TIP
本文主要是介绍 DataX-工作原理 。
# 图解 DataX 核心设计原理
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
前段时间我在 K8s 相关文章中有提到过数据同步的项目,该项目就是基于 DataX 内核构建的,由于公司数据同步的需求,还需要在 DataX 原有的基础上支持增量同步功能,同时支持分布式调度,在「使用 K8s 进行作业调度实战分享 (opens new window)」这篇文章中已经详细描述其中的实现。
基于我在项目中对 DataX 的实践过程,给大家分享我所理解的 DataX 核心设计原理。
# 设计理念
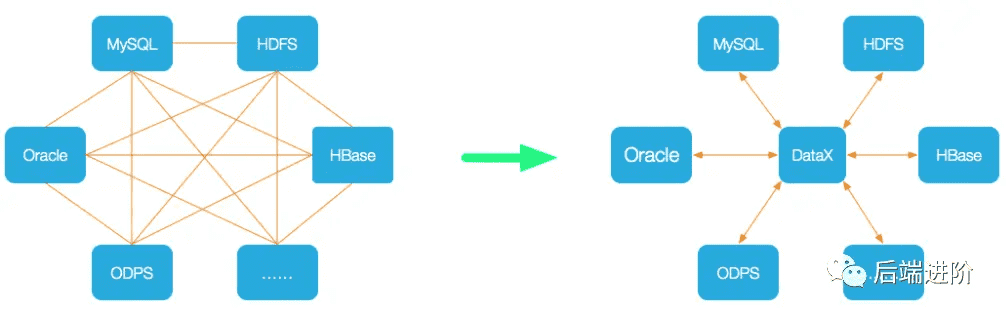
异构数据源离线同步是将源端数据同步到目的端,但是端与端的数据源类型种类繁多,在没有 DataX 之前,端与端的链路将组成一个复杂的网状结构,非常零散无法将同步核心逻辑抽象出来,DataX 的理念就是作为一个同步核心载体连接连接各类数据源,当我们需要数据同步时,只需要以插件的形式接入到 DataX 即可,将复杂的网状结构链路变成了一个星型结构,如下图所示:
# 架构设计
用过 IDEA 的小伙都知道,IDEA 有很多非常棒的插件,用户可根据自身编程需求,下载相关的插件,DataX 也是使用这种可插拔的设计,采用了 Framework + Plugin 的架构设计,如下图所示:

有了插件,DataX 可支持任意数据源到数据源,只要实现了 Reader/Writer Plugin,官方已经实现了主流的数据源插件,比如 MySQL、Oracle、SQLServer 等,当然我们也可以开发一个 DataX 插件。
# 核心概念
DataX 核心主要由 Job、Task Group、Task、Channel 等概念组成:
# 1、Job
在 DataX 中用来描述一个源端到一个目的端的同步作业,是 DataX 数据同步面向用户的最小业务单元。一个Job 对应 一个 JobContainer, JobContainer 负责 Job 的全局切分、调度、前置语句和后置语句等工作。
# 2、Task Group
一组 Task 的集合,根据 DataX 的公平分配策略,公平地分配 Task 到对应的 TaskGroup 中。一个 TaskGroup 对应一个 TaskGroupContainer,负责执行一组 Task。
# 3、Task
Job 的最小执行单元,一个 Job 可根据 Reader 端切分策略,且分成若干个 Task,以便于并发执行。
