TIP
本文主要是介绍 Hive优化-优化策略总结 。
# Hive优化策略
# hive优化目标
在有限的资源下,运行效率高。
常见问题 数据倾斜、Map数设置、Reduce数设置等
hive运行
# 查看运行计划
explain [extended] hql
例子
explain select no,count(*) from testudf group by no;
explain extended select no,count(*) from testudf group by no;
运行阶段 STAGE DEPENDENC1ES:
Stage-1 is a root stage
Stage-0 is a root stage
Map阶段
Map Operator Tree:
TableScan
alias: testudf
Statistics: Num rows: 0 Data size: 30 Basic stats: PARTIAL Column stats: NONE
Select Operator
expressions: no (type: string)
outputColumnNames: no
Statistics: Num rows: 0 Data size: 30 Basic stats: PARTIAL Column stats : NONE
Group By Operator
aggregations: count()
keys: no (type: string)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 0 Data size: 30 Basic stats: PARTIAL Column sta ts: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 0 Data size: 30 Basic stats: PARTIAL Column s tats: NONE
value expressions: _col1 (type: bigint)
reduce阶段
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: string)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 0 Data size: 0 Basic stats: NONE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col1 (type: bigint)
outputColumnNames: _col0, _col1
Statistics: Num rows: 0 Data size: 0 Basic stats: NONE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 0 Data size: 0 Basic stats: NONE Column stats: NO NE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutput Format
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
hive (liguodong)> explain extended select no,count(*) from testudf group by no;
OK
Explain
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
testudf
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_TABLE_OR_COL
no
TOK_SELEXPR
TOK_FUNCTIONSTAR
count
TOK_GROUPBY
TOK_TABLE_OR_COL
no
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: testudf
Statistics: Num rows: 0 Data size: 30 Basic stats: PARTIAL Column stats: NONE
GatherStats: false
Select Operator
expressions: no (type: string)
outputColumnNames: no
Statistics: Num rows: 0 Data size: 30 Basic stats: PARTIAL Column stats: NONE
Group By Operator
aggregations: count()
keys: no (type: string)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 0 Data size: 30 Basic stats: PARTIAL Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 0 Data size: 30 Basic stats: PARTIAL Column stats: NONE
tag: -1
value expressions: _col1 (type: bigint)
Path -> Alias:
hdfs://nameservice1/user/hive/warehouse/liguodong.db/testudf [testudf]
Path -> Partition:
hdfs://nameservice1/user/hive/warehouse/liguodong.db/testudf
Partition
base file name: testudf
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
properties:
COLUMN_STATS_ACCURATE true
bucket_count -1
columns no,num
columns.comments
columns.types string:string
field.delim
file.inputformat org.apache.hadoop.mapred.TextInputFormat
file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
line.delim
location hdfs://nameservice1/user/hive/warehouse/liguodong.db/testudf
name liguodong.testudf
numFiles 1
numRows 0
rawDataSize 0
serialization.ddl struct testudf { string no, string num}
serialization.format
serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
totalSize 30
transient_lastDdlTime 1437374988
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
properties:
COLUMN_STATS_ACCURATE true
bucket_count -1
columns no,num
columns.comments
