TIP
本文主要是介绍 神经网络-核心概念精华总结 。
# 神经网络算法
# 前馈神经网络
前馈神经网络(FeedForward NN ) :是一种最简单的神经网络,采用单向多层结构,各神经元分层排列,每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层,各层间没有反馈。
前馈网络包括三类节点:
- 输入节点(Input Nodes):外界信息输入,不进行任何 计 算 ,仅向下一层节点传递信息
- 隐藏节点(Hidden Nodes):接收上一 层节点的输入,进行计算,并将信息传到下一层节点
- 输出节点(Output Nodes):接收上_层节点的输入,进行计 算 , 并将结果输出
输入层和输出层必须有,隐藏层可以没有,即为单层感知器,隐藏层也可以不止一层,有隐藏层的前馈网络即多层感知器。
# 反馈神经网络
反馈神经网络(FeedBack NN ):又称递归网络、回归网络,是一种将输出经过一步时移再接入到输入层的神经网络系统。这类网络中,神经元可以互连,有些神经元的输出会被反馈至同层甚至前层的神经元。常见的有Hopfield神经网络、Elman神经网络、Boltzmann机等。
前馈神经网络和反馈神经网络的主要区别:
- 前馈神经网络各层神经元之间无连接,神经元只接受上层传来的数据,处理后传入下一层,数据正向流动;反馈神经网络层间神经元有连接,数据可以在同层间流动或反馈至前层。
- 前馈神经网络不考虑输出与输入在时间上的滞后效应,只表达输出与输入的映射关系;反馈神经网络考虑输出与输入之间在时间上的延迟,需要用动态方程来描述系统的模型。
- 前馈神经网络的学习主要采用误差修正法(如BP算法),计算过程一般比较慢,收敛速度也比较慢;反馈神经网络主要采用Hebb学习规则,一般情况下计算的收敛速度很快。
- 相比前馈神经网络,反馈神经网络更适合应用在联想记忆和优化计算等领域。
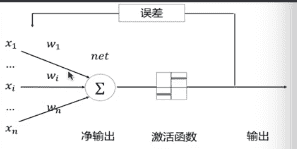
# 感知器
感知器(Perceptron): 用于线性客服模式分类的最简单的神经网络模型。由一个具有可调树突权值和偏置的神经元组成。1958年Frank Rosenblatt提出一种具有单层计算单元的神经网络,即为Perception。其本质是一个非线性前馈网络,同层内无互联,不同层间无反馈,由下层向上层传递。其输入、输出均为离散值,神经元对输入加权求和后,由阈值函数决定其输出。感知器实践上是一个简单的单层神经网络模型。
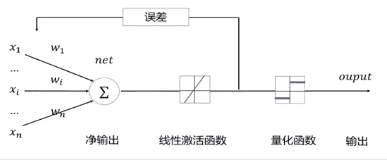
# 自适应线性单元
1962年,斯坦福大学教授Widrow提出一种自适应可调的神经网络,其基本构成单元称为自适应线性单元(Adaptive Linear Neuron, ADALINE),其主要作用是线性逼近一个函数式而进行模式联想。该模型是最早用于实际工程解决问题的人工神经网络。这种自适应可调的神经网络主要适应于信号处理中的自适应滤波、预测、模式识别等,主要应用于语言识别、天气预报、心电图诊断、信号处理以及系统识别等方面。
# 常见神经网络介绍
# SONN
自组织神经网络(Self Organization Neural Network, SONN),又称自组织竞争神经网络,通过自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数与结构。通常通过竞争学习(Competitive Learning)实现。
