TIP
本文主要是介绍 HBASE-配置优化 。
# HBase 优化
# JVM调优
# 内存调优
一般安装好的HBase集群,默认配置是给Master和RegionServer 1G的内存,而Memstore默认占0.4,也就是400MB。显然RegionServer给的1G真的太少了。
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xms2g -Xmx2g"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xms8g -Xmx8g"
这里只是举例,并不是所有的集群都是这么配置。 ==要牢记至少留10%的内存给操作系统来进行必要的操作==
如何给出一个合理的JVM 内存大小设置,举一个ambari官方提供的例子吧。
比如你现在有一台16GB的机器,上面有MapReduce服务、 RegionServer和DataNode(这三位一般都是装在一起的),那么建议按 照如下配置设置内存:
- 2GB:留给系统进程。
- 8GB:MapReduce服务。平均每1GB分配6个Map slots + 2个Reduce slots。
- 4GB:HBase的RegionServer服务
- 1GB:TaskTracker
- 1GB:DataNode
如果同时运行MapReduce的话,RegionServer将是除了MapReduce以外使用内存最大的服务。如果没有MapReduce的话,RegionServer可以调整到大概一半的服务器内存。
# Full GC调优
由于数据都是在RegionServer里面的,Master只是做一些管理操作,所以一般内存问题都出在RegionServer上。
JVM提供了4种GC回收器:
- 串行回收器(SerialGC)。
- 并行回收器(ParallelGC),主要针对年轻带进行优化(JDK 8 默认策略)。
- 并发回收器(ConcMarkSweepGC,简称CMS),主要针对年老带进 行优化。
- G1GC回收器,主要针对大内存(32GB以上才叫大内存)进行优化。
一般会采取两种组合方案
ParallelGC和CMS的组合方案
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xms8g -Xmx8g -XX:+UseParNewGC -XX:+UseConMarkSweepGC"G1GC方案
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=100"
怎么选择呢?
一般内存很大(32~64G)的时候,才会去考虑用G1GC方案。
如果你的内存小于4G,乖乖选择第一种方案吧。
如果你的内存(4~32G)之间,你需要自行测试下两种方案,孰强孰弱靠实践。测试的时候记得加上命令
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy
# MSLAB和In Memory Compaction(HBase2.X才有)
HBase自己实现了一套以Memstore为最小单元的内存管理机制,称为 MSLAB(Memstore-Local Allocation Buffers)
跟MSLAB相关的参数是:
- hbase.hregion.memstore.mslab.enabled:设置为true,即打开 MSLAB,默认为true。
- hbase.hregion.memstore.mslab.chunksize:每个chunk的大 小,默认为2048 * 1024 即2MB。
- hbase.hregion.memstore.mslab.max.allocation:能放入chunk 的最大单元格大小,默认为256KB,已经很大了。
- hbase.hregion.memstore.chunkpool.maxsize:在整个memstore 可以占用的堆内存中,chunkPool占用的比例。该值为一个百分 比,取值范围为0.0~1.0。默认值为0.0。 hbase.hregion.memstore.chunkpool.initialsize:在 RegionServer启动的时候可以预分配一些空的chunk出来放到 chunkPool里面待使用。该值就代表了预分配的chunk占总的 chunkPool的比例。该值为一个百分比,取值范围为0.0~1.0,默认值为0.0。
