TIP
本文主要是介绍 ClickHouse-基础总结 。
ClickHouse-基础总结
# 1. 需求背景
# 1.1. 概述
随着数据科技的进步,数据分析师早已不再满足于传统的T+1式报表或需要提前设置好维度与指标的OLAP查询。数据分析师更希望使用可以支持任意指标、任意维度并秒级给出反馈的大数据Ad-hoc查询系统。这对大数据技术来说是一项非常大的挑战,传统的大数据查询引擎根本无法做到这一点。由俄罗斯的Yandex公司开源的ClickHouse脱颖而出。在第一届易观OLAP大赛中,在用户行为分析转化漏斗场景里,ClickHouse比Spark快了近10倍。在随后几年的大赛中,面对各类新的大数据引擎的挑战,ClickHouse一直稳稳地坐在冠军宝座上。同时在各种OLAP查询引擎评测中,ClickHouse单表查询的速度力压现在流行的各大数据库引擎,尤其是Ad-hoc查询速度一直遥遥领先,因此被国内大量用户和爱好者广泛用在即席查询场景当中。
ClickHouse的性能测试:https://clickhouse.tech/benchmark/dbms/
# 1.2. 用户轨迹行为分析
架构目标:
- 海量数据
- 实时导入
- 实时查询
- 多维聚合分析
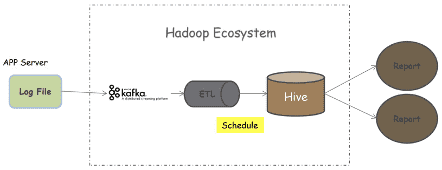
# 1.3. 架构分析
- 数据的实效性:中间过程经过Kafka、ETL、调度处理,报表的实效性不理想
- 即席分析性能:Hive存储是hdfs文件系统,查询效率不高,不适合即席查询
- 涉及Hadoop组件多:涉及Flume、Kafka、HDFS等等,数据冗余过多,同时需要深厚的知识储备
- 数据链路长:数据链路处理流程长,繁琐容错也不好
# 1.4. 美好愿望

# 2. OLAP详解
OLTP + OLAP: T:transaction 事务处理 侧重于增删改 A:analysis 分析 Select大批量数据的聚合查询事务处理作用:保证数据的一致性,如果涉及到事务操作,这个操作的执行效率必然不高
OLAP + OLTP =====> 同时满足,很难涉及
- MySQL: insert update delete Hive
- ClickHouse: Select 查询分析的高效
读模式 + 写模式 OLAP一般都是读模式, OLTP 写模式 ClickHouse一出来,界限模糊了。 ClickHouse 写模式+ OLAP
海量数据做查询分析高效: 列式数据库, 写模式(保证同一列的数据类型是一样的: 方便压缩),排序
OLAP体系的重要三个特点: 排序 + 写模式 + 列式数据库
ClickHouse 全部都具备!
# 2.1. OLAP的场景特征
读多于写
不同于事务处理(OLTP)的场景,比如电商场景中加购物车、下单、支付等需要在原地进行大量insert、update、delete操作,数据分析(OLAP)场景通常是将数据批量导入后,进行任意维度的灵活探索、BI工具洞察、报表制作等。
数据一次性写入后,分析师需要尝试从各个角度对数据做挖掘、分析,直到发现其中的商业价值、业务变化趋势等信息。这是一个需要反复试错、不断调整、持续优化的过程,其中数据的读取次数远多于写入次数。这就要求底层数据库为这个 特点做专门设计,而不是盲目采用传统数据库的技术架构。
2.大宽表,读大量行但是少量列,结果集较小
在OLAP场景中,通常存在一张或是几张多列的大宽表,列数高达数百甚至数千列。对数据分析处理时,选择其中的少数几列作为维度列、其他少数几列作为指标列,然后对全表或某一个较大范围内的数据做聚合计算。这个过程会扫描大量的行数据,但是只用到了其中的少数列。而聚合计算的结果集相比于动辄数十亿的原始数据,也明显小得多。
例如:查询公司每个部门人有多少。
select department, count(id) as total from compant group by department;
3.数据批量写入,且数据不更新或少更新
OLTP类业务对于延时(Latency)要求更高,要避免让客户等待造成业务损失;而OLAP类业务,由于数据量非常大,通常更加关注写入吞吐(Throughput),要求海量数据能够尽快导入完成。一旦导入完成,历史数据往往作为存档,不会再做更新、删除操作
4.无需事务,数据一致性要求低
