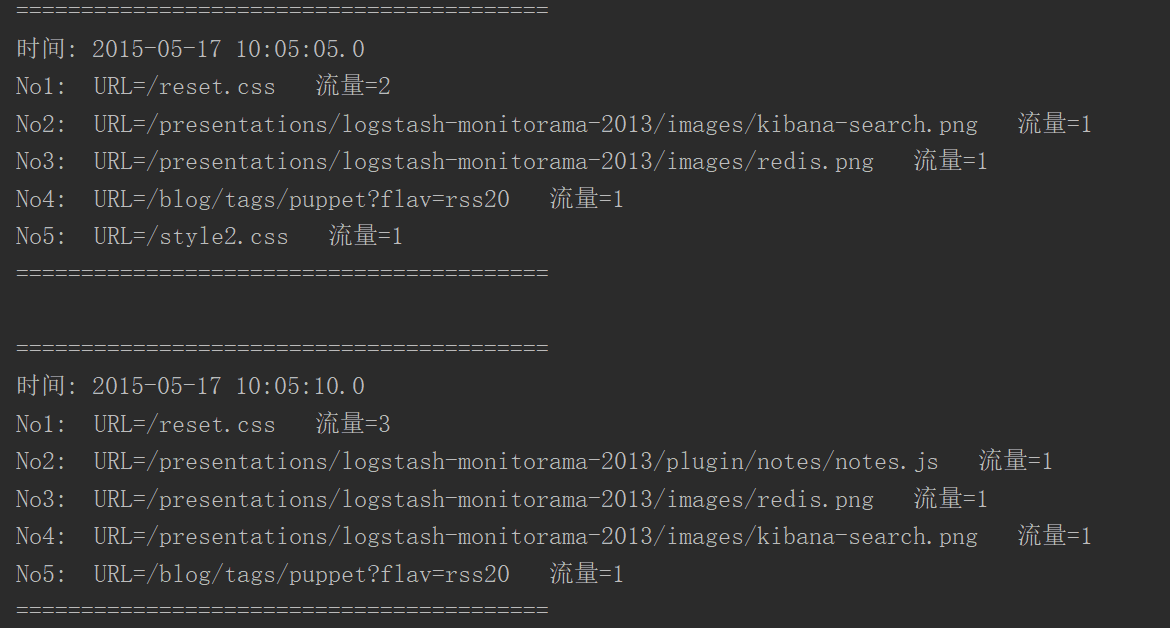
为了让小伙伴们更好理解,菌哥基本每行代码都写上了注释,就冲这波细节,还不给安排一波三连😎开个玩笑,回到主题上,我们再来讨论一个问题。
实际生产环境中,我们的数据流往往是从Kafka获取到的。如果要让代码更贴近生产实际,我们只需将source更换为Kafka即可:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
当然,根据实际的需要,我们还可以将Sink指定为Kafka、ES、Redis或其它存储,这里就不一一展开实现了。
# 参考
B站视频:https://www.bilibili.com/video/BV1y54y127h2 (opens new window)
# 小结
本期内容主要为大家分享了如何基于flink在电商用户行为分析项目中对实时流量统计模块进行开发的过程,这个跟上一期介绍的实时热门商品统计功能非常类似,对本期内容不太理解的小伙伴可以多研究上一期的精彩内容~下一期我们会介绍项目中恶意登录监控的功能开发,敬请期待!你知道的越多,你不知道的也越多,我是Alice,我们下一期见!
# 参考文章
- https://blog.csdn.net/weixin_44318830/article/details/110212749