在HBase2.0版本中,为了实现更高的写入吞吐和更低的延迟,社区团队对MemStore做了更细粒度的设计。这里,主要指的就是In Memory Compaction。
开启的条件也很简单。
hbase.hregion.compacting.memstore.type=BASIC # 可选择NONE/BASIC/EAGER
具体这里不介绍了。
# Region自动拆分
Region的拆分分为自动拆分和手动拆分。自动拆分可以采用不同的策略。
# 拆分策略
# ConstantSizeRegionSplitPolicy
0.94版本的策略方案
hbase.hregion.max.filesize
通过该参数设定单个Region的大小,超过这个阈值就会拆分为两个。
# IncreasingToUpperBoundRegionSplitPolicy(默认)
文件尺寸限制是动态的,依赖以下公式来计算
Math.min(tableRegionCount^3 * initialSize, defaultRegionMaxFileSize)
- tableRegionCount:表在所有RegionServer上所拥有的Region数量总和。
- initialSize:如果你定义了 hbase.increasing.policy.initial.size,则使用这个数值;如果没有定义,就用memstore的刷写大小的2倍,即 hbase.hregion.memstore.flush.size * 2。
- defaultRegionMaxFileSize:ConstantSizeRegionSplitPolicy 所用到的hbase.hregion.max.filesize,即Region最大大小。
假如hbase.hregion.memstore.flush.size定义为128MB,那么文件 尺寸的上限增长将是这样:
- 刚开始只有一个文件的时候,上限是256MB,因为1^3 1282 = 256MB。
- 当有2个文件的时候,上限是2GB,因为2^3 128 2 2048MB。
- 当有3个文件的时候,上限是6.75GB,因为3^3 128 2 = 6912MB。
- 以此类推,直到计算出来的上限达到 hbase.hregion.max.filesize所定义的10GB。
# KeyPrefixRegionSplitPolicy
除了简单粗暴地根据大小来拆分,我们还可以自己定义拆分点。 KeyPrefixRegionSplitPolicy 是 IncreasingToUpperBoundRegionSplitPolicy的子类,在前者的基础上增加了对拆分点(splitPoint,拆分点就是Region被拆分处的rowkey)的定义。它保证了有相同前缀的rowkey不会被拆分到两个不同的Region里面。这个策略用到的参数是KeyPrefixRegionSplitPolicy.prefix_length rowkey:前缀长度
那么它与IncreasingToUpperBoundRegionSplitPolicy区别,用两张图来看。
默认策略为
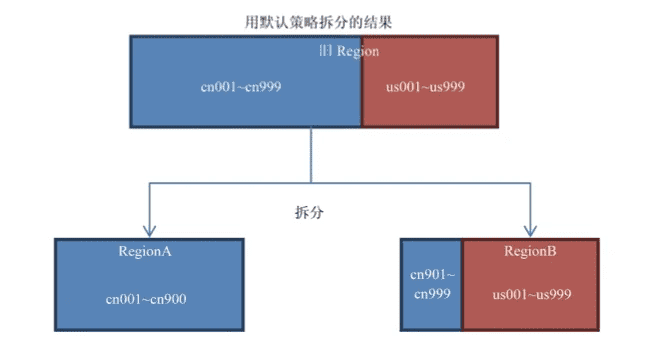
KeyPrefixRegionSplitPolicy策略
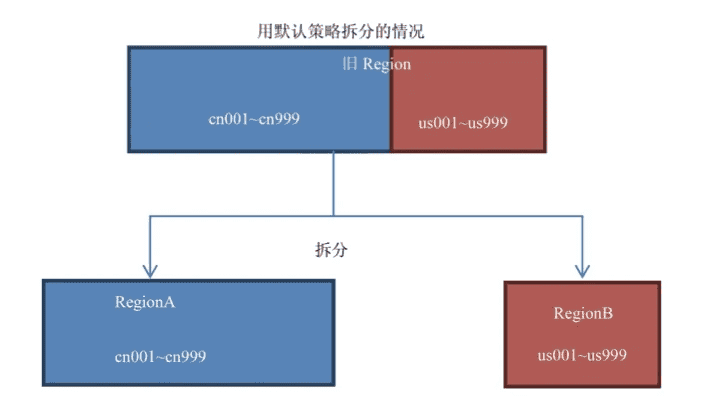
如果你的前缀划分的比较细,你的查询就比较容易发生跨Region查询的情况,此时采用KeyPrefixRegionSplitPolicy较好。
所以这个策略适用的场景是:
- 数据有多种前缀。
- 查询多是针对前缀,比较少跨越多个前缀来查询数据。