自组织神经网络属于前馈神经网络,采用无监督学习算法。其思路为:竞争层的神经元通过竞争(与输入模式进行匹配),选出一个获胜者,其输出就代表了对输入模式的分类。常见的有自适应共振理论网络ART、自组织特征映射神经网络SOM、对偶传播网络CPN等。适合解决模式分类和识别方面的问题。
竞争学习(Competition Learning) 是人工神经网络的一种学习方式,指网络单元群体中所有单元相互竞争对外界刺激模式响应的权利,竞争取胜的单元的连接权重向着对这一刺激有利的方向变化,相对来说竞争取胜的单元抑制了竞争失败单元对刺激模式的响应。属于自适应学习,使网络单元具有选择接受外界刺激模式的特性。竞争学习的更一般形式是不仅允许单个胜者出现,而是允许多个胜者出现,学习发生在胜者集合中各单元的连接权重上。
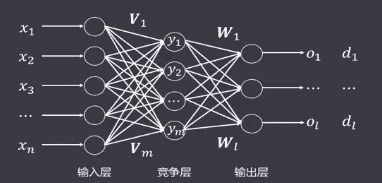
# LVQ
学习向量量化神经网络(Learning Vector Quantization, LVQ):在竞争网络的基础上,由Kohonen提出,其核心为将竞争学习与有监督学习相结合,学习过程中通过教师信号对输入样本的分配类别进行规定,克服了自组织网络采用无监督学习 算法带来的缺乏分类信息的弱点。
量化:在数字信号处理领域,是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。向最置化是对标置量化的扩展,更适用于高维数据。
网络结构特点:
- 由三层组成:输入层、竞争层、输出层
- 输入层和竞争层之间是全连接
- 一组竞争层节点对应一个输出节点
- 输入层到竞争层的权重可调整
- 竞争层到输出层的权重通常为固定值1
- 竞争层的学习规则为胜者为王WTA
- 竞争层的胜者输出为1,其余为0

# CPN
对偶传播神经网络(Counter-Propagation Network, CPN) , 1987年甶美国学者Robert Hecht-Nielsen提出,最早用来实现样本选择匹配系统,能存储二进制或模拟值的模式对,可用于联想存储、模式分类、函数通近、统计分析和数据压缩等。
网络拓扑结构: 共三层,各层之间为全连接,与三层BP网络相似。但其本质不同,实际上是由自组织网络+外星网络构成,其隐藏层即为竞争层,采用竞争学习规则,输出层为Grossberg层,采用Widrow-Hoff或者Grossberg学习规则。
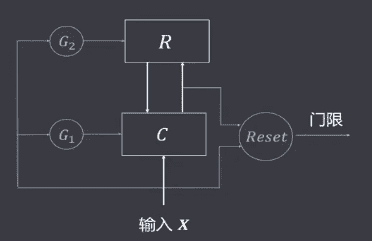
# ART
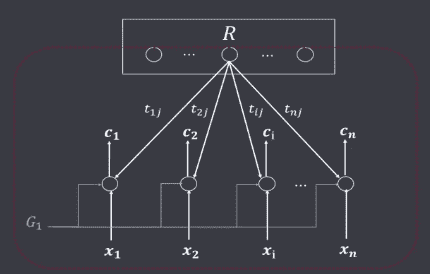
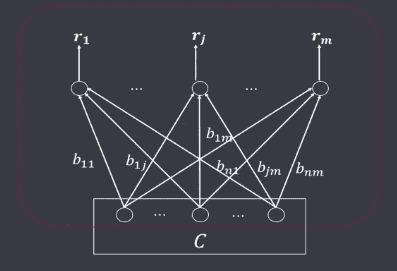
自适应共振理论(Adaptive Resource Theory,ART),1976年由美国波士顿大学学者G.A.Carpenter提出,试图为人类的心理和认证活动建立统一的数学理论。随后又和S.Grossberg提出了ART网络。 ART网络由两层组成两个子系统,一个叫比较层C,一个叫识别层R,及三种控制信号:复位信号(Reset)、逻辑控制信号(G1、G2)组成。
