TIP
本文主要是介绍 Ambari-集群安装攻略 。
- Ambari HDP集群搭建全攻略
- 集群搭建
- 1、让我们先做一些安装前的准备工作
- 2、然后在做一些Ubuntu系统的优化
- 3、安装部署ambari-server (环境:Ubuntu 14.04 + Ambari 2.2.1)
- 4、修改ambari-agent配置指向ambari-server
- 5、经过头痛的Shell命令,开始连点人间的东西了。
- 6、给集群起一个名字
- 7、这个里要注意一点确定你的hdp版本不然后面会有麻烦
- 8、我在这里面配置的是HDP2.4.3
- 9、填入hostname master slave1 slave2 因为在slave安装ambari-agent 所以直接选择不使用ssh
- 10、检查服务器状态--这里需要等待一下 如果等待时间过长可以重启ambari-server
- 11、选择我们需要的服务 HDFS YARN ZK
- 12、直接使用Ambari默认分配方式 点击下一步开始安装
- 13、下面就是考虑网速的时候了
- 14、安装完成之后一路Next刷新主页面就看到了我们的Hadoop集群这里默认都是启动的
- 15、进入HDFS下 点击restart ALL 可以重启所有组件
- 16、验证一下是否安装成功 点击NameNodeUI
- 17、基础信息页
- 18、Hadoop已经搭建完成完成了不想跑一个任务试试吗?
- 19、结果如下 生成_SUCCESS 和文件
- 下面是不正经叙述
- 参考文章
# Ambari HDP集群搭建全攻略
世界上最快的捷径,就是脚踏实地,本文已收录【架构技术专栏 (opens new window)】关注这个喜欢分享的地方。