columns.types string:string
field.delim
file.inputformat org.apache.hadoop.mapred.TextInputFormat
file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
line.delim
location hdfs://nameservice1/user/hive/warehouse/liguodong.db/testudf
name liguodong.testudf
numFiles 1
numRows 0
rawDataSize 0
serialization.ddl struct testudf { string no, string num}
serialization.format
serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
totalSize 30
transient_lastDdlTime 1437374988
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
name: liguodong.testudf
name: liguodong.testudf
Truncated Path -> Alias:
/liguodong.db/testudf [testudf]
Needs Tagging: false
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: string)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 0 Data size: 0 Basic stats: NONE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col1 (type: bigint)
outputColumnNames: _col0, _col1
Statistics: Num rows: 0 Data size: 0 Basic stats: NONE Column stats: NONE
File Output Operator
compressed: false
GlobalTableId: 0
directory: hdfs://nameservice1/tmp/hive-root/hive_2015-07-21_09-51-37_330_7990199479532530033-1/-mr-10000/.hive-staging_hive_2015-07-21_09-51-37_330_7990199479532530033-1/-ext-10001
NumFilesPerFileSink: 1
Statistics: Num rows: 0 Data size: 0 Basic stats: NONE Column stats: NONE
Stats Publishing Key Prefix: hdfs://nameservice1/tmp/hive-root/hive_2015-07-21_09-51-37_330_7990199479532530033-1/-mr-10000/.hive-staging_hive_2015-07-21_09-51-37_330_7990199479532530033-1/-ext-10001/
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
properties:
columns _col0,_col1
columns.types string:bigint
escape.delim \
hive.serialization.extend.nesting.levels true
serialization.format 1
serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
TotalFiles: 1
GatherStats: false
MultiFileSpray: false
Stage: Stage-0
Fetch Operator
limit: -1
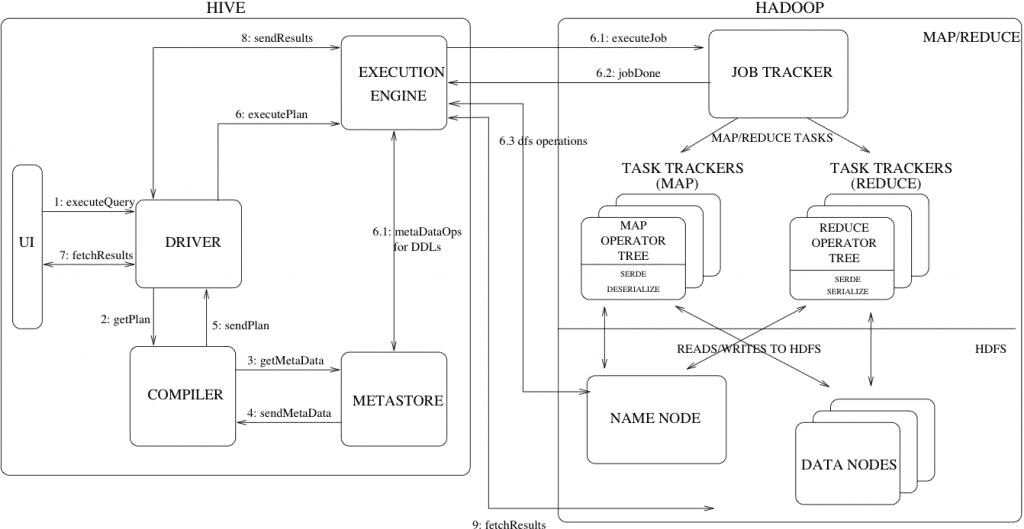
# HIVE运行过程
# hive表优化
# 分区
静态分区 动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partltlon.mode=nonstrict;
# 分桶
set hive.enforce.bucketing=true;
set hive.enforce.sorting=true;
**表优化数据目标:**同样数据尽量聚集在一起
# Hive job优化
# 并行化运行
每一个查询被hive转化成多个阶段,有些阶段关联性不大,则能够并行化运行,降低运行时问。
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=8;
eg:
select num
from
(select count(city) as num from city
union all
select count(province) as num from province
)tmp;
# 本地化运行
set hive.exec.mode.local.auto=true;
当一个job满足例如以下条件才干真正使用本地模式: 1.job的输入数据大小必须小于參数:
hive.exec.mode.local.inputbytes.max(默认128MB)
2.job的map数必须小于參数:
hive.exec.mode.local.auto.tasks.max(默认4)
3.job的reduce数必须为0或者1
# job合并输入小文件
set hive.input.format=
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
合并文件数由mapred.max.split.size限制的大小决定。
# job合并输出小文件
set hive.merge.smallfiles.avgsize=256000000;当输出文件平均大小小于该值。启动新job合并文件
set hive.merge.size.per.task=64000000;合并之后的文件大小
# JVM重利用
set mapred.job.reuse.jvm.num.tasks=20;
JVM重利用能够是job长时间保留slot,直到作业结束,这在对于有较多任务和较多小文件的任务是很有意义的,降低运行时间。当然这个值不能设置过大,由于有些作业会有reduce任务,假设reduce任务没有完毕,则map任务占用的slot不能释放。其它的作业可能就须要等待。
# 压缩数据
中间压缩就是处理hive查询的多个job之间的数据。对中间压缩, 最好选择一个节省CPU耗时的压缩方式。
set hive.exec.compress.intermediate=true。
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
set hive.intermediate.compression.type=BLOCK;
终于的输出也能够压缩,选择一个压缩效果比較好的,节省了磁盘空间,可是cpu比較耗时。
set hive.exec.compress.output=true;
set mapred.output.compression.codec=