# BM
玻尔兹曼机(Bolzmann Machine, BM):也称 Stochastic Hopfield Network with Hidden Units,是一种随机递归神经网络,可以看做是一种随机生成的Hopfield网络。1983年-1986年,由Hinton和Sejnowski提出,该神经网络只有0和1两种状态,其取值根据规律统计法则决定,其形式与注明的统计力学家Boltzmann提出的分布相似,因此被称为Boltzmann机。
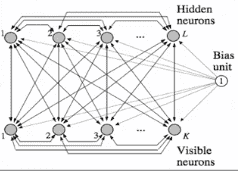
特征:
- 有可见节点和隐藏节点之分
- 形式上和单层反馈网络DHNN非常接近
- 可见节点实现输入输出,隐藏节点实现输入输出间的联系
- 从功能上看,和三层BP网络比较接近 -权重矩阵对称,且自反馈为0 ,即 w i j = w j i w_{ij} = w_{ji}wij=wji且w i j = 0 w_{ij} = 0wij=0
# RBM
受限玻尔兹曼机(Restricted Boltzmann Machine, RBM),是一种简化的特殊的玻尔兹曼机,1986年由Paul Smolensky提出。和BM相比,其隐藏层中的节点之间没有互相连接,其可见节点间也没有连接,因此其计算相对更简单。RBM可以应用于降维、分类、协同过滤、特征学习和主题建模等领域,根据任务的不同,可以选择监督学习或者非监督学习等方式进行神经网络模型训练。
特征:
- 两层结构:可见层和隐藏层
- 同层内无连接,不同层全连接:同层内节点激活状态独立
- 节点状态二值状态:0和1
- 计算相对BM简单
- 只要隐层节点足够多,能拟合任何离散分布
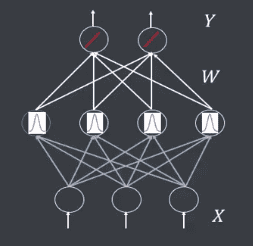
# RBFNN
径向基函数神经网络(Radical Basis Function Neural Network, RBF NN): 1988 年由 John Moody和Christian J Darken提出了一种网络结构,属于前向型神经网络,理论上可以任意精度逼近任意连续函数,适合解决分类问题。
径向基函数神经网络特征:
- 网络结构为三层前向网络
- 输入层到隐藏层无权重连接
- 隐藏层的激活函数为径向基函数(RBF)
- 从输入层到隐藏层的变换时非线性的
- 从隐藏层到输入层的变换时线性的
径向基函数(RBF ):某种沿径向对称的标量函数,通常定义为空间中某点到另外一个中心点的欧氏距离的单调函数。如果某点离中心点距离较远,则函数取值很小。
h ( x ) = e − ( x − c ) 2 r 2 h(x)=e^{-\frac{(x-c)^2}{r^2}}h(x)=e−r2(x−c)2
# DNN
深度神经网络(DNN):使用统计学方法从原始感官数据中提取高层特征,在大量的数据中获得输入空间的有效表征。
简单理解,深度神经网络就是有多个隐藏层的多层感知器网络,根据实际应用情况不同,其形态和大小也都不一样。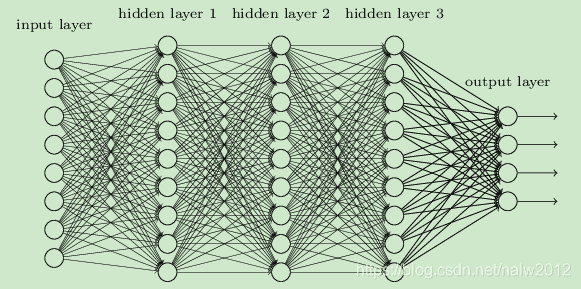
# CNN
卷积神经网络(CNN): 由Yann LeCun提出并应用在手写字体(MINST)识别上,其实质是一种多层前馈网络,擅长处理图像特别是大图像的处理和识别。
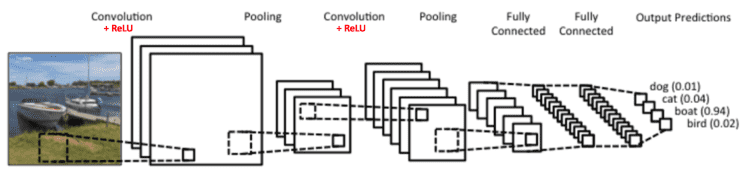