最近因为工作上需要重新用Ambari搭了一套Hadoop集群,就把搭建的过程记录了下来,也希望给有同样需求的小伙伴们一个参考,
作者:图头数据
Ambari Ubuntu14.04 最新版本 2.2.1
HDP Ubuntu14.04 最新版本 2.4.3.0
# Ambari是什么
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。
Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等。
Apache Ambari 支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeepr、Sqoop和Hcatalog等的集中管理。也是5个顶级hadoop管理工具之一。(就是一个开源的hadoop一键式安装服务)
# 我们能用他干什么?我们为什么要用它呢?
我们可以使用ambari快速的搭建和管理hadoop和经常使用的服务组件。
比如hdfs、yarn、hive、hbase、oozie、sqoop、flume、zookeeper、kafka等等。(说白了就是可以偷好多懒)
再说说我们为什么要用它
- 第一是ambari还算是一个早期的Hadoop管理集群工具
- 第二主要是现在Hadoop官网也在推荐使用Ambari。
- 通过一步一步的安装向导简化了集群供应。
- 预先配置好关键的运维指标(metrics),可以直接查看Hadoop Core(HDFS和MapReduce)及相关项目(如HBase、Hive和HCatalog)是否健康。
- 支持作业与任务执行的可视化与分析,能够更好地查看依赖和性能。
- 通过一个完整的RESTful API把监控信息暴露出来,集成了现有的运维工具。
- 用户界面非常直观,用户可以轻松有效地查看信息并控制集群。
Ambari使用Ganglia (opens new window)收集度量指标,用Nagios (opens new window)支持系统报警,当需要引起管理员的关注时(比如,节点停机或磁盘剩余空间不足等问题),系统将向其发送邮件。
此外,Ambari能够安装安全的(基于Kerberos)Hadoop集群,以此实现了对Hadoop 安全的支持,提供了基于角色的用户认证、授权和审计功能,并为用户管理集成了LDAP和Active Directory。
# 集群搭建
# 1、让我们先做一些安装前的准备工作
### 先告诉服务器们他们都是谁,小名都叫啥(修改配置hosts文件)
vim /etc/hosts
10.1.10.1 master
10.1.10.2 slave1
10.1.10.3 slave2
### 然后让我们拿着门禁卡自由的出入他们家 哔咔进站(配置免密登录)
ssh-keygen -t rsa ##在所有的机器上执行
cat ~/.ssh/id_rsa.pub ### 查看公钥
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ### 将公钥写入authorized_keys文件中
