TIP
本文主要是介绍 Hive优化-汇总精华总结(二) 。
# Hive总结篇及Hive的优化
# 概述
Hive学习也有一段时间了,今天来对Hive进行一个总结,谈谈自己的理解,作者还是个小白,有不对的地方请大家指出相互学习,共同进步。今天来谈一谈什么是Hive,产生背景,优势等一系列问题。
# 什么是Hive
官网地址 (opens new window) Hive wiki. (opens new window) 先来谈谈自己的理解:
有些人可能会说Hive不就是写SQL的吗,那我们其实可以从另一个角度来理解:Hive就是那么强大啊,只要写SQL就能解决问题,其实这些人说的也没错Hive确实就是写SQL的,对于传统的 DBA人员或者会写SQL就很容易上手了,但是您知道他的底层细节吗,怎么优化呢?和传统的关系型数据库又有什么区别呢?等等一系列问题。。。
Hive是一个构建在Hadoop之上的数据仓库软件,它可以使已经存储的数据结构化,它提供类似sql的查询语句HiveQL对数据进行分析处理。 Hive将HiveQL语句转换成一系列成MapReduce作业并执行(SQL转化为MapReduce的过程你知道吗?)。用户可以很方便的使用命令行和JDBC程序的方式来连接到hive。 目前,Hive除了支持MapReduce计算引擎,还支持Spark和Tez这两中分布式计算引擎。常用于离线批处理。 (Hive On Spark 还是试验版本)
# Hive的产生背景
大数据的时代,海量的数据对于传统的关系型数据库来说维护起来成本非常高,那该如何是好,Hadoop分布式的框架,可以使用廉价的机器部署分布式系统把数据存储再HDFS之上,通过MR进行计算,分析,这样是可以的,但是,MR大家应该知道,MapReduce编程带来的不便性,编程十分繁琐,在大多情况下,每个MapReduce程序需要包含Mapper、Reduceer和一个Driver,之后需要打成jar包扔到集群上运 行。如果mr写完之后,且该项目已经上线,一旦业务逻辑发生了改变,可能就会带来大规模的改动代码,然后重新打包,发布,非常麻烦(这种方式,也是最古老的方式)
当大量数据都存放在HDFS上,如何快速的对HDFS上的文件进行统计分析操作?
一般来说,想要做会有两种方式:
- 学Java、学MapReduce(十分麻烦)
- 做DBA的:写SQL(希望能通过写SQL这样的方式来实现,这种方式较好) 然而,HDFS中最关键的一点就是,数据存储HDFS上是没有schema的概念的(schema:相当于表里面有列、字段、字段名称、字段与字段之间的分隔符等,这些就是schema信息)然而HDFS上的仅仅只是一个纯的文本文件而已,那么,没有schema,就没办法使用sql进行查询了啊。。。因此,在这种背景下,就有问题产生:如何为HDFS上的文件添加Schema信息?如果加上去,是否就可以通过SQL的方式进行处理了呢?于是强大的Hive出现了。
# Hive深入剖析
再来看看官网给我们的介绍:
官方第一句话就说明了Apache Hive 是构建在Apache Hadoop之上的数据仓库。有助于对大型的数据集进行读、写和管理。
那我们先对这句话进行剖析:
首先Hive是构建在Hadoop之上的,其实就是Hive中的数据其实是存储再HDFS上的(加上LOCAL关键字则是在本地),默认在/user/hive/warehouse/table,有助于对大型数据集进行读、写和管理,那也就是意味着传统的关系型数据库已经无法满足现在的数据量了,需要一个更大的仓库来帮助我们存储,这里也引出一个问题:Hive和关系型数据库的区别,后面我们再来聊。
Hive的特征:
- 1.可通过SQL轻松访问数据的工具,从而实现数据仓库任务,如提取/转换/加载(ETL),报告和数据分析。
- 2.它可以使已经存储的数据结构化
- 3.可以直接访问存储在Apache HDFS™或其他数据存储系统(如Apache HBase™)中的文件
- 4.Hive除了支持MapReduce计算引擎,还支持Spark和Tez这两中分布式计算引擎(这里会引申出一个问题,哪些查询跑mr哪些不跑?)
