TIP
本文主要是介绍 Hive-综合知识连载 ,主要包含 Hive 表类型,Hive数据抽样,Hive计算引擎。
# Hive-综合知识连载
# 大数据之Hive(二):Hive 表类型
# 2.1 Hive 数据类型
Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,TIMESTAMP(V0.8.0+)和BINARY(V0.8.0+)。
Hive的集合类型有:STRUCT,MAP和ARRAY。
Hive主要有四种数据模型(即表):内部表、外部表、分区表和桶表。
表的元数据保存传统的数据库的表中,当前hive只支持Derby和MySQL数据库。
# 2.2 Hive 内部表
Hive中的内部表和传统数据库中的表在概念上是类似的,Hive的每个表都有自己的存储目录,除了外部表外,所有的表数据都存放在配置在`hive-site.xml`文件的`${hive.metastore.warehouse.dir}/table_name`目录下。
创建内部表:
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
grade STRING COMMOT '班级')COMMONT '学生表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS TEXTFILE;
# 2.3 Hive 外部表
被external修饰的为外部表(external table),外部表指向已经存在在Hadoop HDFS上的数据,除了在删除外部表时只删除元数据而不会删除表数据外,其他和内部表很像。
创建外部表:
CREATE EXTERNAL TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
class STRING COMMOT '班级')COMMONT '学生表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE
LOCATION '/usr/test/data/students.txt';
# 2.4 Hive 分区表
分区表的每一个分区都对应数据库中相应分区列的一个索引,但是其组织方式和传统的关系型数据库不同。在Hive中,分区表的每一个分区都对应表下的一个目录,所有的分区的数据都存储在对应的目录中。
比如说,分区表partitinTable有包含nation(国家)、ds(日期)和city(城市)3个分区,其中nation = china,ds = 20130506,city = Shanghai则对应HDFS上的目录为:
/datawarehouse/partitinTable/nation=china/city=Shanghai/ds=20130506/。
分区中定义的变量名不能和表中的列相同。
创建分区表:
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
class STRING COMMOT '班级')COMMONT '学生表'
PARTITIONED BY (ds STRING,country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE;
# 2.5 Hive 分桶表
桶表就是对指定列进行哈希(hash)计算,然后会根据hash值进行切分数据,将具有不同hash值的数据写到每个桶对应的文件中。
将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。
创建分桶表:
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,
class STRING COMMOT '班级',score SMALLINT COMMOT '总分')COMMONT '学生表'
PARTITIONED BY (ds STRING,country STRING)
CLUSTERED BY(user_no) SORTED BY(score) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE;
# 2.6 Hive 视图
在 Hive 中,视图是逻辑数据结构,可以通过隐藏复杂数据操作(Joins, 子查询, 过滤,数据扁平化)来于简化查询操作。
与关系数据库不同的是,Hive视图并不存储数据或者实例化。一旦创建 HIve 视图,它的 schema 也会立刻确定下来。对底层表后续的更改(如 增加新列)并不会影响视图的 schema。如果底层表被删除或者改变,之后对视图的查询将会 failed。基于以上 Hive view 的特性,我们在ETL和数据仓库中对于经常变化的表应慎重使用视图。
创建视图:
CREATE VIEW employee_skills
AS
SELECT name, skills_score['DB'] AS DB,
skills_score['Perl'] AS Perl,
skills_score['Python'] AS Python,