#### 首先把所有的公钥都写入master服务器
#### 其次把master的公钥别写入slave1,slave2
#### 最后使用scp命令把口令告诉别人 (我不会告诉你我的口令是“老狼老狼几点了”)
scp ~/.ssh/authorized_keys slave1:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys slave2:~/.ssh/authorized_keys
##更新时区和系统本地化的配置
apt-get install localepurge ### 一顿enter不要管 (卸载那些不被使用的local翻译文档)
dpkg-reconfigure localepurge && locale-gen zh_CN.UTF-8 en_US.UTF-8 ### 一顿enter不要管
apt-get update && apt-get install -y tzdata
echo "Asia/Shanghai" > /etc/timezone ### 修改时区为上海
rm /etc/localtime
dpkg-reconfigure -f noninteractive tzdata
vi /etc/ntp.conf
server 10.1.10.1
# 2、然后在做一些Ubuntu系统的优化
###1.1 关闭交换分区
swapoff -a
vim /etc/fstab ### 删除注释swap那一行 类似下面
## swap was on /dev/sda2 during installation
#UUID=8aba5009-d557-4a4a-8fd6-8e6e8c687714 none swap sw 0 0
#### 1.2 修改文件描述符打开数 在最后添加 ulimit
vi /etc/profile
ulimit -SHn 512000