- 5.它提供类似sql的查询语句HiveQL对数据进行分析处理。
- 数据的存储格式有多种,比如数据源是二进制格式, 普通文本格式等等
而hive强大之处不要求数据转换成特定的格式,而是利用hadoop本身InputFormat API来从不同的数据源读取数据,同样地使用OutputFormat API将数据写成不同的格式。所以对于不同的数据源,或者写出不同的格式就需要不同的对应的InputFormat和Outputformat类的实现。
以stored as textfile为例,其在底层java API中表现是输入InputFormat格式:TextInputFormat以及输出OutputFormat格式:HiveIgnoreKeyTextOutputFormat.这里InputFormat中定义了如何对数据源文本进行读取划分,以及如何将切片分割成记录存入表中。而Outputformat定义了如何将这些切片写回到文件里或者直接在控制台输出。
不仅如此Hive的SQL还可以通过用户定义的函数(UDF),用户定义的聚合(UDAF)和用户定义的表函数(UDTF)进行扩展。
(几个函数之间的区别)
Hive中不仅可以使用逗号和制表符分隔值(CSV / TSV)文本文件,还可以使用Sequence File、RC、ORC、Parquet
(知道这几种存储格式的区别),
当然Hive还可以通过用户来自定义自己的存储格式,基本上前面说的到的几种格式完全够了。
Hive旨在最大限度地提高可伸缩性(通过向Hadoop集群动态添加更多机器扩展),性能,可扩展性,
容错性以及与其输入格式的松散耦合。
# 安装部署
安装部署这里我们就不讲解了,不会的同学,参考作者以前的博客 (opens new window)
# Hive基本语法
该篇博客主要讲解Hive底层的东西和一些优化对于基本的东西可以参考作者以前的博客。 DDL (opens new window) DML (opens new window) 基本HQL (opens new window) 内置函数和基本的UDF函数 (opens new window)
UDF函数这里要进行一个讲解UDF、DUAF、UDTF分别是啥。 我们知道Hive的SQL还可以通过用户定义的函数(UDF),用户定义的聚合(UDAF)和用户定义的表函数(UDTF)进行扩展。 当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。 UDF(User-Defined-Function) 一进一出
UDAF(User- Defined Aggregation Funcation) 聚集函数,多进一出。
UDTF(User-Defined Table-Generating Functions) 一进多出,如lateral view explore()
# Hive于关系型数据库的区别
时效性、延时性比较高,可扩展性高;
Hive数据规模大,优势在于处理大数据集,对于小数据集没有优势
事务没什么用(比较鸡肋,没什么实际的意义,对于离线的来说) 一个小问题:那个版本开始提供了事务?
