TIP
本文主要是介绍 Kafka-数据采集案例原理 。
# flume+kafka整合采集数据案例
# 一、flume简介
# 1.1.1 概述
- Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
- Flume可以采集文件,socket数据包、文件、文件夹、kafka等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中
- 一般的采集需求,通过对flume的简单配置即可实现
- Flume针对特殊场景也具备良好的自定义扩展能力,
因此,flume可以适用于大部分的日常数据采集场景
# 1.1.2 运行机制
Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
每一个agent相当于一个数据传递员
内部有三个组件:
- Source:采集组件,用于跟数据源对接,以获取数据
- Sink:下沉组件,用于往下一级agent传递数据或者往最终存储系统传递数据
- Channel:传输通道组件,用于从source将数据传递到sink
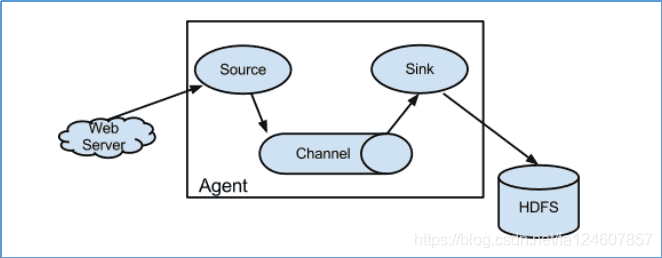
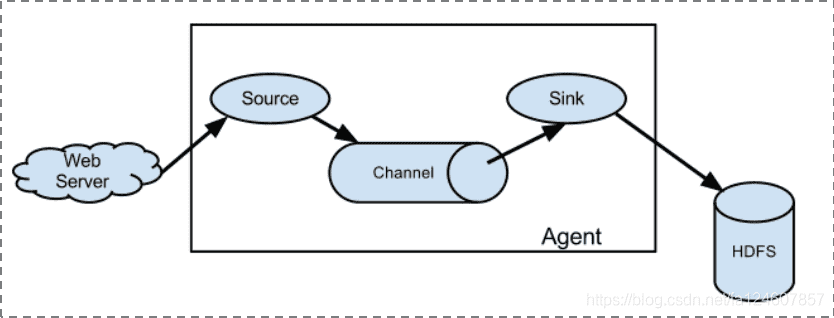
# 1.1.3 Flume采集系统结构图
- 简单结构
单个agent采集数据
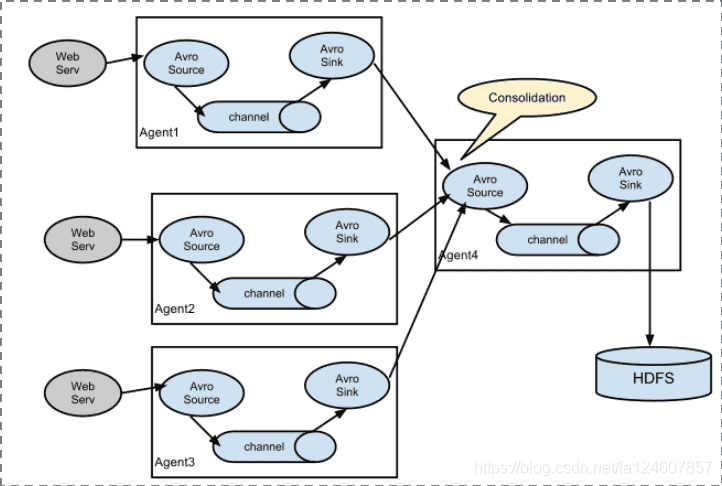
- 复杂结构
多级agent之间串联
# 二、kafka简介
# 2.1 简介
kafka是最初由linkedin公司开发的,使用scala语言编写,kafka是一个分布式,分区的,多副本的,多订阅者的日志系统(分布式MQ系统),可以用于搜索日志,监控日志,访问日志等。
# 2.2 支持的语言
kafka目前支持多种客户端的语言:java、python、c++、php等
# 2.3、apache kafka是一个分布式发布-订阅消息系统
apache kafka是一个分布式发布-订阅消息系统和一个强大的队列,可以处理大量的数据,并使能够将消息从一个端点传递到另一个端点,kafka适合离线和在线消息消费。kafka消息保留在磁盘上,并在集群内复制以防止数据丢失。kafka构建在zookeeper同步服务之上。它与apache和spark非常好的集成,应用于实时流式数据分析。
# 2.4 其他的消息队列
RabbitMQ
Redis
ZeroMQ
ActiveMQ
# 2.5 kafka的好处
可靠性:分布式的,分区,复制和容错的。
可扩展性:kafka消息传递系统轻松缩放,无需停机。
耐用性:kafka使用分布式提交日志,这意味着消息会尽可能快速的保存在磁盘上,因此它是持久的。
性能:kafka对于发布和定于消息都具有高吞吐量。即使存储了许多TB的消息,他也爆出稳定的性能。
kafka非常快:保证零停机和零数据丢失。
# 三、数据采集案例
# 3.1 整体数据流程
使用flume监控源头文件夹下的文件,当有新的文件时,自动采集文件数据到kafka。
# 3.2 flume的采集配置文件
#为我们的source channel sink起名
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#指定我们的source收集到的数据发送到哪个管道
a1.sources.r1.channels = c1
#指定我们的source数据收集策略
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/servers/flumedata
a1.sources.r1.deletePolicy = never
a1.sources.r1.fileSuffix = .COMPLETED
a1.sources.r1.ignorePattern = ^(.)*\\.tmp$
a1.sources.r1.inputCharset = GBK
#指定我们的channel为memory,即表示所有的数据都装进memory当中
a1.channels.c1.type = memory
#指定我们的sink为kafka sink,并指定我们的sink从哪个channel当中读取数据
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
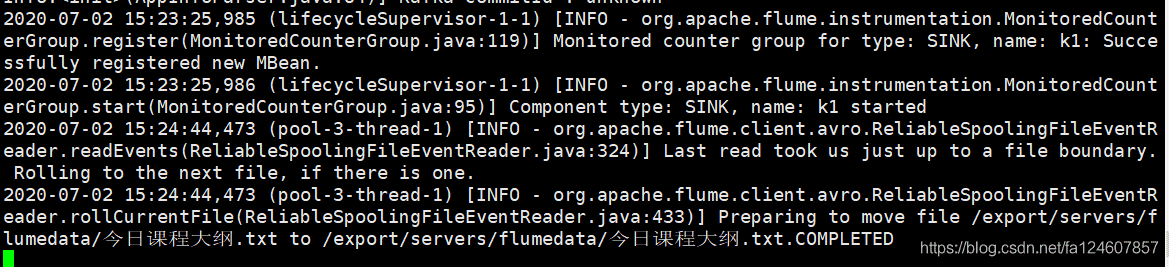
# 3.3 采集结果图
采集完成后,源头文件会自动加上completed后缀
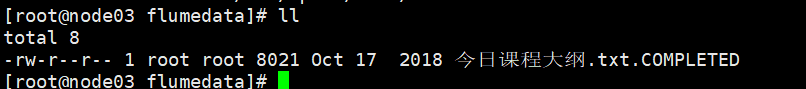
flume日志图
kafka消费端接收到的数据
四、总结
主要核心就是flume采集配置文件的开发,配置好source.channel.sink三个组件。
# 参考文章
- https://blog.csdn.net/fa124607857/article/details/107085371/