OLAP类业务对于事务需求较少,通常是导入历史日志数据,或搭配一款事务型数据库并实时从事务型数据库中进行数据同步。多数OLAP系统都支持最终一致性。
5.灵活多变,不适合预先建模
分析场景下,随着业务变化要及时调整分析维度、挖掘方法,以尽快发现数据价值、更新业务指标。而数据仓库中通常存储着海量的历史数据,调整代价十分高昂。预先建模技术虽然可以在特定场景中加速计算,但是无法满足业务灵活多变的发展需求,维护成本过高。
# 2.2. ClickHouse官网解释
https://clickhouse.tech/docs/zh/#olapchan (opens new window)
- 绝大多数请求都是读请求
- 数据以相当大的批次(>1000行)更新,而不是单行更新;或者它根本没有更新
- 数据已添加到数据库,但不会进行修改
- 对于读取,每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 表格“宽”,意味着它们包含大量列
- 查询相对较少(通常每台服务器数百个查询或每秒更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:一般来说,都是数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒最多数十亿行)
- Transactions不是必需的
- 对数据一致性要求低
- 每个查询有一个大表。所有其他表都很小,除了这个大表
- 查询结果明显小于源数据。换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
很容易看出OLAP 场景与其他流行场景(例如OLTP或键值访问)非常不同。 因此,如果希望获得不错的性能,尝试使用 OLTP 或 键值DB 来处理分析查询是没有意义的。 例如,如果尝试使用 MongoDB 或 Redis 进行分析,则与OLAP数据库相比,性能会非常差。

# 列式数据库
# 1.列式数据库
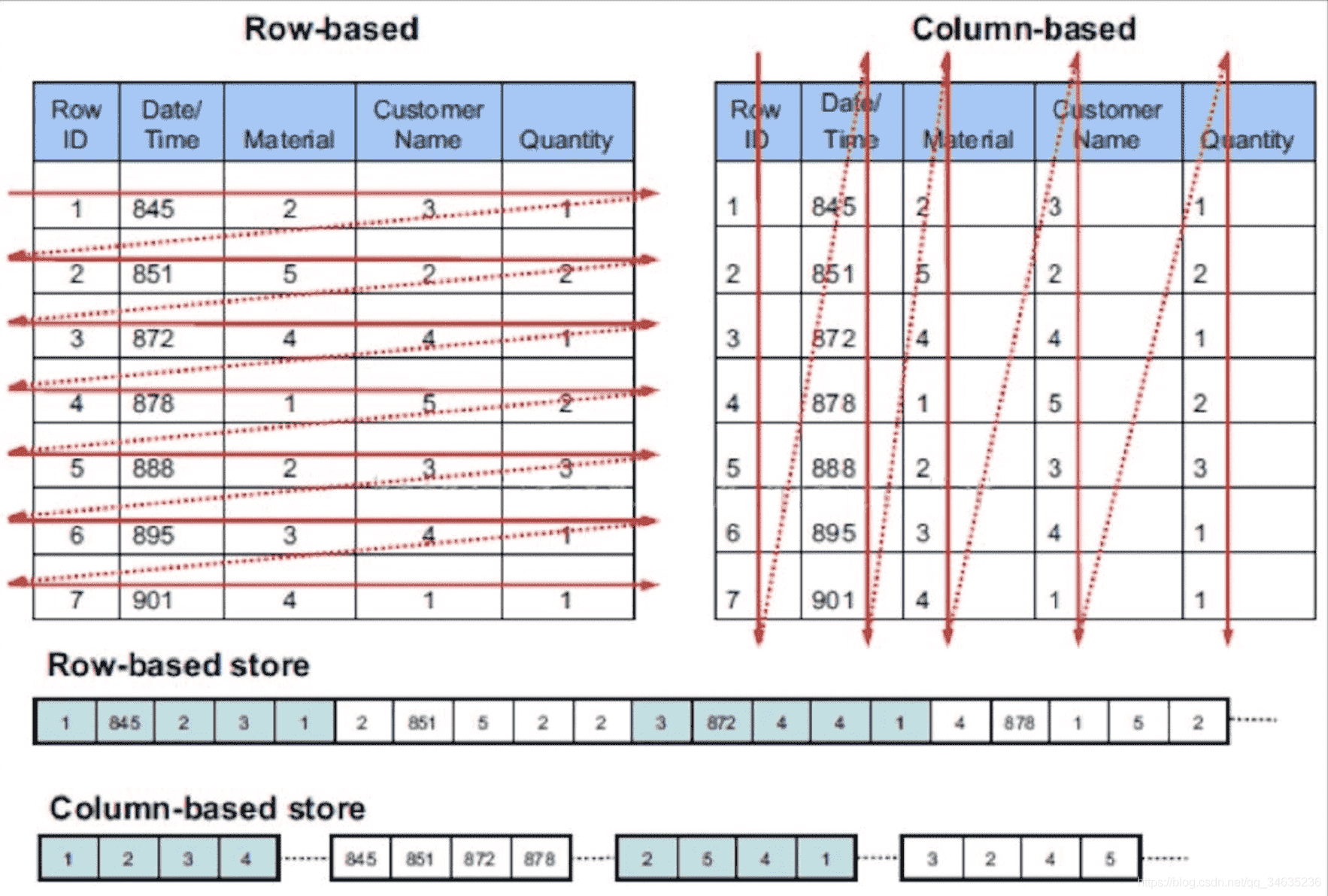
# 1.2列式存储的特点
ClickHouse官网阐述:https://clickhouse.tech/docs/zh/#inputoutput (opens new window)相比于行式存储,列式存储在分析场景下有着许多优良的特性。
行式:

列式:

看到差别了么?下面将详细介绍为什么会发生这种情况。
# 输入/输出
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
例如,查询?统计每个广告平台的记录数量?需要读取?广告平台ID?这一列,它在未压缩的情况下需要1个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
# CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止CPU进行等待。所以,在数据按列存储并且按列执行是很有意义的。
有两种方法可以做到这一点:
- 向量引擎:所有的操作都是为向量而不是为单个值编写的。这意味着多个操作之间的不再需要频繁的调用,并且调用的成本基本可以忽略不计。操作代码包含一个优化的内部循环。
- 代码生成:生成一段代码,包含查询中的所有操作。
这是不应该在一个通用数据库中实现的,因为这在运行简单查询时是没有意义的。但是也有例外,例如,MemSQL使用代码生成来减少处理SQL查询的延迟(只是为了比较,分析型数据库通常需要优化的是吞吐而不是延迟)。
# ClickHouse基础
# ClickHouse概述
ClickHouse 是俄罗斯搜索巨头 Yandex 公司早 2016年 开源的一个极具 " 战斗力 " 的实时数据分析数据库,是一个用于联机分析 (OLAP:Online Analytical Processing) 的列式数据库管理系统(DBMS:Database Management System),简称 CK,工作速度比传统方法快100-1000倍,ClickHouse 的性能超过了目前市场上可比的面向列的DBMS。 每秒钟每台服务器每秒处理数亿至十亿多行和数十千兆字节的数据。它允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器,支持线性扩展,简单方便,高可靠性,容错。