vim /etc/security/limits.conf ### 调整大小都增大10倍
* soft nofile 600000
* hard nofile 655350
* soft nproc 600000
* hard nproc 655350
#### 1.2 使用命令是修改生效
source /etc/profile
###1.3 修改内核配置
vi /etc/sysctl.conf
#### 贴上去就行
fs.file-max = 65535000
net.core.somaxconn = 30000
vm.swappiness = 0
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 16384
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.ip_local_port_range = 1024 65000
net.ipv6.conf.all.disable_ipv6=1
net.ipv6.conf.default.disable_ipv6=1
net.ipv6.conf.lo.disable_ipv6=1
#### 执行命令让配置生效
sysctl -p
###1.4 配置内核关闭THP功能
echo never > /sys/kernel/mm/transparent_hugepage/enabled
##永久关闭。
vi /etc/rc.local
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
# 3、安装部署ambari-server (环境:Ubuntu 14.04 + Ambari 2.2.1)
### 更新下载源
wget -O /etc/apt/sources.list.d/ambari.list http://public-repo-1.hortonworks.com/ambari/ubuntu14/2.x/updates/2.2.1.0/ambari.list
apt-key adv --recv-keys --keyserver keyserver.ubuntu.com B9733A7A07513CAD
apt-get update
### 在master节点安装ambari-server
apt-get install ambari-server -y
### 在所有节点安装 ambari-agent
apt-get install ambari-agent -y
# 4、修改ambari-agent配置指向ambari-server
vi /etc/ambari-agent/conf/ambari-agent.ini
### 修改hostname
[server]
hostname=master
url_port=8440
secured_url_port=8441
### 初始化ambari-server配置ambari 服务 Database, JDK(默认1.7), LDAP 一般选默认
ambari-server setup ### 狂点enter
### 启动ambari
ambari-server start
ambari-agent start
# 5、经过头痛的Shell命令,开始连点人间的东西了。
使用你的浏览器访问 http://10.1.10.1:8080/ 账号密码默认为amdin/admin点击LAUNCH INSTALL WIZARD让我们愉快的开始吧