insert/update没什么实际用途,大数据场景下大多数是select
RDBMS也支持分布式,节点有限 成本高,处理的数据量小
Hadoop集群规模更大 部署在廉价机器上,处理的数据量大
数据库可以用在Online的应用中,Hive主要进行离线的大数据分析;
数据库的查询语句为SQL,Hive的查询语句为HQL;
数据库数据存储在LocalFS,Hive的数据存储在HDFS;
数据格式:Hive中有多种存储格式:由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,
因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。
而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,
数据库加载数据的过程会比较耗时。
Hive执行MapReduce,MySQL执行Executor;
# Hive的优点
1.简单易上手
2.扩展能力较好(指集群 HDFS或是YARN)
3.统一的元数据管理 metastore包括的了数据库,表,字段分区等详细信息
该篇博客对于元数据信息进行了详细的讲解 (opens new window)
4.由于统一的元数据管理所以和spark/impala等SQL引擎是通用的
通用是指,在拥有了统一的metastore之后,在Hive中创建一张表,在Spark/impala中是能用的,反之在Spark中创建一张表,
在Hive中也能用;只需要共用元数据,就可以切换SQL引擎
涉及到了Spark sql 和Hive On Spark(实验版本)
5.使用SQL语法,提供快速开发的能力,支持自定义函数UDF。
6.避免了去写mapreduce,减少开发人员学习成本。
7.数据离线处理,比如日志分析,海量数据结构化分析
# SQL转化为MapReduce的过程
了解了MapReduce实现SQL基本操作之后,我们来看看Hive是如何将SQL转化为MapReduce任务的,整个编译过程分为六个阶段:
- Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
- 遍历AST Tree,抽象出查询的基本组成单元QueryBlock
- 遍历QueryBlock,翻译为执行操作树OperatorTree
- 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
- 遍历OperatorTree,翻译为MapReduce任务
- 物理层优化器进行MapReduce任务的变换,生成最终的执行计划
可以参考美团的技术沙龙 (opens new window)
# Hive内部表和外部表的区别
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table); 区别:
- 内部表数据由Hive自身管理,外部表数据由HDFS管理;
- 内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
- 删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
# 行式存储vs列式存储
行式数据库存储在hdfs上式按行进行存储的,一个block存储一或多行数据。而列式数据库在hdfs上则是按照列进行存储,一个block可能有一列或多列数据。
如果要将数据进行压缩:
- 对于行式数据库,必然按行压缩,当一行中有多个字段,各个字段对应的数据类型可能不一致,压缩性能压缩比就比较差。
- 对于列式数据库,必然按列压缩,每一列对应的是相同数据类型的数据,故列式数据库的压缩性能要强于行式数据库。
如果要进行数据的查询:
假设执行的查询操作是:select id,name from table_emp;
- 对于行式数据库,它要遍历一整张表将每一行中的id,name字段拼接再展现出来,这样需要查询的数据量就比较大,效率低。
- 对于列式数据库,它只需找到对应的id,name字段的列展现出来即可,需要查询的数据量小,效率高。 假设执行的查询操作是:select * from table_emp;
对于这种查询整个表全部信息的操作,由于列式数据库需要将分散的行进行重新组合,行式数据库效率就高于列式数据库。 但是,在大数据领域,进行全表查询的场景少之又少,进而我们使用较多的还是列式数据库及列式储存。
# Hive哪些查询会执行mr
hive 0.10.0为了执行效率考虑,简单的查询,就是只是select,不带count,sum,group by这样的,都不走map/reduce,直接读取hdfs文件进行filter过滤。
这样做的好处就是不新开mr任务,执行效率要提高不少,但是不好的地方就是用户界面不友好,有时候数据量大还是要等很长时间,但是又没有任何返回。 改这个很简单,在hive-site.xml里面有个配置参数叫
hive.fetch.task.conversion
将这个参数设置为more,简单查询就不走map/reduce了,设置为minimal,就任何简单select都会走map/reduce
Create Table As Select (CTAS) 走mr
create table emp2 as select * from emp;
insert一条或者多条 走mr
# Hive静态分区动态分区
分区的概念
Hive的分区方式:由于Hive实际是存储在HDFS上的抽象,Hive的一个分区名对应HDFS上的一个目录名,子分区名就是子目录名,并不是一个实际字段。
分区的好处
产生背景:如果一个表中数据很多,我们查询时就很慢,耗费大量时间,如果要查询其中部分数据该怎么办呢,这是我们引入分区的概念。 Partition:分区,每张表中可以加入一个分区或者多个,方便查询,提高效率;并且HDFS上会有对应的分区目录:
