TIP
本文主要是介绍 Kafka-数据采集综合案例 。
# Flume和Kafka完成实时数据的采集
写在前面 Flume和Kafka在生产环境中,一般都是结合起来使用的。可以使用它们两者结合起来收集实时产生日志信息,这一点是很重要的。如果,你不了解flume和kafka,你可以先查看我写的关于那两部分的知识。再来学习,这部分的操作,也是可以的。
实时数据的采集,就面临一个问题。我们的实时数据源,怎么产生呢?因为我们可能想直接获取实时的数据流不是那么的方便。我前面写过一篇文章,关于实时数据流的python产生器,文章地址:http://blog.csdn.net/liuge36/article/details/78596876 你可以先看一下,如何生成一个实时的数据...
思路??如何开始呢??
分析:我们可以从数据的流向着手,数据一开始是在webserver的,我们的访问日志是被nginx服务器实时收集到了指定的文件,我们就是从这个文件中把日志数据收集起来,即:webserver=>flume=>kafka
webserver日志存放文件位置 这个文件的位置,一般是我们自己设置的
我们的web日志存放的目录是在: /home/hadoop/data/project/logs/access.log下面
[hadoop@hadoop000 logs]$ pwd
/home/hadoop/data/project/logs
[hadoop@hadoop000 logs]$ ls
access.log
[hadoop@hadoop000 logs]$
# Flume
做flume,其实就是写conf文件,就面临选型的问题
source选型?channel选型?sink选型?
这里我们选择 exec source memory channel kafka sink
怎么写呢?
按照之前说的那样1234步骤
从官网中,我们可以找到我们的选型应该如何书写:
# 1) 配置Source
exec source
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
# 2) 配置Channel
memory channel
a1.channels.c1.type = memory
# 3) 配置Sink
kafka sink
flume1.6版本可以参照http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0/FlumeUserGuide.html#kafka-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
- 把以上三个组件串起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我们new一个文件叫做test3.conf 把我们自己分析的代码贴进去:
[hadoop@hadoop000 conf]$ vim test3.conf
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/project/logs/access.log
a1.sources.r1.shell = /bin/sh -c
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = hadoop000:9092
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.batchSize = 5
a1.sinks.k1.requiredAcks =1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里我们先不启动,因为其中涉及到kafka的东西,必须先把kafka部署起来,,
# Kafka的部署
kafka如何部署呢?? 参照官网的说法,我们首先启动一个zookeeper进程,接着,才能够启动kafka的server
# Step 1: Start the zookeeper
[hadoop@hadoop000 ~]$
[hadoop@hadoop000 ~]$ jps
29147 Jps
[hadoop@hadoop000 ~]$ zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop000 ~]$ jps
29172 QuorumPeerMain
29189 Jps
[hadoop@hadoop000 ~]$
# Step 2: Start the server
[hadoop@hadoop000 ~]$ kafka-server-start.sh $KAFKA_HOME/config/server.properties
#外开一个窗口,查看jps
[hadoop@hadoop000 ~]$ jps
29330 Jps
29172 QuorumPeerMain
29229 Kafka
[hadoop@hadoop000 ~]$
如果,这部分不是很熟悉,可以参考http://blog.csdn.net/liuge36/article/details/78592169
# Step 3: Create a topic
[hadoop@hadoop000 ~]$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flume_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "flume_kafka".
[hadoop@hadoop000 ~]$
# Step 4: 开启之前的agent
[hadoop@hadoop000 conf]$ flume-ng agent --name a1 --conf . --conf-file ./test3.conf -Dflume.root.logger=INFO,console
# Step 5: Start a consumer
kafka-console-consumer.sh --zookeeper hadoop000:2181 –topic flume-kafka
上面的第五步执行之后,就会收到刷屏的结果,哈哈哈!!