ClickHouse 作为一个高性能 OLAP 数据库,虽然OLAP能力逆天但也不应该把它用于任何OLTP事务性操作的场景,相比OLTP:不支持事务、不擅长根据主键按行粒度的查询、不擅长按行删除数据,目前市场上的其他同类高性能 OLAP 数据库同样也不擅长这些方面。因为对于一款OLAP数据库而言,OLTP 能力并不是重点。
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。这些功能共同为ClickHouse极速的分析性能奠定了基础。
ClickHouse适合流式或批次入库的时序数据。ClickHouse不应该被用作通用数据库,而是作为超高性能的海量数据快速查询的分布式实时处理平台,在数据汇总查询方面(如GROUP BY),ClickHouse的查询速度非常快。
典型特点总结:ROLAP**、在线实时查询、完整的DBMS、列式存储、不需要任何数据预处理、支持批量更新、具有非常完善的SQL支持和函数、支持高可用、不依赖Hadoop复杂生态、开箱即用**简单的说,ClickHouse作为分析型数据库,有三大特点:一是跑分快, 二是功能多 ,三是文艺范
# ClickHouse使用场景
适用场景
- web和app数据分析
- 广告网络和RTB
- 电信
- 电子商务和金融
- 信息安全
- 监测
- 时序数据
- 商业智能
- 在线游戏
- 物联网
不适用场景
- 事务性工作(OLTP)
- 高并发的键值访问
- 文档存储
- 超标准化的数据
# ClickHouse的优点
- 真正的面向列的DBMS(ClickHouse是一个DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置和重新启动服务器)
- 数据压缩(一些面向列的DBMS(INFINIDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实是提高了性能)
- 磁盘存储的数据(许多面向列的DBMS(SPA HANA和GooglePowerDrill))只能在内存中工作。但即使在数千台服务器上,内存也太小了。)
- 多核并行处理(多核多节点并行化大型查询)
- 在多个服务器上分布式处理(在clickhouse中,数据可以驻留在不同的分片上。每个分片都可以用于容错的一组副本,查询会在所有分片上并行处理)
- SQL支持(ClickHouse sql 跟真正的sql有不一样的函数名称。不过语法基本跟SQL语法兼容,支持JOIN/FROM/IN 和JOIN子句及标量子查询支持子查询)
- 向量化引擎(数据不仅按列式存储,而且由矢量-列的部分进行处理,这使得开发者能够实现高CPU性能)
- 实时数据更新(ClickHouse支持主键表。为了快速执行对主键范围的查询,数据使用合并树(MergeTree)进行递增排序。由于这个原因,数据可以不断地添加到表中)
- 支持近似计算(统计全国到底有多少人?143456754 14.3E)
- 数据复制和对数据完整性的支持(ClickHouse使用异步多主复制。写入任何可用的复本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据。数据在失败后自动恢复)
# ClickHouse的缺点
ClickHouse 作为一个被设计用来在实时分析的 OLAP 组件,只是在高效率的分析方面性能发挥到极致,那必然就会在其他方面做出取舍:
- 没有完整的事务支持,不支持Transaction想快就别Transaction
- 缺少完整Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力,仅用于批量删除或修改数据。
- 聚合结果必须小于一台机器的内存大小
- 支持有限操作系统,正在慢慢完善
- 开源社区刚刚启动,主要是俄语为主,中文社区:http://www.clickhouse.com.cn
- 不适合Key-value存储,不支持Blob等文档型数据库
# 参考文章
- https://blog.csdn.net/qq_34635236/article/details/111059870