语法:
Hive分区是在创建表的时候用Partitioned by 关键字定义的,但要注意,Partitioned by子句中定义的列是表中正式的列, 但是Hive下的数据文件中并不包含这些列,因为它们是目录名,真正的数据在分区目录下。
静态分区和 动态分区的区别
创建表的语法都一样
- 静态分区:加载数据的时候要指定分区的值(key=value),比较麻烦的是每次插入数据都要指定分区的值,创建多个分区多分区一样,以逗号分隔。
- 动态分区: 如果用上述的静态分区,插入的时候必须首先要知道有什么分区类型,而且每个分区写一个load data,太烦人。使用动态分区可解决以上问题,其可以根据查询得到的数据动态分配到分区里。其实动态分区与静态分区区别就是不指定分区目录,由系统自己选择。
首先,启动动态分区功能
hive> set hive.exec.dynamic.partition=true;
采用动态方式加载数据到目标表
加载之前先设置一下下面的参数
hive (default)> set hive.exec.dynamic.partition.mode=nonstrict
开始加载
insert into table emp_dynamic_partition partition(deptno)
select empno , ename , job , mgr , hiredate , sal , comm, deptno from emp;
加载数据方式并没有指定具体的分区,只是指出了分区字段。
在select最后一个字段必须跟你的分区字段,这样就会自行根据deptno的value来分区。
删除分区:
ALTER TABLE my_partition_test_table DROP IF EXISTS PARTITION (day='2018-08-08');
# Hive优化
# 1.慎用 count(distinct),count(distinct)
我们知道大数据场景下不害怕数据量大,害怕的是数据倾斜,怎样避免数据倾斜,找到可能产生数据倾斜的函数尤为关键,数据量较大的情况下,慎用count(distinct),count(distinct)容易产生倾斜问题。
# 2.设置合理的map reduce 的task数量
# map阶段优化
mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B
mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB
通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。
需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。
举例:
- a) 假设input目录下有1个文件a,大小为780M,那么hadoop会将该文件a分隔成7个块(6个128m的块和1个12m的块),从而产生7个map数
- b) 假设input目录下有3个文件a,b,c,大小分别为10m,20m,130m,那么hadoop会分隔成4个块(10m,20m,128m,2m),从而产生4个map数 即,如果文件大于块大小(128m),那么会拆分,如果小于块大小,则把该文件当成一个块。
其实这就涉及到小文件的问题:如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,
而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。
而且,同时可执行的map数是受限的。那么问题又来了。。是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,
如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
我们该如何去解决呢???
我们需要采取两种方式来解决:即减少map数和增加map数;
- 减少map数量
假设一个SQL任务:
Select count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’;
该任务的inputdir /group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04
共有194个文件,其中很多是远远小于128m的小文件,总大小9G,正常执行会用194个map任务。
Map总共消耗的计算资源: SLOTS_MILLIS_MAPS= 623,020
我通过以下方法来在map执行前合并小文件,减少map数:
set mapred.max.split.size=100000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
再执行上面的语句,用了74个map任务,map消耗的计算资源:SLOTS_MILLIS_MAPS= 333,500
对于这个简单SQL任务,执行时间上可能差不多,但节省了一半的计算资源。
大概解释一下,100000000表示100M, set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;这个参数表示执行前进行小文件合并,前面三个参数确定合并文件块的大小,大于文件块大小128m的,按照128m来分隔,小于128m,大于100m的,按照100m来分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),进行合并,最终生成了74个块。
- 增大map数量
如何适当的增加map数?