# DelimitedKeyPrefixRegionSplitPolicy
该策略也是继承自IncreasingToUpperBoundRegionSplitPolicy,它也是根据你的rowkey前缀来进行切分的。唯一的不同就是: KeyPrefixRegionSplitPolicy是根据rowkey的固定前几位字符来进行判断,而DelimitedKeyPrefixRegionSplitPolicy是根据分隔符来判断的。在有些系统中rowkey的前缀可能不一定都是定长的。
使用这个策略需要在表定义中加入以下属性:
DelimitedKeyPrefixRegionSplitPolicy.delimiter:前缀分隔符
比如你定义了前缀分隔符为_,那么host1_001和host12_999的前缀就分别是host1和host12。
# BusyRegionSplitPolicy
如果你的系统常常会出现热点Region,而你对性能有很高的追求, 那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点 Region的压力,但是根据热点来拆分Region也会带来很多不确定性因 素,因为你也不知道下一个被拆分的Region是哪个。
# DisabledRegionSplitPolicy
这种策略就是Region永不自动拆分。
如果你事先就知道这个Table应该按 怎样的策略来拆分Region的话,你也可以事先定义拆分点 (SplitPoint)。所谓拆分点就是拆分处的rowkey,比如你可以按26个 字母来定义25个拆分点,这样数据一到HBase就会被分配到各自所属的 Region里面。这时候我们就可以把自动拆分关掉,只用手动拆分。
手动拆分有两种情况:预拆分(pre-splitting)和强制拆分 (forced splits)。
# 推荐方案
一开始可以先定义拆分点,但是当数据开始工作起来后会出现热点 不均的情况,所以推荐的方法是:
- 用预拆分导入初始数据。
- 然后用自动拆分来让HBase来自动管理Region。
==建议:不要关闭自动拆分。==
Region的拆分对性能的影响还是很大的,默认的策略已经适用于大 多数情况。如果要调整,尽量不要调整到特别不适合你的策略
# BlockCache优化
一个RegionServer只有一个BlockCache。
BlockCache的工作原理:读请求到HBase之后先尝试查询BlockCache,如果获取不到就去HFile(StoreFile)和Memstore中去获取。如果获取到了则在返回数据的同时把Block块缓存到BlockCache中。它默认是开启的。
如果你想让某个列簇不使用BlockCache,可以通过以下命令关闭它。
alter 'testTable', CONFIGURATION=>{NAME => 'cf',BLOCKCACHE=>'false'}
BlockCache的实现方案有
- LRU BLOCKCACHE
- SLAB CACHE
- Bucket CACHE
# LRU BLOCKCACHE
在0.92版本 之前只有这种BlockCache的实现方案。LRU就是Least Recently Used, 即近期最少使用算法的缩写。读出来的block会被放到BlockCache中待 下次查询使用。当缓存满了的时候,会根据LRU的算法来淘汰block。 LRUBlockCache被分为三个区域,
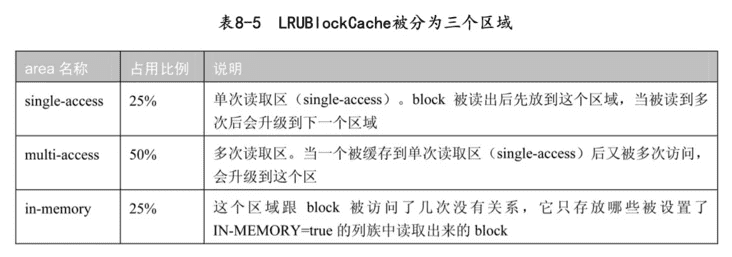
看起来是不是很像JVM的新生代、年老代、永久代?没错,这个方案就是模拟JVM的代设计而做的。
# Slab Cache
SlabCache实际测试起来对Full GC的改善很小,所以这个方案最后被废弃了。不过它被废弃还有一个更大的原因,这就是有另一个更好的Cache方案产生了,也用到了堆外内存,它就是BucketCache。
# Bucket Cache
- 相比起只有2个区域的SlabeCache,BucketCache一上来就分配了 14种区域。注意:我这里说的是14种区域,并不是14块区域。这 14种区域分别放的是大小为4KB、8KB、16KB、32KB、40KB、 48KB、56KB、64KB、96KB、128KB、192KB、256KB、384KB、 512KB的Block。而且这个种类列表还是可以手动通过设置 hbase.bucketcache.bucket.sizes属性来定义(种类之间用逗号 分隔,想配几个配几个,不一定是14个!),这14种类型可以分 配出很多个Bucket。
