TIP
本文主要是介绍 Mahout-基础知识 。
# Mahout简介
# 一、mahout是什么
Apache Mahout是ApacheSoftware Foundation (ASF)旗下的一个开源项目,提供了一些经典的机器学习的算法,皆在帮助开发人员更加方便快捷地创建智能应用程序。目前已经有了三个公共发型版本,通过ApacheMahout库,Mahout可以有效地扩展到云中。Mahout包括许多实现,包括聚类、分类、推荐引擎、频繁子项挖掘。

Apache Mahout的主要目标是建立可伸缩的机器学习算法。这种可伸缩性是针对大规模的数据集而言的。Apache Mahout的算法运行在ApacheHadoop平台下,他通过Mapreduce模式实现。但是,Apache Mahout并非严格要求算法的实现基于Hadoop平台,单个节点或非Hadoop平台也可以。Apache Mahout核心库的非分布式算法也具有良好的性能。
# mahout主要包含以下5部分
频繁挖掘模式:挖掘数据中频繁出现的项集。
聚类:将诸如文本、文档之类的数据分成局部相关的组。
分类:利用已经存在的分类文档训练分类器,对未分类的文档进行分类。
推荐引擎(协同过滤):获得用户的行为并从中发现用户可能喜欢的事物。
频繁子项挖掘:利用一个项集(查询记录或购物记录)去识别经常一起出现的项目。
# 二、mahout历史
Apache Mahout起源于2008年,经过两年的发展,2010年4月ApacheMahout最终成为了Apache的顶级项目。Mahout 项目是由 ApacheLucene(开源搜索)社区中对机器学习感兴趣的一些成员发起的,他们希望建立一个可靠、文档翔实、可伸缩的项目,在其中实现一些常见的用于集群和分类的机器学习算法。该社区最初基于 Ng et al. 的文章 “Map-Reduce for MachineLearning on Multicore”, 但此后在发展中又并入了更多广泛的机器学习方法。
# Mahout 的目标还包括:
(1)、建立一个用户和贡献者社区,使代码不必依赖于特定贡献者的参与或任何特定公司和大学的资金。
(2)、专注于实际用例,这与高新技术研究及未经验证的技巧相反。
(3)、提供高质量文章和示例。
# 三、mahout的特性
虽然在开源领域中相对较为年轻,但 Mahout 已经提供了大量功能,特别是在集群和CF 方面。(集群与CF概念模糊可看文章第四节)
# Mahout 的主要特性包括:
Taste CF。Taste 是 Sean Owen 在 SourceForge 上发起的一个针对 CF 的开源项目,并在 2008 年被赠予 Mahout。 一些支持 Map-Reduce 的集群实现包括 k-Means、模糊 k-Means、Canopy、Dirichlet 和 Mean-Shift。 Distributed Naive Bayes 和Complementary Naive Bayes 分类实现。 针对进化编程的分布式适用性功能。 Matrix 和矢量库。
上述算法的示例。
# 四、mahout当前已实现的三个具体的机器学习任务
它们正好也是实际应用程序中相当常见的三个领域:
协作筛选
集群
分类
先从概念的层面上更加深入地讨论这些任务。
# (1)、协作筛选
协作筛选(CF) 是 Amazon 等公司极为推崇的一项技巧,它使用评分、单击和购买等用户信息为其他站点用户提供推荐产品。CF 通常用于推荐各种消费品,比如说书籍、音乐和电影。但是,它还在其他应用程序中得到了应用,主要用于帮助多个操作人员通过协作来缩小数据范围。您可能已经在 Amazon 体验了 CF 的应用。
CF 应用程序根据用户和项目历史向系统的当前用户提供推荐。生成推荐的 4 种典型方法如下:
基于用户:通过查找相似的用户来推荐项目。由于用户的动态特性,这通常难以定量。
基于项目:计算项目之间的相似度并做出推荐。项目通常不会过多更改,因此这通常可以离线完成。
Slope-One:非常快速简单的基于项目的推荐方法,需要使用用户的评分信息(而不仅仅是布尔型的首选项)。
基于模型:通过开发一个用户及评分模型来提供推荐。
所有 CF 方法最终都需要计算用户及其评分项目之间的相似度。可以通过许多方法来计算相似度,并且大多数 CF 系统都允许您插入不同的指标,以便确定最佳结果。
# (2)、集群
对于大型数据集来说,无论它们是文本还是数值,一般都可以将类似的项目自动组织,或集群, 到一起。举例来说,对于全美国某天内的所有的报纸新闻,您可能希望将所有主题相同的文章自动归类到一起;然后,可以选择专注于特定的集群和主题,而不需要阅读大量无关内容。另一个例子是:某台机器上的传感器会持续输出内容,您可能希望对输出进行分类,以便于分辨正常和有问题的操作,因为普通操作和异常操作 会归类到不同的集群中。