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,
来使得每个map处理的数据量减少,从而提高任务的执行效率。
假设有这样一个任务:
Select data_desc,
count(1),
count(distinct id),
sum(case when …),
sum(case when ...),
sum(…)
from a group by data_desc
如果表a只有一个文件,大小为120M,但包含几千万的记录,如果用1个map去完成这个任务,
肯定是比较耗时的,这种情况下,我们要考虑将这一个文件合理的拆分成多个,
这样就可以用多个map任务去完成。
set mapred.reduce.tasks=10;
create table a_1 as
select * from a
distribute by rand(123);
这样会将a表的记录,随机的分散到包含10个文件的a_1表中,再用a_1代替上面sql中的a表,
则会用10个map任务去完成。
每个map任务处理大于12M(几百万记录)的数据,效率肯定会好很多。
看上去,貌似这两种有些矛盾,一个是要合并小文件,一个是要把大文件拆成小文件,
这点正是重点需要关注的地方,
使单个map任务处理合适的数据量;
# reduce阶段优化
Reduce的个数对整个作业的运行性能有很大影响。如果Reduce设置的过大,那么将会产生很多小文件,
对NameNode会产生一定的影响,
而且整个作业的运行时间未必会减少;如果Reduce设置的过小,那么单个Reduce处理的数据将会加大,
很可能会引起OOM异常。
如果设置了mapred.reduce.tasks/mapreduce.job.reduces参数,那么Hive会直接使用它的值作为Reduce的个数;
如果mapred.reduce.tasks/mapreduce.job.reduces的值没有设置(也就是-1),那么Hive会
根据输入文件的大小估算出Reduce的个数。
根据输入文件估算Reduce的个数可能未必很准确,因为Reduce的输入是Map的输出,而Map的输出可能会比输入要小,
所以最准确的数根据Map的输出估算Reduce的个数。
- Hive自己如何确定reduce数:
reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)hive.exec.reducers.max(每个任务最大的reduce数,默认为999) 计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1) 即,如果reduce的输入(map的输出)总大小不超过1G,那么只会有一个reduce任务;
如:select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;
/group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04 总大小为9G多,
因此这句有10个reduce
- 调整reduce个数方法一:
调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt; 这次有20个reduce
- 调整reduce个数方法二;
set mapred.reduce.tasks = 15;
select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;这次有15个reduce
- reduce个数并不是越多越好;
同map一样,启动和初始化reduce也会消耗时间和资源;
另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,
则也会出现小文件过多的问题;
- 什么情况下只有一个reduce; 很多时候你会发现任务中不管数据量多大,不管你有没有设置调整reduce个数的参数,任务中一直都只有一个reduce任务; 其实只有一个reduce任务的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer参数值的情况外,还有以下原因:
- 没有group by的汇总,比如把select pt,count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’ group by pt; 写成 select count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’; 这点非常常见,希望大家尽量改写。
- 用了Order by
- 有笛卡尔积 通常这些情况下,除了找办法来变通和避免,我暂时没有什么好的办法,因为这些操作都是全局的,所以hadoop不得不用一个reduce去完成; 同样的,在设置reduce个数的时候也需要考虑这两个原则:使大数据量利用合适的reduce数;使单个reduce任务处理合适的数据量;
# 合并小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。
对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
用于设置合并属性的参数有:
