TIP
本文主要是介绍 Spark-用户分析系统设计 。
# 基于Spark的用户分析系统
每天有大量的用户通过浏览器、手机app、TV访问优酷土豆网站,在优酷土豆上观看视频,并且可以对视频进行评论、顶踩、收藏、转发。我们可以通过用户的行为分析用户的偏好,给用户打上各种各样的标签,比如性别、地域、使用设备、兴趣爱好等,进而找到一群用户的整体偏好,这样可以对用户或内容进行精准营销。实际应用中,我们需要搭建一个系统,通过这个系统可以很快的知道符合某些条件的用户到底有多少,比如北京的男性用户有多少、喜欢看汽车视频和动漫的用户有多少。还可以很快的知道某个视频的观众有多少、喜欢看哪个类型的节目、我的订阅用户和他的订阅用户有什么不同等等。搭这样的一个用户分析系统,我们面临的是一个大数据的问题:近一个月出现的cookie和id可能有20亿,标签的维度有成千上万,我们应该选择怎样的架构才能在几秒或十几秒之内返回用户期待的分析结果。
优酷土豆的大数据平台提供了各种各样的分布式系统,hadoop,storm,spark,hbase等等给我们使用。Hadoop的MR框架是计算不动,数据动,map过程需要写文件,不能准实时返回结果,适合离线任务;storm是流式计算,适合数据分批到达,实时处理,可以用于构建实时用户画像;hbase提供key、value的查询适合获取单个或连续的key值,不适合对随机的一群用户进行分析;spark是将所有数据加载到内存中(也可缓存在磁盘上),在内存中迭代计算,不用将中间数据写入磁盘,运算比较快,能提供准实时的服务,正是我们需要的架构。
我们调研了下,发现Ooyala已经开发一套了 Sparkas a service服务spark job server (https://github.com/spark-jobserver/spark-jobserver),RDD可以在不同的job间共享,即可以将数据永久保存在spark服务器的内存中,通过web交互式的进行提交命令,接收spark返回的结果。我们的用户分析系统在spark, spark job server的基础上进行搭建。
# 1. 系统架构
用户分析系统的基本架构如下图所示:
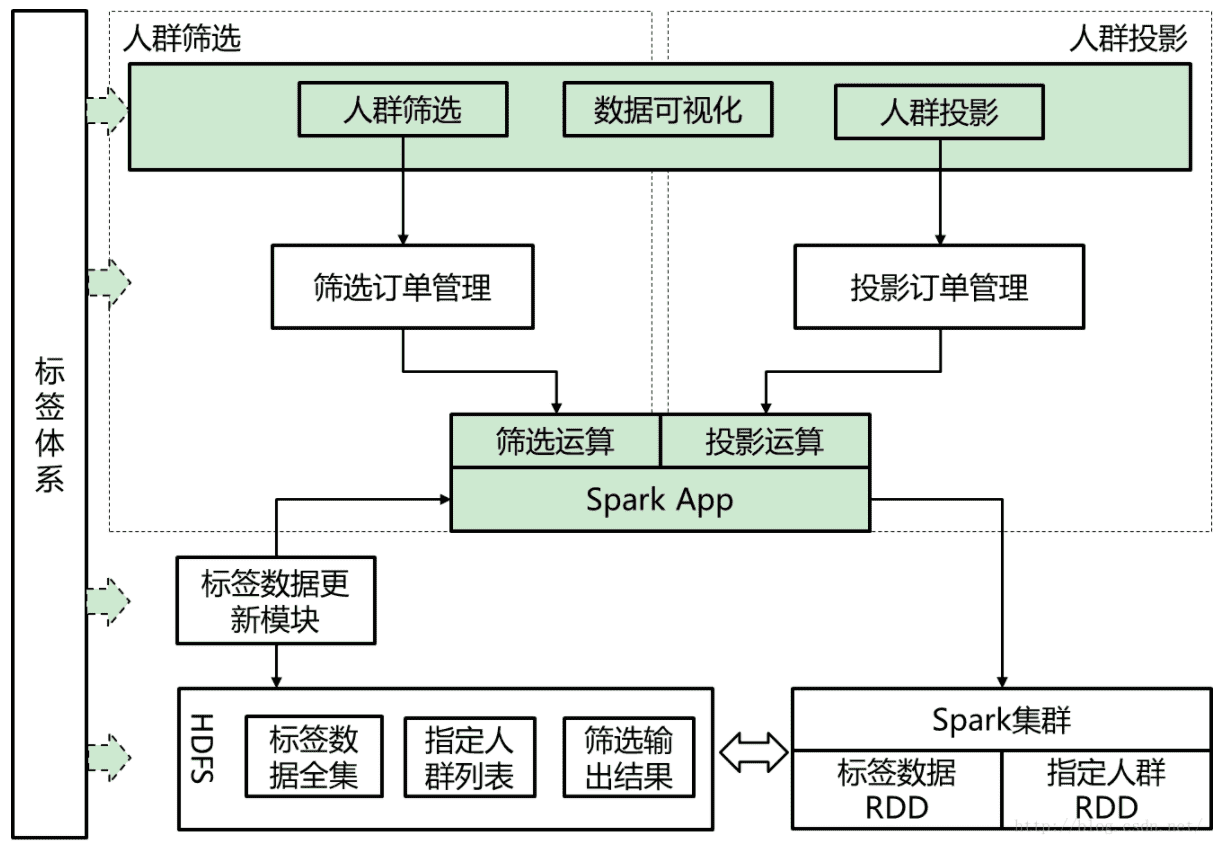
图中,标签体系为所有模块提供统一编码以及层级查询功能。人群筛选与人群投影模块各自拥有自身的订单管理系统,并且共用一个Spark App。Spark App直接与Spark集群进行交互,负责提交Spark计算任务,从HDFS上加载RDD数据。标签数据更新模块则负责将标签计算结果进行merge并且通知Spark App进行RDD数据更新。