与 CF 类似,集群计算集合中各项目之间的相似度,但它的任务只是对相似的项目进行分组。在许多集群实现中,集合中的项目都是作为矢量表示在 n维度空间中的。通过矢量,开发人员可以使用各种指标(比如说曼哈顿距离、欧氏距离或余弦相似性)来计算两个项目之间的距离。然后,通过将距离相近的项目归类到一起,可以计算出实际集群。
可以通过许多方法来计算集群,每种方法都有自己的利弊。一些方法从较小的集群逐渐构建成较大的集群,还有一些方法将单个大集群分解为越来越小的集群。在发展成平凡集群表示之前(所有项目都在一个集群中,或者所有项目都在各自的集群中),这两种方法都会通过特定的标准退出处理。流行的方法包括 k-Means 和分层集群。如下所示,Mahout 也随带了一些不同的集群方法。
# (3)、分类
分类(通常也称为 归类)的目标是标记不可见的文档,从而将它们归类不同的分组中。机器学习中的许多分类方法都需要计算各种统计数据(通过指定标签与文档的特性相关),从而创建一个模型以便以后用于分类不可见的文档。举例来说,一种简单的分类方法可以跟踪与标签相关的词,以及这些词在某个标签中的出现次数。然后,在对新文档进行分类时,系统将在模型中查找文档中的词并计算概率,然后输出最佳结果并通过一个分类来证明结果的正确性。
分类功能的特性可以包括词汇、词汇权重(比如说根据频率)和语音部件等。当然,这些特性确实有助于将文档关联到某个标签并将它整合到算法中。
机器学习这个领域相当广泛和活跃。理论再多终究需要实践。
# 五、mahout下载
1、官网地址
http://mirrors.cnnic.cn/apache/mahout/0.9/

下载 mahout-distribution-0.9.tar.gz
2、所有版本下载地址
http://archive.apache.org/dist/mahout/
在这里可以下载所有mahout版本。
参考文档:
Hadoop实战 第二版 陆嘉恒
http://baike.baidu.com/view/4029457.htm?fr=aladdin
http://www.ibm.com/developerworks/cn/java/j-mahout/#resources
# 【----------------------------】
# Mahout介绍和安装
# 简介
Mahout:是一个Apache的一个开源的机器学习库,主要实现了三大类算法Recommender
(collaborative filtering)、Clustering、classification。可扩展,用Java实现,用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Mahout为数据分析人员,解决了大数据的门槛;为算法工程师提供了基础算法库;为Hadoop开发人员提供了数据建模的标准。
——张丹(Conan) http://blog.fens.me/hadoop-mahout-roadmap/
# Mahout历史演变
Mahout began life in 2008 as a project of Apache`s lucene project .Lucene provides advanced implementations of search ,text mining and information-retrival techniques.In the universe of computer science ,there concepts are adjacent to machine learning techniques like clustering and to an extent ,classification .As a result,some of the work of the Lucene committers that fell more into these machine learning areas was spun off into its own subproject. Soon after ,Mahout absorbed the Taste open source collaborative filtering project.As of April 2010 ,Mahout became a top-level Apache project in its own right, and get a bran-new elephant rider logo to boot.