skills_score['Sales'] as Sales,
skills_score['HR'] as HR
FROM employee;
创建视图的时候是不会触发 MapReduce 的 Job,因为只存在元数据的改变。
但是,当对视图进行查询的时候依然会触发一个 MapReduce Job 进程:SHOW CREATE TABLE 或者 DESC FORMATTED TABLE 语句来显示通过 CREATE VIEW 语句创建的视图。以下是对Hive 视图的 DDL操作:
更改视图的属性:
ALTER VIEW employee_skills
SET TBLPROPERTIES ('comment' = 'This is a view');
重新定义视图:
ALTER VIEW employee_skills AS
SELECT * from employee ;
删除视图:
DROP VIEW employee_skills;
# 【----------------------------】
# 大数据之Hive(三):Hive数据抽样
当数据规模不断膨胀时,我们需要找到一个数据的子集来加快数据分析效率。因此我们就需要通过筛选和分析数据集为了进行模式 & 趋势识别。目前来说有三种方式来进行抽样:随机抽样,桶表抽样,和块抽样。
# 3.1 随机抽样
关键词:rand()函数。
使用rand()函数进行随机抽样,limit关键字限制抽样返回的数据,其中rand函数前的distribute和sort关键字可以保证数据在mapper和reducer阶段是随机分布的。
案例如下:
select * from table_name
where col=xxx
distribute by rand() sort by rand()
limit num;
使用order 关键词:
案例如下:
select * from table_name
where col=xxx
order by rand()
limit num;
经测试对比,千万级数据中进行随机抽样 order by方式耗时更长,大约多30秒左右。
# 3.2 块抽样
关键词:tablesample()函数。
- tablesample(n percent) 根据hive表数据的大小按比例抽取数据,并保存到新的hive表中。如:抽取原hive表中10%的数据
注意:测试过程中发现,select语句不能带where条件且不支持子查询,可通过新建中间表或使用随机抽样解决。
select * from xxx tablesample(10 percent) 数字与percent之间要有空格
- tablesample(nM) 指定抽样数据的大小,单位为M。
select * from xxx tablesample(20M) 数字与M之间不要有空格
- tablesample(n rows) 指定抽样数据的行数,其中n代表每个map任务均取n行数据,map数量可通过hive表的简单查询语句确认(关键词:number of mappers: x)
select * from xxx tablesample(100 rows) 数字与rows之间要有空格
# 3.3 桶表抽样
关键词:tablesample (bucket x out of y [on colname])。
其中x是要抽样的桶编号,桶编号从1开始,colname表示抽样的列,y表示桶的数量。
hive中分桶其实就是根据某一个字段Hash取模,放入指定数据的桶中,比如将表table_1按照ID分成100个桶,其算法是hash(id) % 100,这样,hash(id) % 100 = 0的数据被放到第一个桶中,hash(id) % 100 = 1的记录被放到第二个桶中。创建分桶表的关键语句为:CLUSTER BY语句。
例如:将表随机分成10组,抽取其中的第一个桶的数据:
select * from table_01
tablesample(bucket 1 out of 10 on rand())
# 【----------------------------】
# 大数据之Hive(四):Hive计算引擎
目前Hive支持MapReduce、Tez和Spark 三种计算引擎。
# 4.1 MR计算引擎
MR运行的完整过程:
Map在读取数据时,先将数据拆分成若干数据,并读取到Map方法中被处理。数据在输出的时候,被分成若干分区并写入内存缓存(buffer)中,内存缓存被数据填充到一定程度会溢出到磁盘并排序,当Map执行完后会将一个机器上输出的临时文件进行归并存入到HDFS中。
当Reduce启动时,会启动一个线程去读取Map输出的数据,并写入到启动Reduce机器的内存中,在数据溢出到磁盘时会对数据进行再次排序。当读取数据完成后会将临时文件进行合并,作为Reduce函数的数据源。
# 4.2 Tez计算引擎
Apache Tez是进行大规模数据处理且支持DAG作业的计算框架,它直接源于MapReduce框架,除了能够支持MapReduce特性,还支持新的作业形式,并允许不同类型的作业能够在一个集群中运行。