# 1.1. 标签体系
标签体系本质的意义在于刻画用户不同维度的特征,这些维度包括用户的一些自然属性例如年龄,性别等,还包括用户的社会属性例如教育背景,经济背景等,此外还需要囊括用户的文化属性例如兴趣爱好,内容倾向等。
标签体系本身是有层级结构的,比如一级频道电影是一级标签,电影下面的二级频道是二级标签等等,不同层级标签在不同粒度上表示了用户的兴趣。我们可以给用户打上下一层级的标签时也打上上一层级的标签。这样将层级的标签扁平化,标签和标签之间在使用时是平级的。对标签进行编码,每个标签都有一个自己唯一的编码,4个字节,考虑到spark内存的限制,以及所有标签不是同时出现,我们在spark中使用的编码是一个内部编码(2或3字节),每天在做数据的时候根据标签配置表对标签进行重新编码,生成一个内部编码和唯一编码的映射表,在UP应用系统内进行转换,对用户透明。
# 1.2. 标签存储
原始的标签数据来源于算法团队或其他团队,还有一些来自第三方的数据,每个来源的标签都只是用户标签的一部分,用户分析的updater程序会每天合并所有的标签数据,并进行压缩存储为最终标签数据。示意图如下图所示:
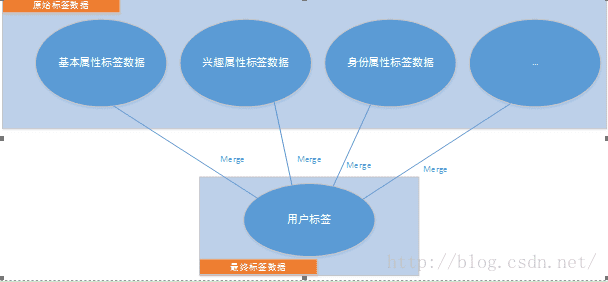
有些用户一个月的行为太少,不能计算出对应的兴趣标签,因此我们会过滤行为少的用户,只保留“真正”的用户,过滤完后,我们保留3.5亿用户进行分析,原始的标签以文本格式存储在hadoop上,每行代表一个用户。为了spark能快速加载,将原始的标签转换为SequenceFile的格式进行存储,key和value都是BytesWritable,因为将所有标签以bytes连续保存最省内存。
# 1.3. 人群筛选投影Server
人群筛选投影Server主要是接收前端用户请求,对部分请求参数进行处理,向Spark App提交操作任务,接收结果,并将结果返回给用户,其系统结构示意图如下图所示:
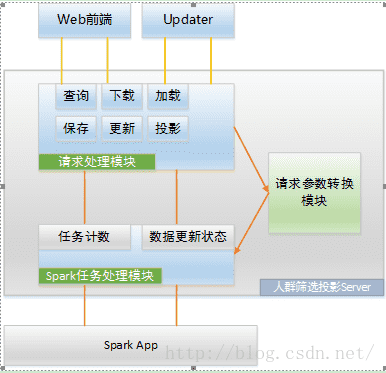
图中,SparkApp是基于Spark Job Server的api开发的主要功能模块,人群筛选投影Server的主要是中转和存储作用,将用户的分析请求转换格式发送给Spark App,将Spark App的结果封装后回复给用户,并且将结果缓存,留待用户下一次请求。
# 2. 解决的技术问题
技术方面主要是解决存储和快速的问题,存储的问题通过设计数据的存储格式来解决,对不同操作使用不同的解决方式。