——Mahout in Action
25 April 2014 - Goodbye MapReduce
The Mahout community decided to move its codebase onto modern data processing systems that offer a richer programming model and more efficient execution than Hadoop MapReduce. Mahout will therefore reject new MapReduce algorithm implementations from now on. We will however keep our widely used MapReduce algorithms in the codebase and maintain them.
We are building our future implementations on top of a DSL for linear algebraic operations which has been developed over the last months. Programs written in this DSL are automatically optimized and executed in parallel on Apache Spark.
——http://mahout.apache.org/
# Hadoop家族中Mahout的结构图
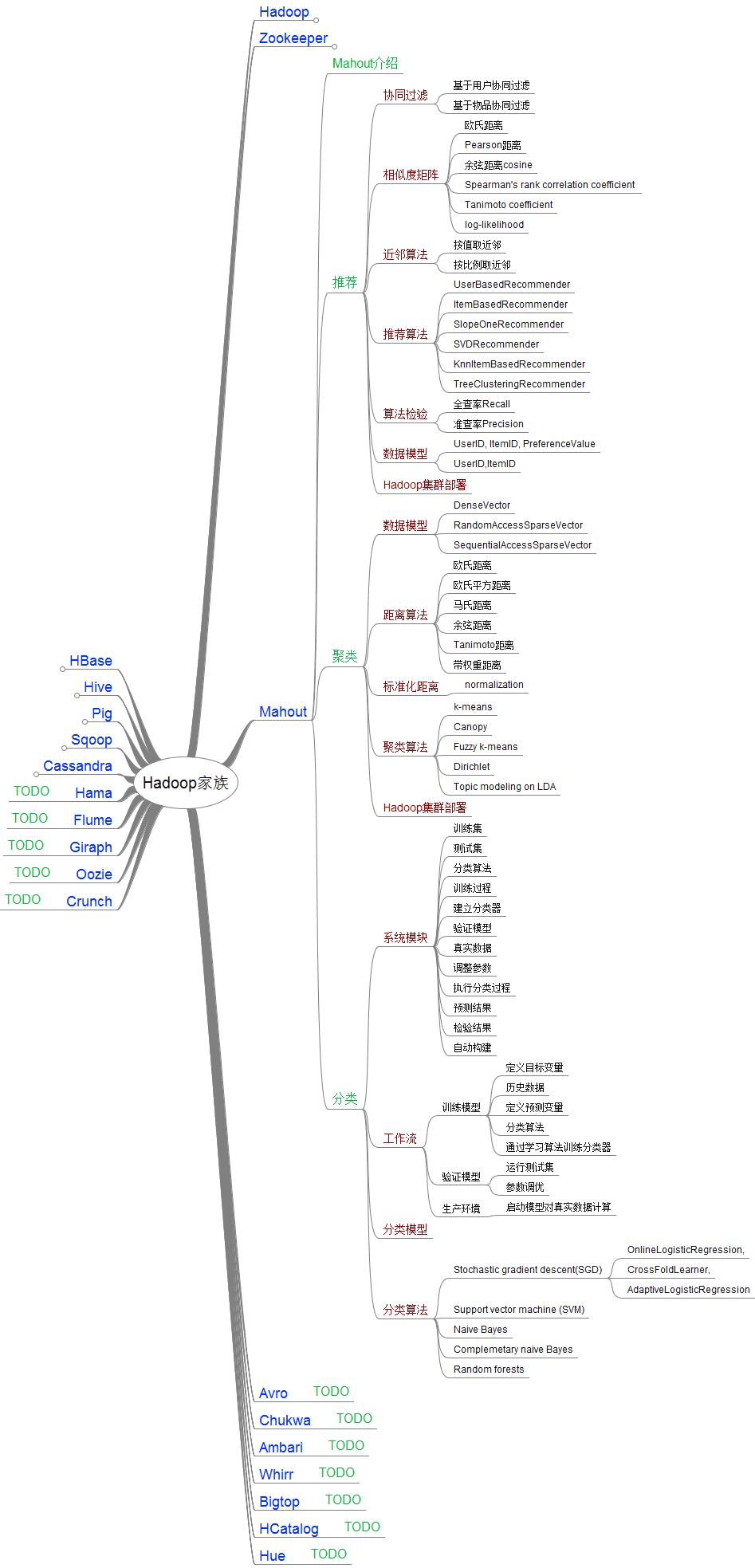
主要算法:
| 算法类 | 算法名 | 中文名 |
|---|---|---|
| 分类算法 | Logistic Regression | 逻辑回归 |
| Bayesian | 贝叶斯 | |
| SVM | 支持向量机 | |
| Perceptron | 感知器算法 | |
| Neural Network | 神经网络 | |
| Random Forests | 随机森林 | |
| Restricted Boltzmann Machines | 有限波尔兹曼机 | |
| 聚类算法 | Canopy Clustering | Canopy聚类 |