Job、Task Group、Task 三者之间的关系可以用如下图表示:

根据切分策略将一个 Job 切分成多个 Task,根据分配策略将多个 Task 组成一个 TaskGroup。
# 4、Channel
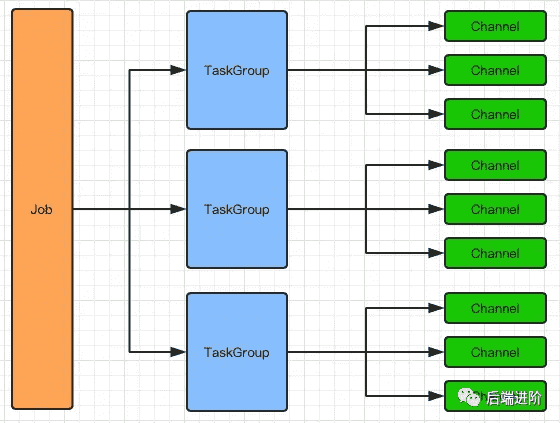
DataX 会单独启动一条线程运行运行一个 Task,而 Task 会持有一个 Channel,用作 Reader 与 Writer 的数据传输媒介,DataX 的数据流向都是按照 Reader—>Channel—>Writer 的方向流转,用如下图表示:

Channel 作为传输通道,即能充当缓冲层,同时还能对数据传输进行限流操作。
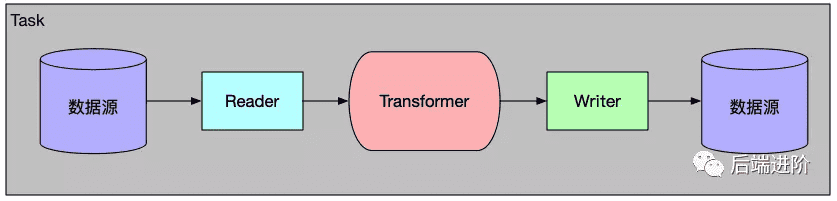
# 5、Transformer
DataX 的 transformer 模式同时还提供了强大的数据转换功能,DataX 默认提供了丰富的数据转换实现类,用户还可以根据项目自身需求,扩展数据转换。
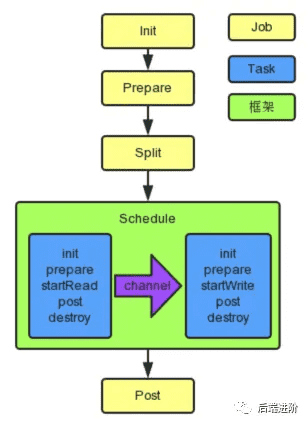
# 调度流程
DataX 将用户的 job.json 同步作业配置解析成一个 Job,DataX 通过 JobContainer 完成全局切分、调度、前置语句和后置语句等工作,整体调度流程用如下图表示:
# 1、切分策略
1)计算并发量(即 needChannelNumber 大小)
DataX有流控模式,其中,可以设置 bps 限速,tps 限速:
- bps 限速:needChannelNumber = 总 byteLimit / 单个 Channel byteLimit
- tps 限速:needChannelNumber = 总 recordLimit / 单个 Channel recordLimit
如果以上都没有设置,则会根据用户在 job.setting.speed.channel 配置的并发数量设置 needChannelNumber。
2)根据 needChannelNumber 将 Job 切分成多个 Task
这个步骤的具体切分逻辑交由相关插件去完成,例如 Rdb 对数据的拆分主要分成两类:
- 如果用户配置了具体的 Table 数量,那么就按照 Table 为最小单元进行拆分(即一个 Table 对应一个 Task),并生成对应的 querySql;
- 如果用户还配置了 splitPk,则会根据 splitPk 进行切分,具体逻辑是根据 splitPk 区间对 Table 进行拆分,并生成对应的 querySql。