- BucketCache的存储不一定要使用堆外内存,是可以自由在3种存 储介质直接选择:堆(heap)、堆外(offheap)、文件 (file,这里的文件可以理解成SSD硬盘)。通过设置hbase.bucketcache.ioengine为heap、 offfheap或者file来配置。
- 每个Bucket的大小上限为最大尺寸的block 4,比如可以容纳的最大的Block类型是512KB,那么每个Bucket的大小就是512KB 4 = 2048KB。
- 系统一启动BucketCache就会把可用的存储空间按照每个Bucket 的大小上限均分为多个Bucket。如果划分完的数量比你的种类还少,比如比14(默认的种类数量)少,就会直接报错,因为每一种类型的Bucket至少要有一个Bucket。
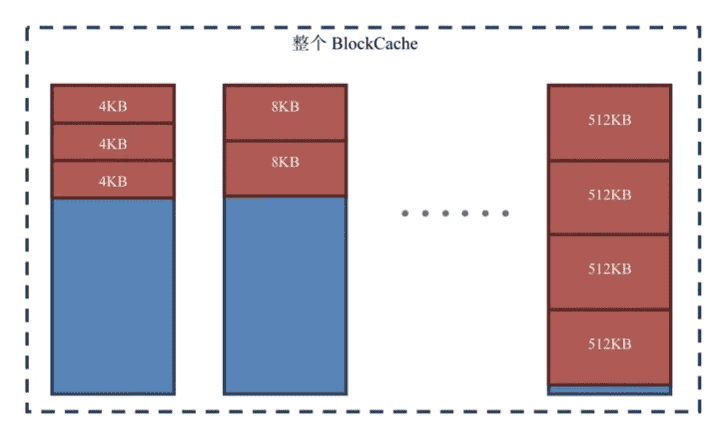
Bucket Cache默认也是开启的,如果要关闭的话
alter 'testTable', CONFIGURATION=>{CACHE_DATA_IN_L1 => 'true'}
它的配置项:
- hbase.bucketcache.ioengine:使用的存储介质,可选值为 heap、offheap、file。不设置的话,默认为offheap。
- hbase.bucketcache.combinedcache.enabled:是否打开组合模 式(CombinedBlockCache),默认为true
- hbase.bucketcache.size:BucketCache所占的大小
- hbase.bucketcache.bucket.sizes:定义所有Block种类,默认 为14种,种类之间用逗号分隔。单位为B,每一种类型必须是 1024的整数倍,否则会报异常:java.io.IOException: Invalid HFile block magic。默认值为:4、8、16、32、40、48、56、 64、96、128、192、256、384、512。
- -XX:MaxDirectMemorySize:这个参数不是在hbase-site.xml中 配置的,而是JVM启动的参数。如果你不配置这个参数,JVM会按 需索取堆外内存;如果你配置了这个参数,你可以定义JVM可以获得的堆外内存上限。显而易见的,这个参数值必须比 hbase.bucketcache.size大。
在SlabCache的时代,SlabCache,是跟LRUCache一起使用的,每一 个Block被加载出来都是缓存两份,一份在SlabCache一份在LRUCache, 这种模式称之为DoubleBlockCache。读取的时候LRUCache作为L1层缓存 (一级缓存),把SlabCache作为L2层缓存(二级缓存)。
在BucketCache的时代,也不是单纯地使用BucketCache,但是这回 不是一二级缓存的结合;而是另一种模式,叫组合模式 (CombinedBlockCahce)。具体地说就是把不同类型的Block分别放到 LRUCache和BucketCache中。
Index Block和Bloom Block会被放到LRUCache中。Data Block被直 接放到BucketCache中,所以数据会去LRUCache查询一下,然后再去 BucketCache中查询真正的数据。其实这种实现是一种更合理的二级缓 存,数据从一级缓存到二级缓存最后到硬盘,数据是从小到大,存储介质也是由快到慢。考虑到成本和性能的组合,比较合理的介质是: LRUCache使用内存->BuckectCache使用SSD->HFile使用机械硬盘。
# 总结
关于LRUBlockCache和BucketCache单独使用谁比较强,曾经有人做 过一个测试。
- 因为BucketCache自己控制内存空间,碎片比较少,所以GC时间 大部分都比LRUCache短。