# RNN
前馈神经网络只能单独处理一个的输入,不同的输入之间被认为是相互独立没有联系的,但实际上很多时候输入之间是有序列关系的,需要使用递归神经网络(Recurrent Neural Network, RNN), 也称循环神经网络,其引入了 “记忆"的概念,即描述了当前输出于之前的输入信息的关系,递归的含义是指每个神经元都执行相同的任务,但是输出依赖于输入和"记忆”,常用语NLP、机器翻译、语音识别、图像描述生成、文本相似度等。
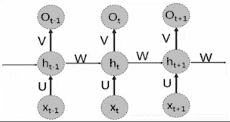
# LSTM
长短期记忆网络(Long Short-Term Memory, LSTM):是一种时间递归神经网络,适合用于处理和预测时间序列中间隔和延迟较长的重要事件。基于LSTM的系统可以学习翻译语言、控制机器人、图像分析、文档摘要、语音识别、图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等等任务。LSTM区別于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的"处理器",信息有用则被记忆,无用则被遗忘。目前已经证明,LSTM是解决长序依赖问题的有效技术,并且这种技术的普适性非常高,导致带来的可能性变化非常多。
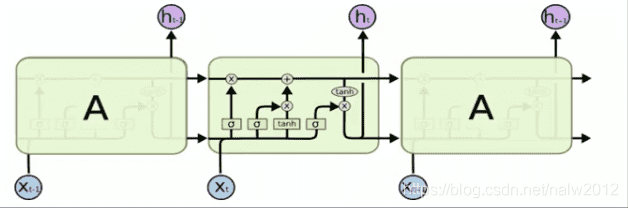
# 自编码器
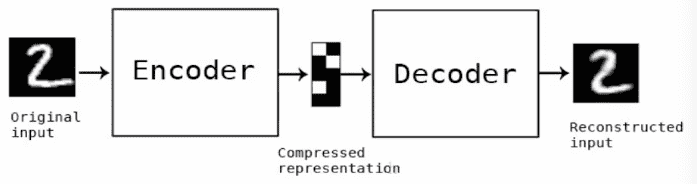
自动编码器(AutoEncoder):是人工神经网络的一种,主要用来处理数据的压缩,其数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的。原理为训练神经网络,通过捕捉可以代表输入信息的最关键的因素,让其输入能近似复制到输出,即让输入内容和输出内容近似一样。
# DBN
深度信念网结(Deep Belief Nets, DBN): 或称深度置信网络,神经网络的一种,由多个受限玻尔兹曼机组成。既可以用于非监督学习,类似于一个自编码器,也可以用于监督学习,类似于一个分类器。 从非监督学习来讲,其目的是尽可能地保留原始特征的特点,同时降低特征的维度。 从监督学习来讲,其目的在于使得分类错误率尽可能地小。 而不论是监督学习还是非监督学习,DBN的本质都是Feature Learning的过程,即如何得到更好的特征表达。
# GAN
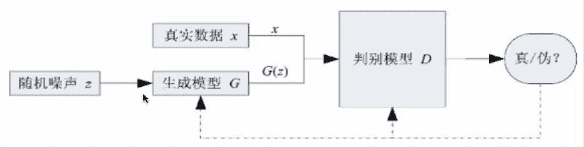
生成对抗网结(Generative Adversarial Network, GAN): 由Goodfellow在2014年提出,其核心思想来自于博弈论的"纳什均衡”。它包含两个网络模型:一个生成模型和一个判别模型。生成模型捕捉样本数据的分布,判别模型是一个二分类的分类器。生成模型接受一个随机的噪声,结合学习到的样本数据特征,生成一个新的数据,交由分类横型去判断是否是“真实的”。在训练过程中,生成模型尽量生成新数据去欺骗判断模型,判断模型会尽量去识别出不真实的数据,两者实际上是一个”二元极小极大博弈问题"。最终得到一个生成模型用来生成新的数据。
# 参考文章
- https://blog.csdn.net/nalw2012/article/details/85409915