# 2、公平分配策略
DataX 在执行调度之前,会调用 JobAssignUtil#assignFairly方法对切分好的 Task 公平分配给每个 TaskGroup。
在分配之前,会计算 TaskGroup 的数量,具体公式:
int taskGroupNumber = (int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup);
channelNumber 即为在切分策略中根据用户配置计算得到的 needChannelNumber 并发数量大小,channelsPerTaskGroup 为每个 TaskGroup 需要的并发数量,默认为 5。
求出 TaskGroup 的数量之后,就会执行公平分配策略,将 Task 平均分配个每个 TaskGroup,最后执行调度,完成整个同步作业。举个公平分配策略的例子:
假设 A 库有表 0、1、2,B 库上有表 3、4,C 库上有表 5、6、7,如果此时有 4 个 TaskGroup,则 assign 后的结果为:
taskGroup-0: 0, 4,
taskGroup-1: 3, 6,
taskGroup-2: 5, 2,
taskGroup-3: 1, 7
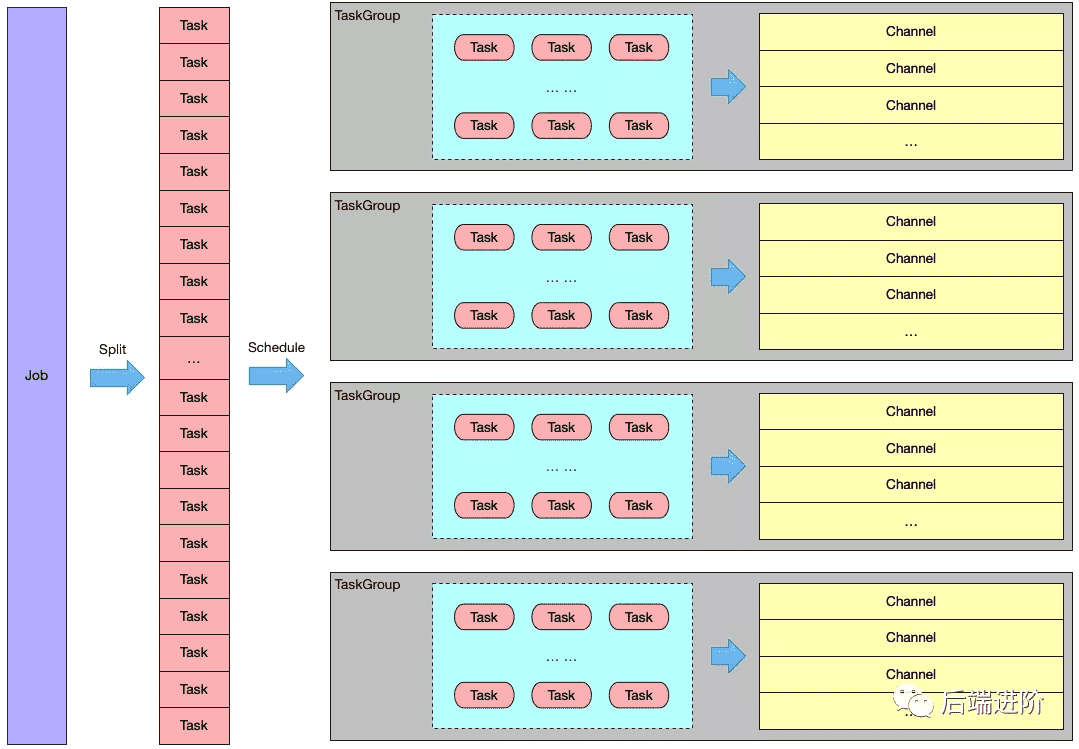
举个例子来描述 Job、Task、Task Group 之间的关系:
用户构建了一个数据同步作业,该作业的目的是将 MySql 的 100 张表同步到 Oracle 库中,假设此时用户设置了 20 个并发(即 channelNumber=20):
- DataX 根据表的数量切分成 100 个 Task;
- DataX 默认给每个 TaskGroup 分配 5 个 Channel,因此 taskGroupNumber = channelNumber / channelsPerTaskGroup = 20 / 5 = 4;
- 根据 DataX 的公平分配策略,会将 100 个 Task 平均分配给每个 TaskGroup,因此每个 TaskGroup 处理 taskNumber / taskGroupNumber = 100 / 4 = 25 个 Task。
以上的例子用如下图表示:
由于一个 Channel 对应一个线程执行,因此 DataX 的线程模型可以用如下图表示:
# 参考文章
- https://my.oschina.net/objcoding/blog/4549885
← DataX-基础介绍 DataX-同步案例 →