| K-means Clustering | K均值算法 | |
| Fuzzy K-means | 模糊K均值 | |
| Expectation Maximization | EM聚类(期望最大化聚类) | |
| Mean Shift Clustering | 均值漂移聚类 | |
| Hierarchical Clustering | 层次聚类 | |
| Dirichlet Process Clustering | 狄里克雷过程聚类 | |
| Latent Dirichlet Allocation | LDA聚类 | |
| Spectral Clustering | 谱聚类 | |
| 关联规则挖掘 | Parallel FP Growth Algorithm | 并行FP Growth算法 |
| 回归 | Locally Weighted Linear Regression | 局部加权线性回归 |
| 降维/维约简 | Singular Value Decomposition | 奇异值分解 |
| Principal Components Analysis | 主成分分析 | |
| Independent Component Analysis | 独立成分分析 | |
| Gaussian Discriminative Analysis | 高斯判别分析 | |
| 进化算法 | 并行化了Watchmaker框架 | |
| 推荐/协同过滤 | Non-distributed recommenders | Taste(UserCF, ItemCF, SlopeOne) |
| Distributed Recommenders | ItemCF | |
| 向量相似度计算 | RowSimilarityJob | 计算列间相似度 |
| VectorDistanceJob | 计算向量间距离 | |
| 非Map-Reduce算法 | Hidden Markov Models | 隐马尔科夫模型 |
| 集合方法扩展 | Collections | 扩展了java的Collections类 |
——http://blog.csdn.net (opens new window)