org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compression.type=BLOCK:
# Hive SQL语句优化
# join优化
hive.optimize.skewjoin=true; 假设是join过程出现倾斜应该设置为true
set hive.skewjoin.key=100000; 这个是join的键相应的记录条数超过这个值则会进行优化。
# mapjoin
自己主动运行
set hive.auto.convert.join=true;
hive.mapjoin.smalltable.filesize默认值是25mb
手动运行
select /*+mapjoin(A)*/ f.a,f.b from A t join B f on(f.a==t.a)
简单总结一下,mapjoin的使用场景:
- 1、关联操作中有一张表很小
- 2、(不等值)的链接操作时
注:小表尽量设置小一点或用手动方式。
# bucket join
两个表以同样方式划分捅。
两个表的桶个数是倍数关系。
create table ordertab(cid int,price,float)clustered by(cid) into 32 buckets;
create table customer(id int,first string)clustered by(id) into 32 buckets;
select price from ordertab t join customer s on t.cid=s.id
# 改动where的位置进行优化
join优化前
select m.cid, u.id from order m join customer u on m.cid=u.id
where m.dt='2013-12-12
join优化后
select m.cid, u.id from
(select cid from order where dt='2013-12-12') m
join customer u on m.cid=u.id;
这样就能降低join连接的数据量。
# group by优化
hive.groupby.skewindata=true;
假设是group by过程出现倾斜应该设置为true。
set hive.groupby.mapaggr.checkinterval=100000;
这个是group的键相应的记录条数超过这个值则会进行优化。
# count distinct优化
优化前(启动一个job,数据量大时,一个reduce负载过重)
select count(distinct id) from tablename;
优化后(启动两个job)
select count(1) from (select distinct id from tablename)tmp;
select count(1) from (select id from tablename group by id)tmp;
# union all优化
优化前
select a,sum(b),count(distinct c),count(distinct d) from test group by a;
优化后
select a, sum(b) as b,count(c) as c, count(d) as d
from(
select a, 0 as b, c, null as d from test group by a,c
union all
select a, 0 as b, null as c, d from test group by a,d
union all
select a,b,null as c,null as d from test
)tmpl
group by a;
# Hive Map/Reduce优化
# Map优化
改动map个数进行优化
直接设置mapred.map.tasks无效 set mapred.map.tasks=10。
map个数的计算过程 (1)默认map个数
default_num=total_size/block_size;
(2)期望大小
goal_num=mapred.map.tasks;
(3)设置处理的文件大小
split_size=max(mapred.min.split.size,b1ock_size);
split_num=total_size/split_size;
(4)计算的map个数
compute_map_num=min(split_num,max(default_num,goal_num))
经过以上的分析。在设置map个数的时候,能够简单的总结为下面几点:
- 1)假设想添加map个数,则设置mapred.map.tasks为一个较大的值。
- 2)假设想减小map个数。则设置mapred.min.split.size为一个较大的值。有例如以下两种情况:
情况1:输入文件size巨大。但不是小文件增大mapred.min.split.size的值。
情况2:输入文件数量巨大,且都是小文件,就是单个文件的size小于blockSize。
这样的情况通过增大mapred.min.spllt.size不可行,
须要使用CombineFileInputFormat将多个input path合并成一个
InputSplit送给mapper处理,从而降低mapper的数量。
map端聚合
map阶段进行combiner
set hive.map.aggr=true:
猜測运行
启动多个同样的map,谁先运行完。用谁的。
set mapred.map.tasks.speculative.execution=true
# shuffle优化
依据须要配置相应參数。 Map端
- io.sort.mb
- io.sort.spill.percent
- min.num.spill.for.combine
- io.sort.factor
- io.sort.record.percent
Reduce端
- mapred.reduce.parallel.copies
- mapred.reduce.copy.backoff
- io.sort.factor
- mapred.job.shuffle.input.buffer.percent
- mapred.job.reduce.input.buffer.percent
# Reduce优化
须要reduce操作的查询
聚合函数sum,count,distinct
高级查询group by,join,distribute by,cluster by…
order by比較特殊,仅仅须要一个reduce,设置reduce个数无效。
判断运行
设置mapred.reduce.tasks.speculative.execution或者hive.mapred.reduce.tasks.speculative.execution效果都一样。
设置Reduce
set mapred.reduce.tasks=10; 直接设置
hive.exec.reducers.max 默认:999
hive.exec.reducers.bytes.per.reducer 默认:1G
计算公式
maxReducers=`hive.exec.reducers.max
perReducer=`hive.exec.reducers.bytes.per.reducer
numRTasks=`min[maxReducers,input.size/perReducer]
# 参考文章
- https://www.cnblogs.com/claireyuancy/p/7224529.html