- 在缓存全部命中的情况下,LRUCache的吞吐量是BucketCache的 两倍;在缓存基本命中的情况下,LRUCache的吞吐量跟 BucketCache基本相等。
- 读写延迟,IO方面两者基本相等。
- 缓存全部命中的情况下,LRUCache比使用fiile模式的 BucketCache CPU占用率低一倍,但是跟其他情况下差不多。
从整体上说LRUCache的性能好于BucketCache,但由于Full GC的存在,在某些时刻JVM会停止响应,造成服务不可用。所以适当的搭配 BucketCache可以缓解这个问题。
# HFile合并
合并分为两种操作:
- Minor Compaction:将Store中多个HFile合并为一个HFile。在 这个过程中达到TTL的数据会被移除,但是被手动删除的数据不 会被移除。这种合并触发频率较高。
- Major Compaction:合并Store中的所有HFile为一个HFile。在 这个过程中被手动删除的数据会被真正地移除。同时被删除的还 有单元格内超过MaxVersions的版本数据。这种合并触发频率较 低,默认为7天一次。不过由于Major Compaction消耗的性能较 大,你不会想让它发生在业务高峰期,建议手动控制Major Compaction的时机。
# Compaction合并策略
# RatioBasedCompactionPolicy
从旧到新地扫描HFile文件,当扫描到某个文件,该文件满足以下条件:
该文件大小 < 比它更新的所有文件的大小总和 * hbase.store.compation.ratio(默认1.2)
实际情况下的RatioBasedCompactionPolicy算法效果很差,经常引 发大面积的合并,而合并就不能写入数据,经常因为合并而影响IO。所 以HBase在0.96版本之后修改了合并算法。
# ExploringCompactionPolicy
0.96版本之后提出了ExploringCompactionPolicy算法,并且把该 算法作为了默认算法。
算法变更为
该文件大小 < (所有文件大小总和 - 该文件大小) * hbase.store.compation.ratio(默认1.2)
如果该文件大小小于最小合并大小(minCompactSize),则连上面那个公式都不需要套用,直接进入待合并列表。最小合并大小的配置项:hbase.hstore.compaction.min.size。如果没设定该配置项,则使用hbase.hregion.memstore.flush.size。
被挑选的文件必须能通过以上提到的筛选条件,并且组合内含有的文件数必须大于hbase.hstore.compaction.min,小于 hbase.hstore.compaction.max。
文件太少了没必要合并,还浪费资源;文件太多了太消耗资源,怕 机器受不了。
挑选完组合后,比较哪个文件组合包含的文件更多,就合并哪个组 合。如果出现平局,就挑选那个文件尺寸总和更小的组合。
# FIFOCompactionPolicy
这个合并算法其实是最简单的合并算法。严格地说它都不算是一种合并算法,是一种删除策略。
FIFOCompactionPolicy策略在合并时会跳过含有未过期数据的 HFile,直接删除所有单元格都过期的块。最终的效果是:
- 过期的块被整个删除掉了。
- 没过期的块完全没有操作。
这个策略不能用于什么情况
- 表没有设置TTL,或者TTL=FOREVER。
- 表设置了MIN_VERSIONS,并且MIN_VERSIONS > 0
# DateTieredCompactionPolicy
DateTieredCompactionPolicy解决的是一个基本的问题:最新的数据最 有可能被读到。
配置项
- hbase.hstore.compaction.date.tiered.base.window.millis: 基本的时间窗口时长。默认是6小时。拿默认的时间窗口举例:从现在到6小时之内的HFile都在同一个时间窗口里 面,即这些文件都在最新的时间窗口里面。