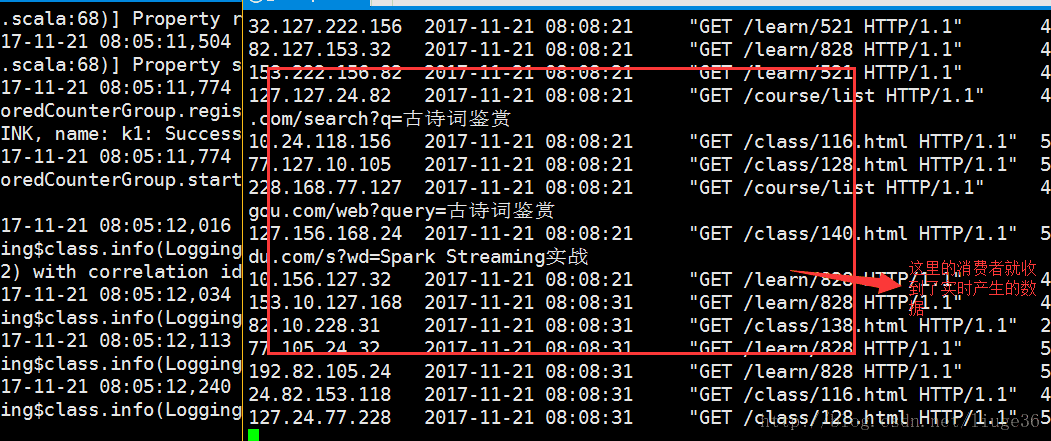
上面的消费者会一直一直的刷屏,还是很有意思的!!!
这里的消费者是把接收到的数据数据到屏幕上
后面,我们会介绍,使用SparkStreaming作为消费者实时接收数据,并且接收到的数据做简单数据清洗的开发,从随机产生的日志中筛选出我们需要的数据.....
# 【----------------------------】
# 采集文件到kafka
采集指定目录下文本数据到kafka
# 核心代码
package com.shenyuchong;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Date;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.regex.Pattern;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
/*
* 用途:
* 用于收集多个文件夹下文件内容到kafka;
* 文件一行一行发送;
* 支持发送完成后发出通知
* 文件发送完成后会将文件添加.COMPLETED后缀
* 支持采集指定后缀(多个)
* 支持对行进行正则,不匹配的行丢弃
* 仅支持对行进行分隔符切分
* 支持将切分后的字段按新分隔符重组
*
* 用法:
* mvn package打包成jar包:
* file2kafka-2.0.jar
* 编写配置文件xxx.conf内容如下:
* ip=192.168.1.91
* threadnum=20
* port=9092
* topic=customertopic
* path=/home/ftpuser/customer
* includesuffix=txt
* lineregex=^#\d.*$
* delimiter=\s+
* noticeurl=http://192.168.1.92:6009/schedule/customer
* fieldsquence=id,name,score
* 执行:
* java -jar file2kafka-2.0.jar xxx.conf
* 建议:用linux crontab进行定时执行(对同一个目录进行多次采集不会造成数据重复发送)
*/
public class App {
public static String fieldSquence = "";
public static int fieldNum = 0;
public static String ip = "";
public static String port = "";
public static String path = "";
public static String threadNum = "5";
public static String topic = "";
public static String lineRegex = "^.*$";
public static String delimiter = "\\s+";
public static String delimiter2 = "|||";
public static String includeSuffix = "aSuffix,bSuffix";
public static Pattern linePattern =null;
public static Properties props =null;
public static String noticeUrl;
public static void main(String[] args) {
/*
* 配置文件若不存在则抛出异常
*/
if(args.length<1){
try {
throw new Exception("无配置文件");
} catch (Exception e) {
e.printStackTrace();
}
}
try {
BufferedReader br = new BufferedReader(new FileReader(new File(args[0])));
String line="";
while((line=br.readLine())!=null){
line = line.replaceAll("\\s+", "");
if(line.indexOf("=")!=-1){
String[] kv=line.split("=");
String k= kv[0];
String v= kv[1];
if (k.equals("port")) port = v; //kafka 端口
if (k.equals("ip")) ip = v; //kafka 主机地址
if (k.equals("topic")) topic = v; //kafka 主题
if (k.equals("fieldsquence")) fieldSquence = v; //字段序列,逗号隔开
if (k.equals("threadnum")) threadNum = v; //采集线程数
if (k.equals("path")) path = v; //采集的目录,多目录逗号隔开
if (k.equals("lineregex")) lineRegex=v; //行正则,不匹配的行数据丢弃
if (k.equals("delimiter")) delimiter=v; //字段分隔符
if (k.equals("delimiter2")) delimiter2=v; //重组分隔符(发送到Kafka)
if (k.equals("includesuffix")) includeSuffix=v; //包含文件的后缀
if (k.equals("noticeurl")) noticeUrl=v; //采集完成通知的接口
}
}
br.close();
} catch (IOException e1) {
e1.printStackTrace();
}
/*
* kafka配置
*/
props = new Properties();
props.put("bootstrap.servers", ip+":"+port);
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
/*
* 将字段序列按逗号分隔,并获取字段序数目
*/
fieldNum = fieldSquence.split(",").length;
/*
* 行数据正则Pattern
*/
linePattern= Pattern.compile(lineRegex);
/*
* 线程池
*/
ExecutorService es = Executors.newFixedThreadPool(Integer.valueOf(threadNum));