是否合并Map输出文件:hive.merge.mapfiles=true(默认值为真)
是否合并Reduce 端输出文件:hive.merge.mapredfiles=false(默认值为假)
合并文件的大小:hive.merge.size.per.task=256*1000*1000(默认值为 256000000)
Hive优化之小文件问题及其解决方案 小文件是如何产生的 1.动态分区插入数据,产生大量的小文件,从而导致map数量剧增。
2.reduce数量越多,小文件也越多(reduce的个数和输出文件是对应的)。
3.数据源本身就包含大量的小文件。
# 小文件问题的影响
1.从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能。
2.在HDFS中,每个小文件对象约占150byte,如果小文件过多会占用大量内存。这样NameNode内存容量严重制约了集群的扩展。
# 小文件问题的解决方案
从小文件产生的途经就可以从源头上控制小文件数量,方法如下:
1.使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件。
2.减少reduce的数量(可以使用参数进行控制)。
3.少用动态分区,用时记得按distribute by分区。
对于已有的小文件,我们可以通过以下几种方案解决:
1.使用hadoop archive命令把小文件进行归档。
2.重建表,建表时减少reduce数量。
3.通过参数进行调节,设置map/reduce端的相关参数,如下:
设置map输入合并小文件的相关参数:
[java] view plain copy
//每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256000000;
//一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
设置map输出和reduce输出进行合并的相关参数:
[java] view plain copy
//设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
//设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
//设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=16000000
# 3.Write good SQL
说道sql优化很惭愧,自己sql很烂,不多比比了,但是sql优化确实很关键。。。
# 4.存储格式:
可以使用列裁剪,分区裁剪,orc,parquet等存储格式。参考该博客 (opens new window)
Hive支持ORCfile,这是一种新的表格存储格式,通过诸如谓词下推,压缩等技术来提高执行速度提升。
对于每个HIVE表使用ORCFile应该是一件容易的事情,并且对于获得HIVE查询的快速响应时间非常有益。
作为一个例子,考虑两个大表A和B(作为文本文件存储,其中一些列未在此处指定,即行试存储的缺点)以及一个简单的查询,如:
SELECT A.customerID, A.name, A.age, A.address join
B.role, B.department, B.salary
ON A.customerID=B.customerID;
此查询可能需要很长时间才能执行,因为表A和B都以TEXT形式存储,进行全表扫描。
将这些表格转换为ORCFile格式通常会显着减少查询时间:
ORC支持压缩存储(使用ZLIB或如上所示使用SNAPPY),但也支持未压缩的存储。
CREATE TABLE A_ORC (
customerID int, name string, age int, address string
) STORED AS ORC tblproperties (“orc.compress" = “SNAPPY”);
INSERT INTO TABLE A_ORC SELECT * FROM A;
CREATE TABLE B_ORC (
customerID int, role string, salary float, department string
) STORED AS ORC tblproperties (“orc.compress" = “SNAPPY”);
INSERT INTO TABLE B_ORC SELECT * FROM B;
SELECT A_ORC.customerID, A_ORC.name,
A_ORC.age, A_ORC.address join
B_ORC.role, B_ORC.department, B_ORC.salary
ON A_ORC.customerID=B_ORC.customerID;
# 5.压缩格式:
大数据场景下存储格式压缩格式尤为关键,可以提升计算速度,减少存储空间,降低网络io,磁盘io,所以要选择合适的压缩格式和存储格式,那么首先就了解这些东西,作者以前博客已经进行了详细的说明,参考该博客 (opens new window)
# 6.MAP JOIN
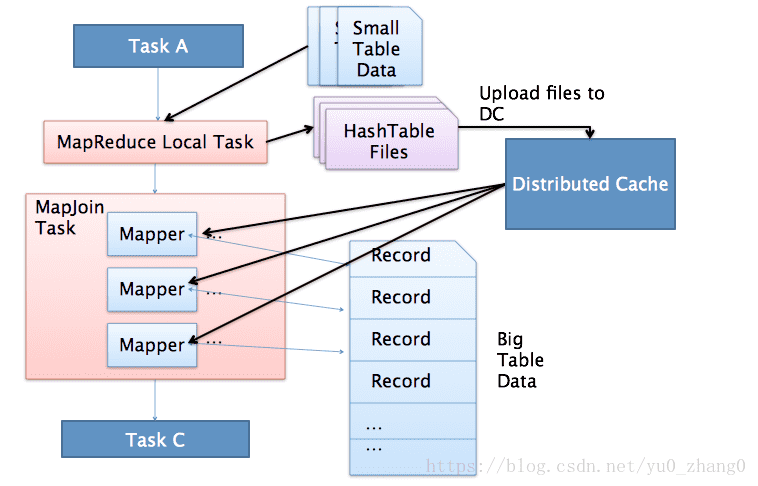
MapJoin简单说就是在Map阶段将小表读入内存,顺序扫描大表完成Join。