- hbase.hstore.compaction.date.tiered.windows.per.tier:层 次的增长倍数。分层的时候,越老的时间窗口越宽。在同一个窗口里面的文件如果达到最小合并数量(hbase.hstore.compaction.min)就会进行合并,但不 是简单地合并成一个,而是根据 hbase.hstore.compaction.date.tiered.window.policy.class 所定义的合并规则来合并。说白了就是,具体的合并动作 使用的是用前面提到的合并策略中的一种(我刚开始看到 这个设计的时候都震撼了,居然可以策略套策略),默认是ExploringCompactionPolicy。
- hbase.hstore.compaction.date.tiered.max.tier.age.millis: 最老的层次时间。当文件太老了,老到超过这里所定义的时间范 围(以天为单位)就直接不合并了。不过这个设定会带来一个缺 点:如果Store里的某个HFile太老了,但是又没有超过TTL,并 且大于了最老的层次时间,那么这个Store在这个HFile超时被删 除前,都不会发生Major Compaction。没有Major Compaction, 用户手动删除的数据就不会被真正删除,而是一直占着磁盘空间。
配置项好像很复杂的样子,举个例子画个图就清楚了。
假设基本窗口宽度 (hbase.hstore.compaction.date.tiered.base.window.millis) = 1。 最小合并数量(hbase.hstore.compaction.min) = 3。 层次增长倍数 (hbase.hstore.compaction.date.tiered.windows.per.tier) = 2。
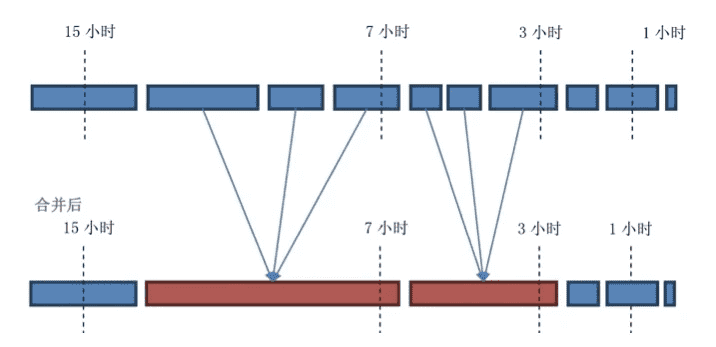
这个策略非常适用于什么场景
- 经常读写最近数据的系统,或者说这个系统专注于最新的数据。
- 因为该策略有可能引发不了Major Compaction,没有Major Compaction是没有办法删除掉用户手动删除的信息,所以更适用 于那些基本不删除数据的系统。
这个策略比较适用于什么场景
- 数据根据时间排序存储。
- 数据的修改频率很有限,或者只修改最近的数据,基本不删除数据。
这个策略不适用于什么场景
- 数据改动很频繁,并且连很老的数据也会被频繁改动。
- 经常边读边写数据。
# StripeCompactionPolicy
该策略在读取方面稳定。
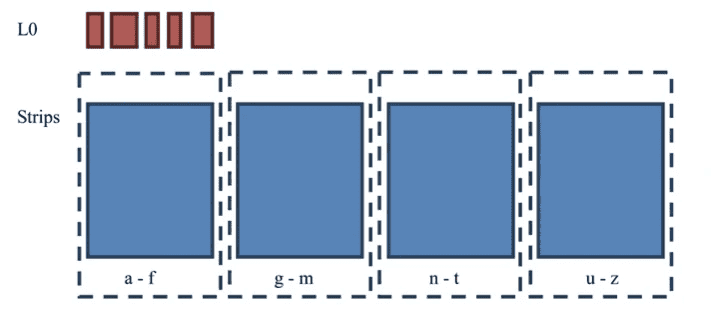
那么什么场景适合用StripeCompactionPolicy
- Region要够大:这种策略实际上就是把Region给细分成一个个 Stripe。Stripe可以看做是小Region,我们可以管它叫sub- region。所以如果Region不大,没必要用Stripe策略。小Region 用Stripe反而增加IO负担。多大才算大?作者建议如果Region大 小小于2GB,就不适合用StripeCompactionPolicy。
- Rowkey要具有统一格式,能够均匀分布。由于要划分KeyRange, 所以key的分布必须得均匀,比如用26个字母打头来命名 rowkey,就可以保证数据的均匀分布。如果使用timestamp来做 rowkey,那么数据就没法均匀分布了,肯定就不适合使用这个策略。
# 总结
请详细地看各种策略的适合场景,并根据场景选择策略。
- 如果你的数据有固定的TTL,并且越新的数据越容易被读到,那么DateTieredCompaction一般是比较适合你的。
- 如果你的数据没有TTL或者TTL较大,那么选择StripeCompaction会比默认的策略更稳定。
- FIFOCompaction一般不会用到,这只是一种极端情况,比如用于 生存时间特别短的数据。如果你想用FIFOCompaction,可以先考虑使用DateTieredCompaction。
# 参考文章
- https://segmentfault.com/a/1190000020704842
← HBASE-原理总结 HBASE-读写优化 →