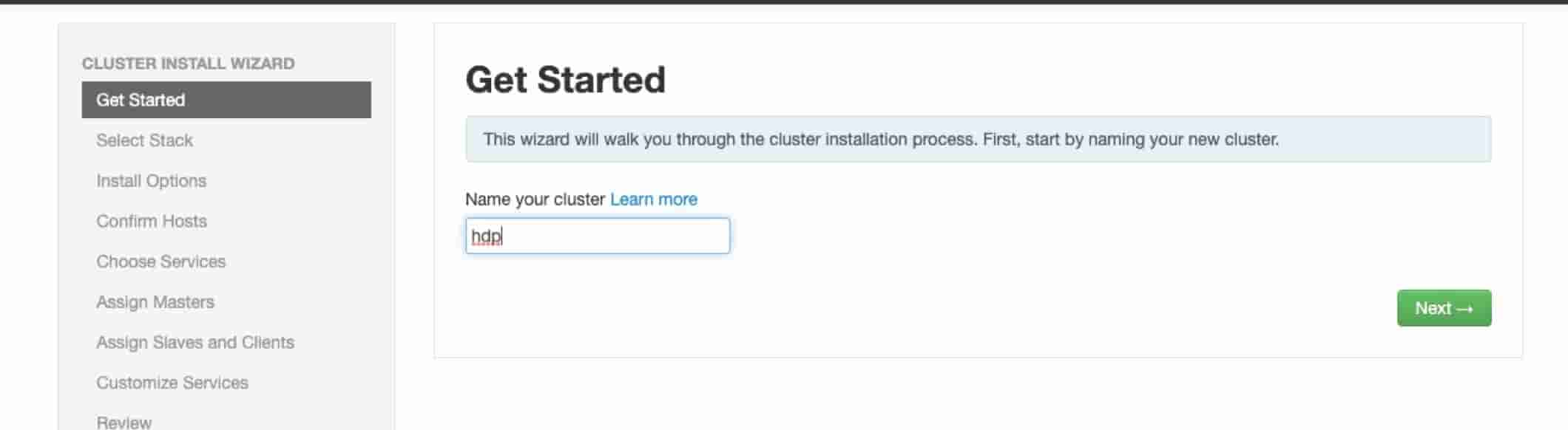
# 6、给集群起一个名字
# 7、这个里要注意一点确定你的hdp版本不然后面会有麻烦
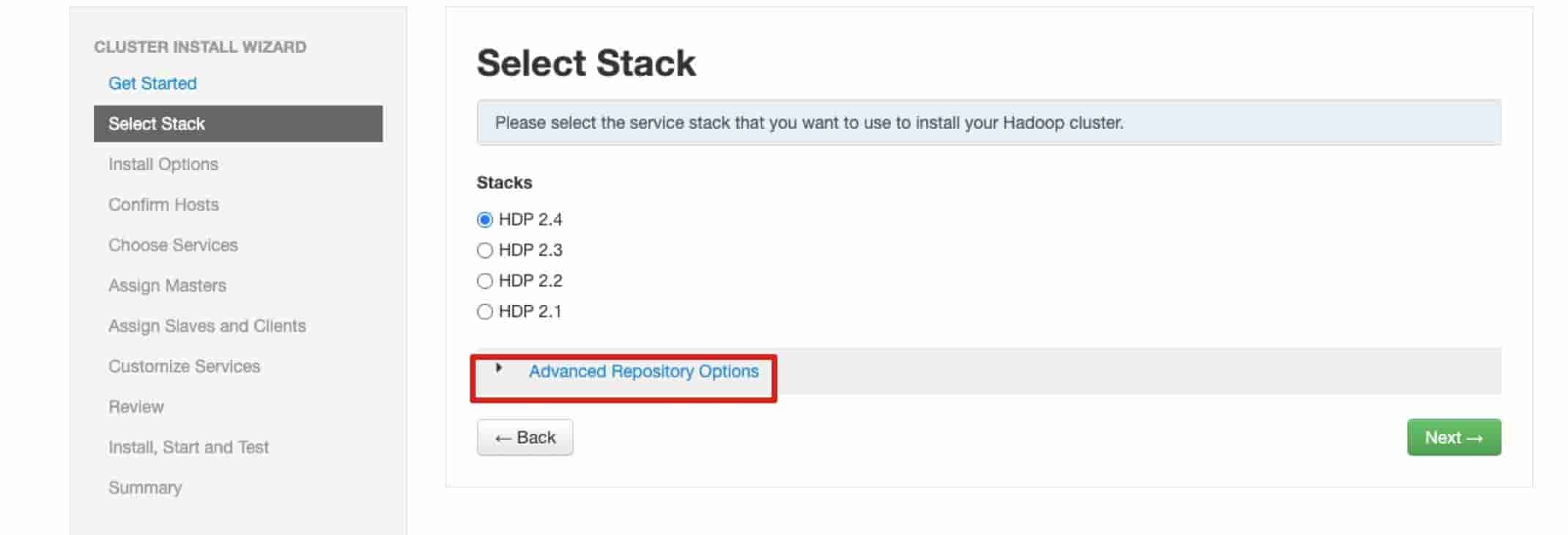
# 8、我在这里面配置的是HDP2.4.3
例子: http://public-repo-1.hortonworks.com/HDP/debian7/2.x/updates/2.4.3.0
点击next 会检查数据源是否正常,如果这里报错可以点击 "Skip Repository Base URL validation (Advanced) " 进行跳过检查

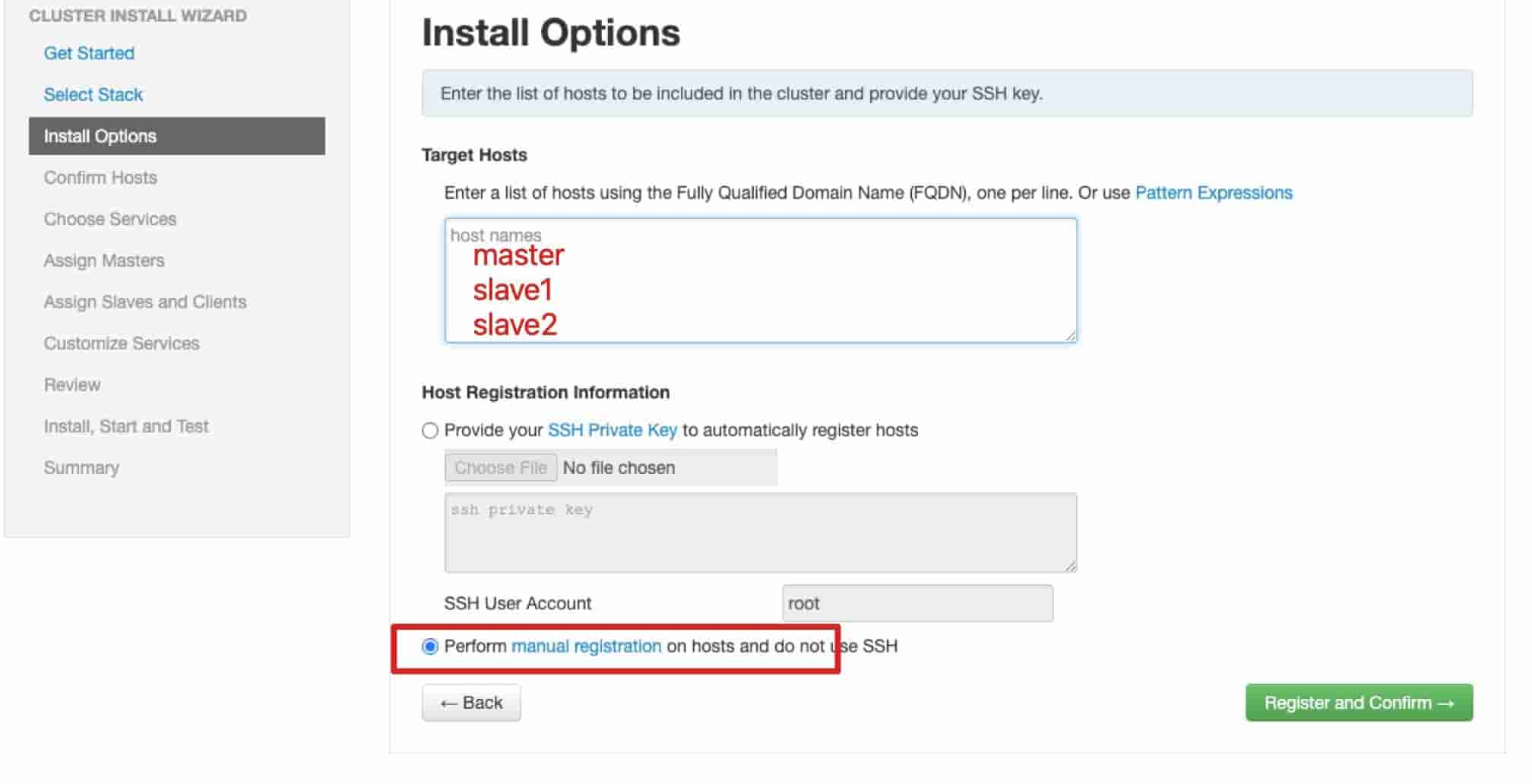
# 9、填入hostname master slave1 slave2 因为在slave安装ambari-agent 所以直接选择不使用ssh
# 10、检查服务器状态--这里需要等待一下 如果等待时间过长可以重启ambari-server

# 11、选择我们需要的服务 HDFS YARN ZK
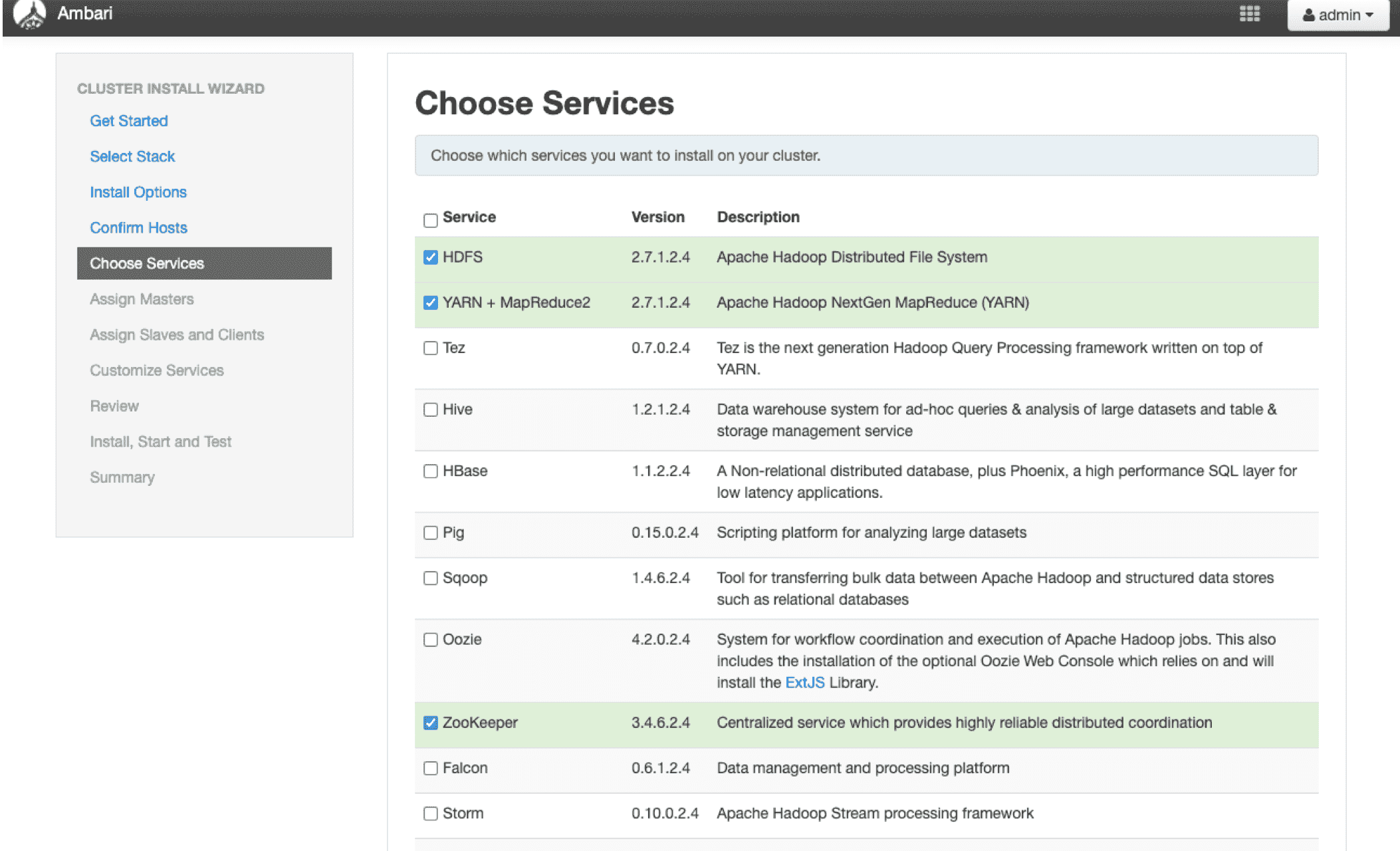
# 12、直接使用Ambari默认分配方式 点击下一步开始安装
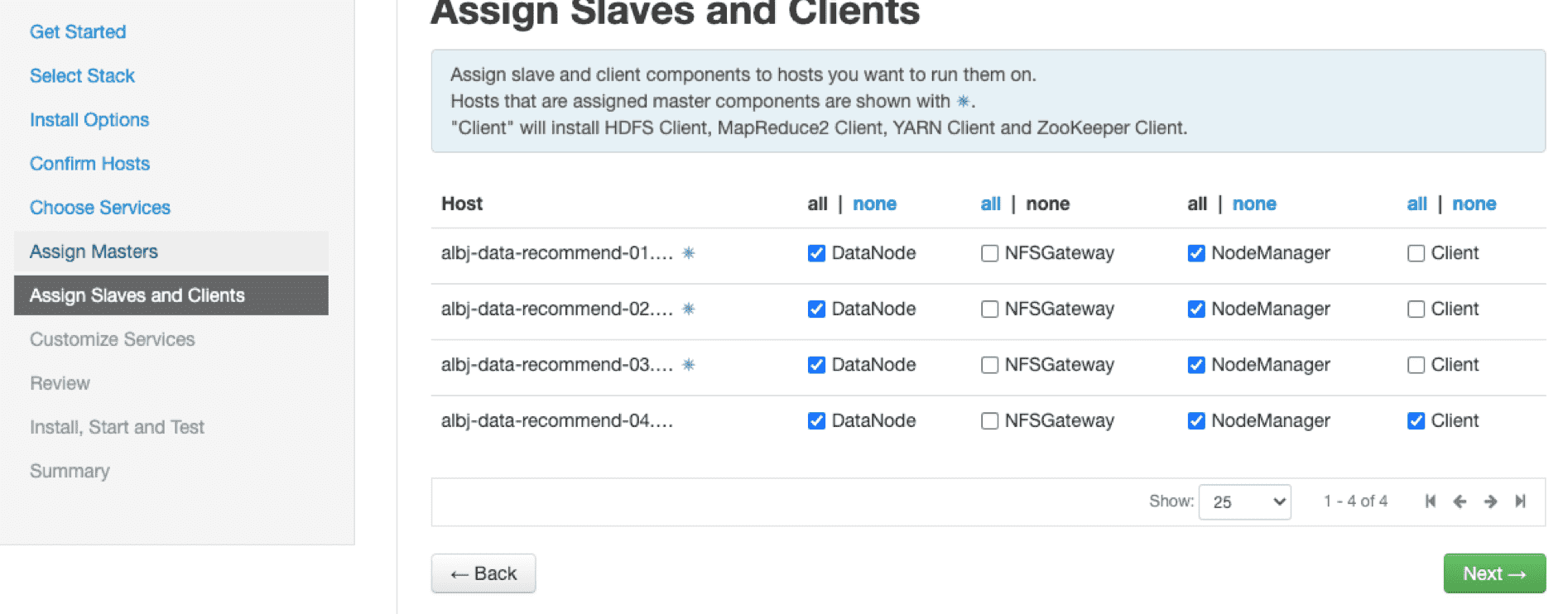
# 13、下面就是考虑网速的时候了
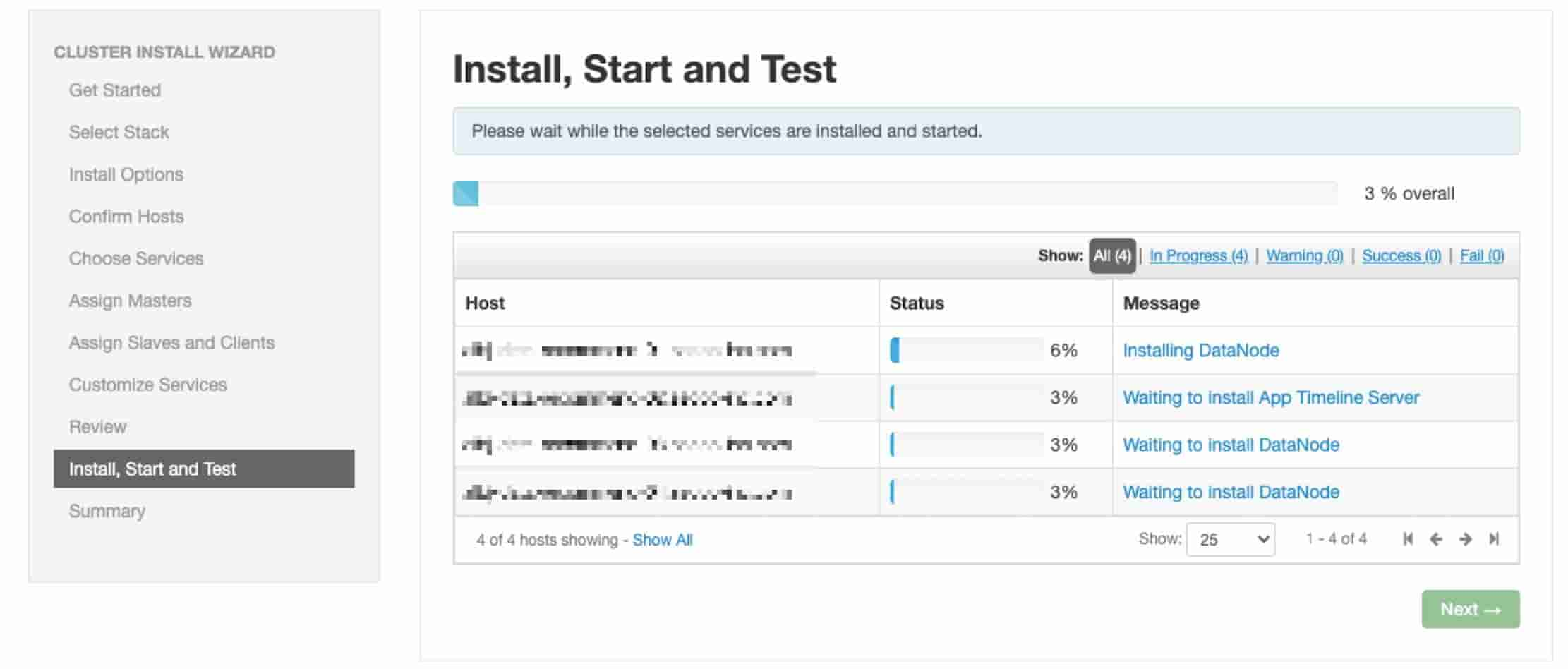