上图是Hive MapJoin的原理图,出自Facebook工程师Liyin Tang的一篇介绍Join优化的slice,从图中可以看出MapJoin分为两个阶段:
- (1)通过MapReduce Local Task,将小表读入内存,生成HashTableFiles上传至Distributed Cache中,这里会对HashTableFiles进行压缩。
- (2)MapReduce Job在Map阶段,每个Mapper从Distributed Cache读取HashTableFiles到内存中,顺序扫描大表,在Map阶段直接进行Join,将数据传递给下一个MapReduce任务。
也就是在map端进行join避免了shuffle。
# 7.引擎的选择
Hive可以使用ApacheTez执行引擎而不是古老的Map-Reduce引擎。
我不会详细讨论在这里提到的使用Tez的许多好处; 相反,我想提出一个简单的建议:
如果它没有在您的环境中默认打开,请在您的Hive查询的开头将以下内容设置为'true'来使用Tez:
设置hive.execution.engine = tez;
通过上述设置,您执行的每个HIVE查询都将利用Tez。
目前Hive On Spark还处于试验阶段,慎用。。
# 8.Use Vectorization
向量化查询执行通过一次性批量执行1024行而不是每次单行执行,从而提高扫描,聚合,筛选器和连接等操作的性能。
在Hive 0.13中引入,此功能显着提高了查询执行时间,并可通过两个参数设置轻松启用:
设置hive.vectorized.execution.enabled = true;
设置hive.vectorized.execution.reduce.enabled = true;
# 9.cost based query optimization
Hive 自0.14.0开始,加入了一项”Cost based Optimizer”来对HQL执行计划进行优化,这个功能通
过”hive.cbo.enable”来开启。在Hive 1.1.0之后,这个feature是默认开启的,它可以自动优化HQL中多个JOIN的顺序,并
选择合适的JOIN算法.
Hive在提交最终执行前,优化每个查询的执行逻辑和物理执行计划。这些优化工作是交给底层来完成。
根据查询成本执行进一步的优化,从而产生潜在的不同决策:如何排序连接,执行哪种类型的连接,并行度等等。
要使用基于成本的优化(也称为CBO),请在查询开始处设置以下参数:
设置hive.cbo.enable = true;
设置hive.compute.query.using.stats = true;
设置hive.stats.fetch.column.stats = true;
设置hive.stats.fetch.partition.stats = true;
# 10.模式选择
# 本地模式
对于大多数情况,Hive可以通过本地模式在单台机器上处理所有任务。
对于小数据,执行时间可以明显被缩短。通过set hive.exec.mode.local.auto=true(默认为false)设置本地模式。
hive> set hive.exec.mode.local.auto;
hive.exec.mode.local.auto=false
# 并行模式
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。
默认情况下,Hive一次只会执行一个阶段,由于job包含多个阶段,而这些阶段并非完全互相依赖,
即:这些阶段可以并行执行,可以缩短整个job的执行时间。设置参数:set hive.exec.parallel=true,或者通过配置文件来完成。
hive> set hive.exec.parallel;
hive.exec.parallel=false
# 严格模式
Hive提供一个严格模式,可以防止用户执行那些可能产生意想不到的影响查询,通过设置
Hive.mapred.modestrict来完成
set Hive.mapred.modestrict;
Hive.mapred.modestrict is undefined
# 11.JVM重用
Hadoop通常是使用派生JVM来执行map和reduce任务的。这时JVM的启动过程可能会造成相当大的开销,
尤其是执行的job包含偶成百上千的task任务的情况。JVM重用可以使得JVM示例在同一个job中时候使用N此。
通过参数mapred.job.reuse.jvm.num.tasks来设置。
# 12.推测执行
Hadoop推测执行可以触发执行一些重复的任务,尽管因对重复的数据进行计算而导致消耗更多的计算资源,
不过这个功能的目标是通过加快获取单个task的结果以侦测执行慢的TaskTracker加入到没名单的方式来提高整体的任务执行效率。
Hadoop的推测执行功能由2个配置控制着,通过mapred-site.xml中配置
mapred.map.tasks.speculative.execution=true
mapred.reduce.tasks.speculative.execution=true
# 参考文章
- https://blog.csdn.net/yu0_zhang0/article/details/81776459