/*
* 根据path目录获取文件
* 根据includesuffix选中文件调用send(file)
* 每个文件创建一个线程(线程实际总数由threadNum决定)
*/
for(String path:path.split(",")){
File dir=new File(path);
File[] files = dir.listFiles();
for(final File file:files){
for(String suffix:includeSuffix.split(",")){
if(file.getAbsolutePath().endsWith(suffix)){
es.submit(new Runnable() {
@Override
public void run() {
send(file);
}
});
}
}
}
}
/*
* 关闭线程池
*/
es.shutdown();
/*
* 线程池停止后通知后续服务直到后续服务接受了请求
*/
boolean stop=false,noticed=false;
try {
while(!stop||!noticed){
if (es.isTerminated()) {
stop=true;
}
Thread.sleep(2000);
if(stop){
noticed = connectSuccess(noticeUrl);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* 读取文件并发送到kafka,文件内容发送完成后将文件添加.COMPLETED后缀
*/
public static void send(File file){
BufferedReader bf =null;
StringBuffer sb = null;
try {
bf = new BufferedReader(new FileReader(file));
String line = null;
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
while((line = bf.readLine())!=null){
sb = new StringBuffer();
line = line.trim();
if(linePattern.matcher(line).matches()){
String[] fields = line.split(delimiter);
if(fields.length<fieldNum){
}else{
for(String fieldValue:fields)
sb.append(fieldValue).append(delimiter2);
sb.append(file.getAbsolutePath());
producer.send(new ProducerRecord<String, String>(topic, String.valueOf((new Date()).getTime()), sb.toString()),new Callback() {
@Override
public void onCompletion(RecordMetadata rm, Exception e) {
if(e!=null)System.out.println("send fail"+rm.toString()+",e:"+e.getMessage());
}
});
}
}else{
}
}
producer.close();
} catch (Exception e) {
System.out.println(e.toString());
}finally {
if(bf!=null)
try {
bf.close();
} catch (Exception e) {
e.printStackTrace();
}
}
file.renameTo(new File(file.getAbsolutePath()+".COMPLETED"));
}
/*
* 根据地址请求服务,请求成功则返回true
*/
public static boolean connectSuccess(String path){
URL url;
try {
url = new URL(noticeUrl);
HttpURLConnection con = (HttpURLConnection) url.openConnection();
if(con.getResponseCode()==200) return true;
} catch (Exception e) {
return false;
}
return false;
}
}
# 核心配置
配置文件编写customer2kafka.conf
ip=192.168.1.91
threadnum=20
port=9092
topic=customertopic
path=/home/ftpuser/customer
includesuffix=txt
lineregex=^#\d.*$
delimiter=\s+
noticeurl=http://192.168.1.92:6009/schedule/customer
fieldsquence=id,name,score
maven打包执行:
java -jar file2kafka-2.0.jar /opt/app/file2kafka/customer2kafka.conf
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.shenyuchong</groupId>
<artifactId>file2kafka</artifactId>
<version>2.0</version>
<packaging>jar</packaging>
<name>file2hive</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version><!--$NO-MVN-MAN-VER$ -->
</dependency>
</dependencies>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.gbd.App</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
# 参考文章
- https://www.cnblogs.com/liuge36/p/9883008.html
- https://www.cnblogs.com/shenyuchong/p/11454506.html