# 14、安装完成之后一路Next刷新主页面就看到了我们的Hadoop集群这里默认都是启动的
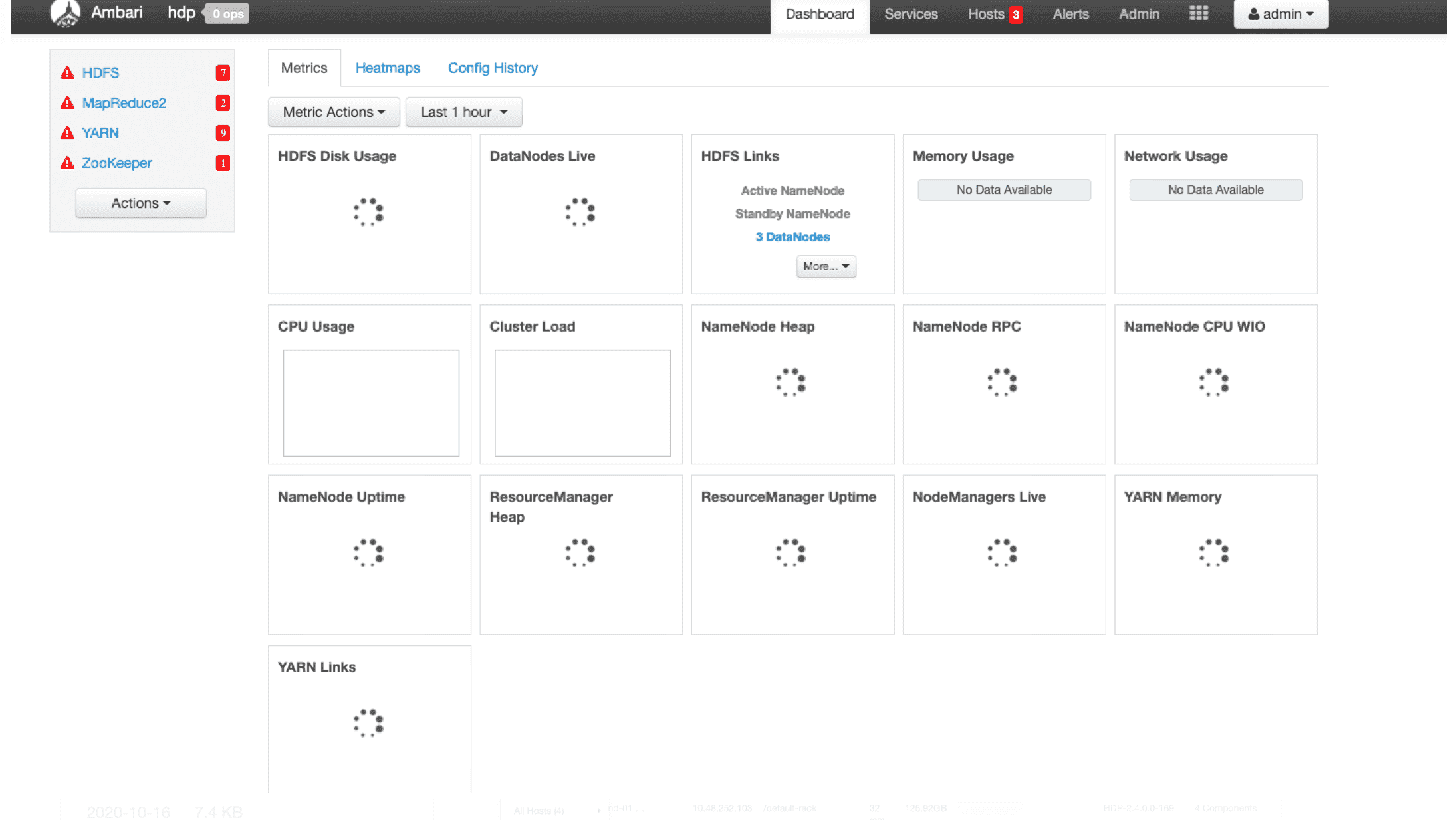
# 15、进入HDFS下 点击restart ALL 可以重启所有组件

# 16、验证一下是否安装成功 点击NameNodeUI
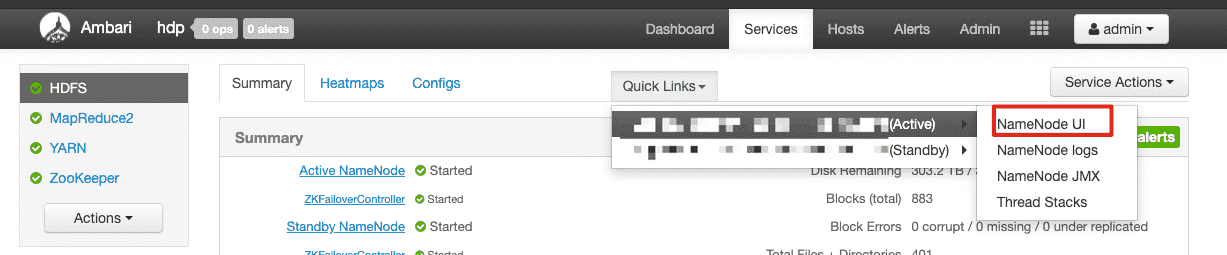
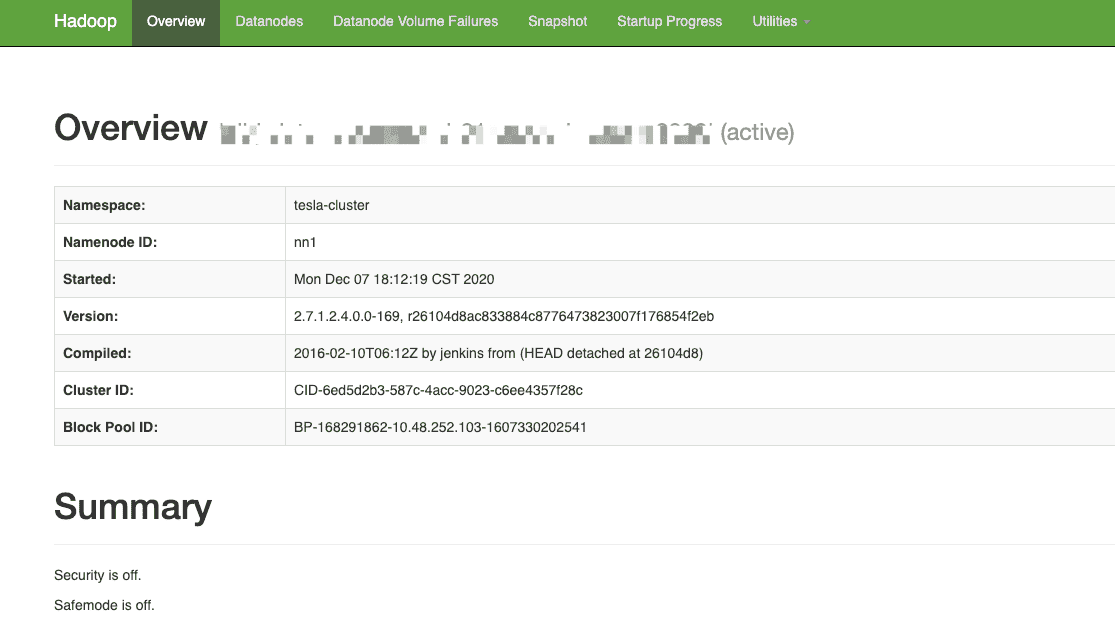
# 17、基础信息页

# 18、Hadoop已经搭建完成完成了不想跑一个任务试试吗?
### 进入服务器执行
#### 创建hdfs目录 可以再http://master:50070/explorer.html#/界面
hdfs dfs -mkdir -p /data/input
#### 从服务器上传文件到hdfs上
hdfs dfs -put 文件 /data/input/
#### 使用官网提供的例子进行测试
hadoop jar hdfs://tesla-cluster/data/hadoop-mapreduce-examples-2.7.1.2.4.0.0-169.jar wordcount /data/input /data/output1

# 19、结果如下 生成_SUCCESS 和文件

# 下面是不正经叙述
终于,通过上面的步骤我们搭建了一套hadoop集群,但随之而来的还有一些问题,NameNode 和ResouceManage 都是单点的模式,ambari支持HA(高可用) 因为篇幅有限,图头后面会单开一张来讲。
# 参考文章
- https://www.cnblogs.com/jiagoujishu/p/14101235.html