# Mahout在Hadoop 平台上的安装
1.下载mahout:http://archive.apache.org/dist/mahout/
2.下载Maven 一般ubuntu系统直接 sudo apt-get install maven
3.将mahout 的文件解压成文件夹mahout 并放入/usr文件夹
sudo tar -zxvf mahout-distribution-0.9.tar.gz
sudo mv mahout-distribution-0.9 /usr/mahout
4.创建一个脚本,配置mahout的环境。脚本内容
export JAVA_HOME=/usr/lib/jvm/jdk8/
export MAHOUT_HOME=/usr/mahout9
export MAHOUT_CONF_DIR=/usr/mahout9/conf
export PATH=$MAHOUT_HOME/bin:$MAHOUT_HOME/conf:$PATH
export HADOOP_HOME=/usr/hadoop
export HADOOP_CONF_DIR=/usr/hadoop/conf
export PATH=$PATH:$HADOOP_HOME/bin
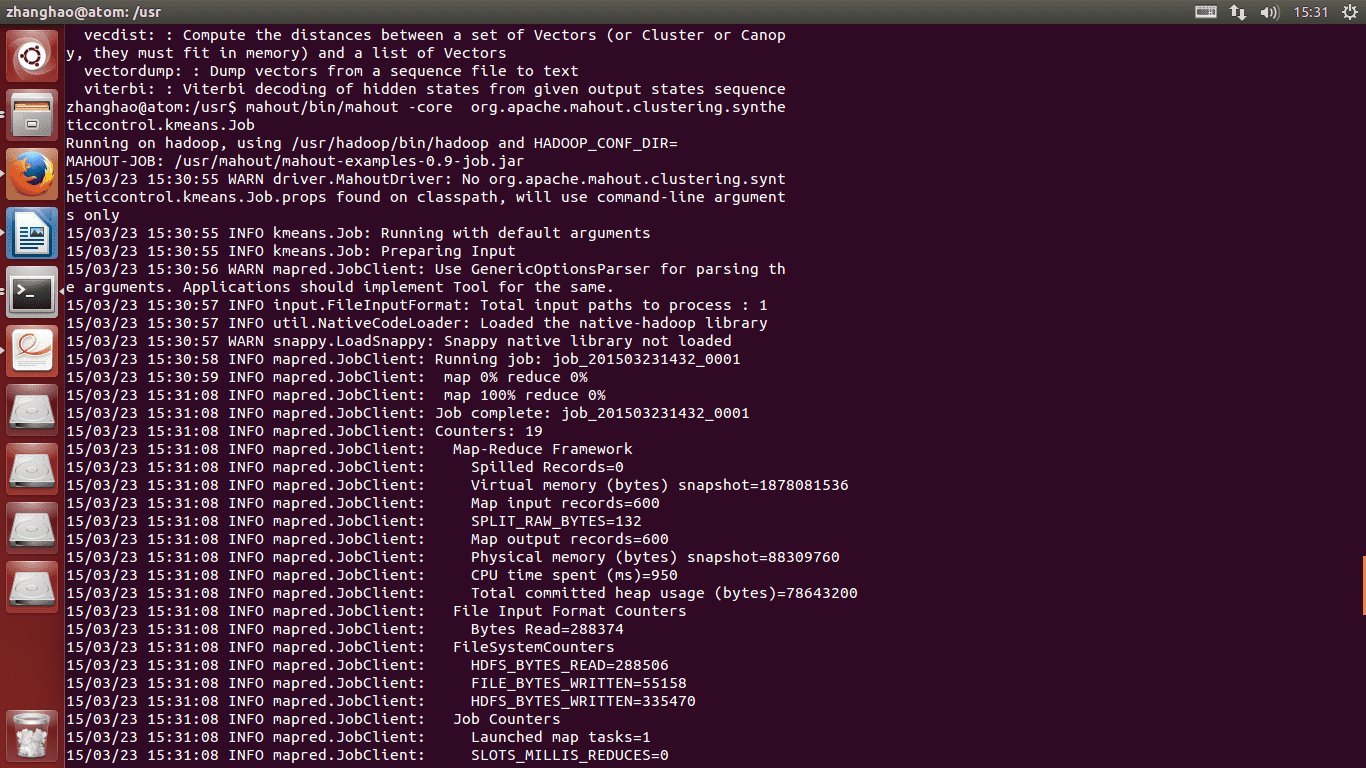
5.运行脚本文件,运行mahout命令
6.到这里就表示安装成功,下面下载一个测书数据,是一下mahout 的Kmeans聚类方法。
Sudo wget http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data

7.将数据上传到HDFS 上
hdfs fs -mkdir testdata
hdfs fs -put /usr/synthetic_control.data (opens new window) ./testdata
8.运行k-means聚类算法
mahout -core org.apache.clustering.syntheticcontrol.kmeans.Job
# 参考文章
- https://blog.csdn.net/baolibin528/article/details/39760443
- https://www.cnblogs.com/xiangfeng/p/4362301.html