Tez将原有的Map和Reduce两个操作简化为一个概念——Vertex,并将原有的计算处理节点拆分成多个组成部分:Vertex Input、Vertex Output、Sorting、Shuffling和Merging。计算节点之间的数据通信被统称为Edge,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
通过允许Apache Hive运行复杂的DAG任务,Tez可以用来处理数据,之前需要多个MR jobs,现在一个Tez任务中。
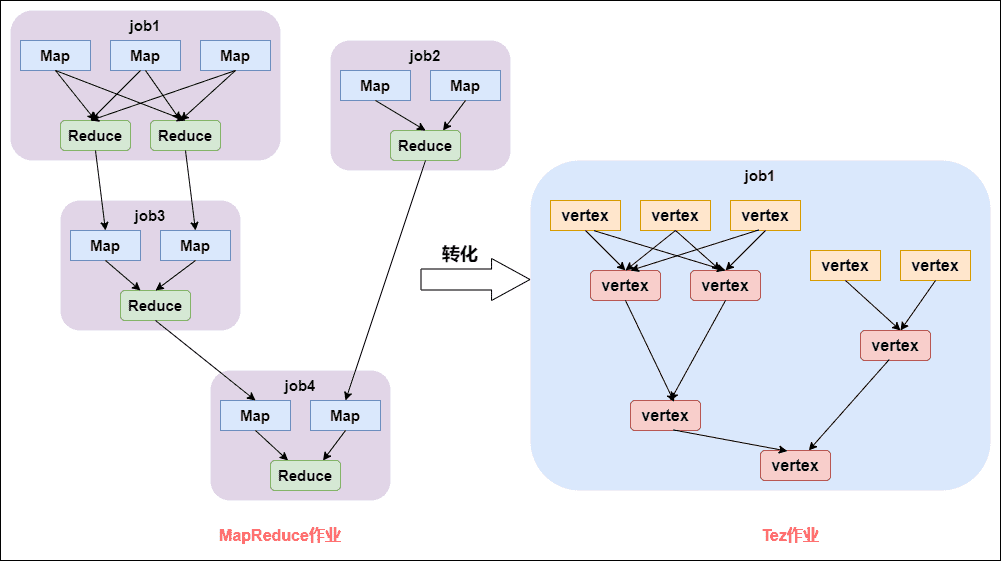
Tez和MapReduce作业的比较:
- Tez绕过了MapReduce很多不必要的中间的数据存储和读取的过程,直接在一个作业中表达了MapReduce需要多个作业共同协作才能完成的事情。
- Tez和MapReduce一样都运行使用YARN作为资源调度和管理。但与MapReduce on YARN不同,Tez on YARN并不是将作业提交到ResourceManager,而是提交到AMPoolServer的服务上,AMPoolServer存放着若干已经预先启动ApplicationMaster的服务。
- 当用户提交一个作业上来后,AMPoolServer从中选择一个ApplicationMaster用于管理用户提交上来的作业,这样既可以节省ResourceManager创建ApplicationMaster的时间,而又能够重用每个ApplicationMaster的资源,节省了资源释放和创建时间。
Tez相比于MapReduce有几点重大改进:
- 当查询需要有多个reduce逻辑时,Hive的MapReduce引擎会将计划分解,每个Redcue提交一个MR作业。这个链中的所有MR作业都需要逐个调度,每个作业都必须从HDFS中重新读取上一个作业的输出并重新洗牌。而在Tez中,几个reduce接收器可以直接连接,数据可以流水线传输,而不需要临时HDFS文件,这种模式称为MRR(Map-reduce-reduce*)。
- Tez还允许一次发送整个查询计划,实现应用程序动态规划,从而使框架能够更智能地分配资源,并通过各个阶段流水线传输数据。对于更复杂的查询来说,这是一个巨大的改进,因为它消除了IO/sync障碍和各个阶段之间的调度开销。
- 在MapReduce计算引擎中,无论数据大小,在洗牌阶段都以相同的方式执行,将数据序列化到磁盘,再由下游的程序去拉取,并反序列化。Tez可以允许小数据集完全在内存中处理,而MapReduce中没有这样的优化。仓库查询经常需要在处理完大量的数据后对小型数据集进行排序或聚合,Tez的优化也能极大地提升效率。
# 4.3 Spark计算引擎
Apache Spark是专为大规模数据处理而设计的快速、通用支持DAG(有向无环图)作业的计算引擎,类似于Hadoop MapReduce的通用并行框架,可用来构建大型的、低延迟的数据分析应用程序。
Spark是用于大规模数据处理的统一分析引擎,基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。
Spark运行流程
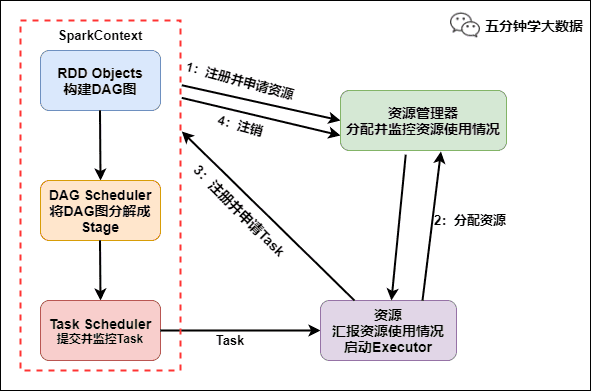
Spark运行流程
Spark具有以下几个特性。
1.高效性
Spark会将作业构成一个DAG,优化了大型作业一些重复且浪费资源的操作,对查询进行了优化,重新编写了物理执行引擎,如可以实现MRR模式。
2.易用性
Spark不同于MapReducer只提供两种简单的编程接口,它提供了多种编程接口去操作数据,这些操作接口如果使用MapReduce去实现,需要更多的代码。Spark的操作接口可以分为两类:transformation(转换)和action(执行)。Transformation包含map、flatmap、distinct、reduceByKey和join等转换操作;Action包含reduce、collect、count和first等操作。
3.通用性
Spark针对实时计算、批处理、交互式查询,提供了统一的解决方案。但在批处理方面相比于MapReduce处理同样的数据,Spark所要求的硬件设施更高,MapReduce在相同的设备下所能处理的数据量会比Spark多。所以在实际工作中,Spark在批处理方面只能算是MapReduce的一种补充。
4.兼容性
Spark和MapReduce一样有丰富的产品生态做支撑。例如Spark可以使用YARN作为资源管理器,Spark也可以处理Hbase和HDFS上的数据。
# 参考文章
- https://blog.csdn.net/weixin_44291548/article/details/119764694
- https://blog.csdn.net/weixin_44291548/article/details/119764765
- https://blog.csdn.net/weixin_44291548/article/details/119764782
- https://blog.csdn.net/weixin_44291548/article/details/119764835