# 2.1. 快速的人群筛选
人群筛选要解决的问题是如何快速的判断某个id是否满足一些条件,我们可以将条件写成一个表达式,比如(tagid1.weight>0 && tagid2.weigth>10),然后解析表达式,将id对应的标签值填入来判断表达式是否满足
实际使用中我们发现对大量数据来说这样一个个的去判断计算很慢,我们采用了Janino (opens new window)内存编译技术。将表达式写成java代码,动态编译,生成class,然后加载到内存中,调用该类的方法来判断表达式是否满足。待编译的代码如下所示:
protected final static String template =
"import com.youku.recommend.up.drill.expression.Index;\r\n" +
"import com.youku.recommend.up.drill.expression.Calculate;\r\n" +
"public class Exp implements Calculate {\r\n" +
"public boolean calculate(Index index){\r\n" +
"boolean flag=${expression};\r\n" +
"return flag;\r\n" +
"}\r\n" +
"}\r\n";
# 2.2. 快速的人群投影
两个数据集 (RDD) A,B,其中A是全量数据,包括id和标签,B数据集只包含id,需要知道B数据集中有多少id在A中存在,以及需要知道存在的id的标签统计结果,我们可以根据id对A,B俩数据集进行join来过滤出在A、B中同时存在的id,然后再统计这些id各标签的数量。
Spark原生的join会对两个RDD都进行一次shuffle,每个worker将数据根据hash值重新分发到各worker上,由于A数据集是全量数据,量非常大,而且常驻内存,而且一天才更新一次,我们不希望每次计算时都要对它进行shuffle,这样系统开销很大,我们完全可以先对A数据集进行Shuffle并且在每个partition上按照id排好序,这样A和B进行join时,A不用shuffle,只需要将B按照同样的hash算法Shuffle然后排序,再按序遍历A和B相同的partition,就能过滤出AB中同时存在的id。类似于做好工作后,求两个有序数组的交集,只需 O(M+N) 的时间就够。
# 3. 计划
用户分析中计划添加的功能主要是人群扩散,给一个种子人群,分析该人群的兴趣特征或内容偏好,找出相似的人群,扩充原有人群。
# 参考文章
- https://blog.csdn.net/ytbigdata/article/details/47154529










