TIP
本文主要是介绍 神经网络-基础信息入门知识 。
# 大数据科普系列-神经网络算法
注:原作来自Dan Kellett(英国Captial One的数据科学部总监)的博客。
# 一、神经网络是什么?
神经网络(Neural Networks)是一系列模拟人脑工作机制的机器学习(Machine Learning)技术。 挖掘出隐藏在一堆数据背后的规律的能力对数据科学家至关重要,而神经网络技术很适合提取图片、视频和音频里面的特征。本文旨在从宏观维度来解释神经网络技术是如何奏效的,以及该技术中需要熟记心头的概念。
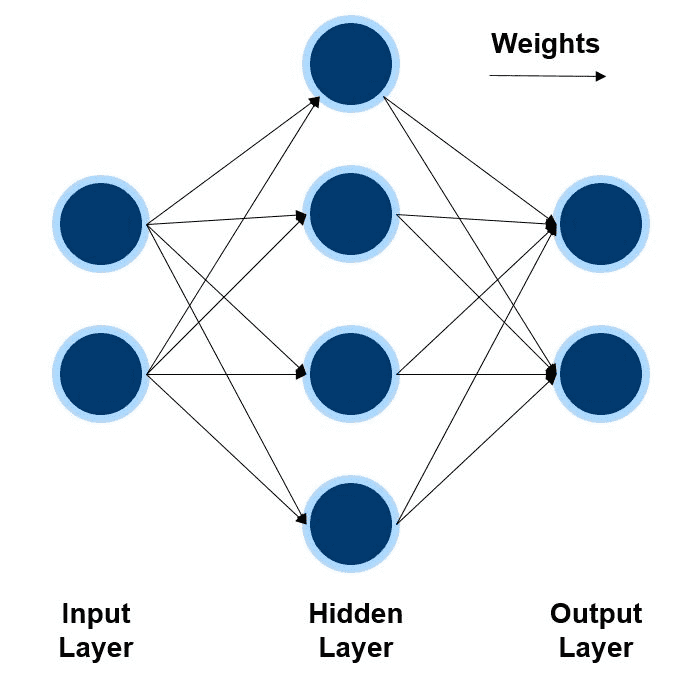
# 二、神经网络的结构
神经网络有不同的组成部分:
- 输入层(Input layer):指有助于预测结果的潜在的、描述性的因子。
- 隐藏层(Hidden layer):由用户自定义的层,每层拥有指定数量的神经元(Neurons)。
- 输出层(Output layer):人们想预测的规律或特征。例如图像的标签化,或Yes/No这样的简单判别。
# 三、训练神经网络
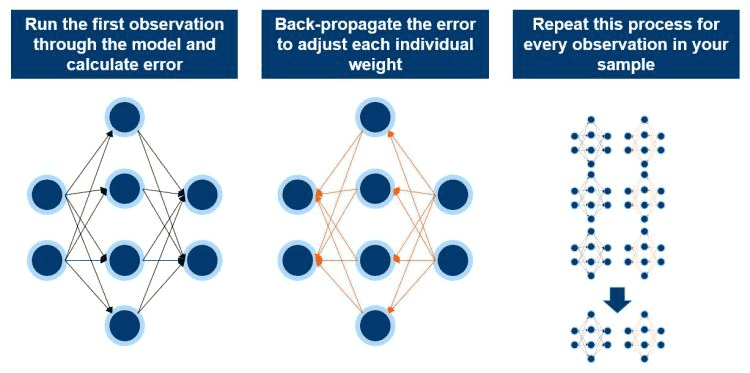
在一个初级神经网络中,我们通过每次运行一个案例和根据误差更新权重的方法来训练该系统。目的就是经过一段时间的训练后,神经网络应该1)更加契合你的数据集和2)最小化误差。在初级神经网络中,权重的更新是一个双向过程,既有前向反馈(feed-forward)又有后向传播(back-propagation):
- 前向反馈:这涉及到在网络中处理观测(Observation)时,每次只有一个动作。给定权重后,神经网络模型会输出一个预测,通过对比该预测和实际输出,便可计算误差。
- 后向传播:这涉及到将误差通过网络往后传播以调节各个权重,最终能得到更精确的实际输出。更新的权重则被用在下一次观测中。
# 三、训练神经网络
在一个初级神经网络中,我们通过每次运行一个案例和根据误差更新权重的方法来训练该系统。目的就是经过一段时间的训练后,神经网络应该1)更加契合你的数据集和2)最小化误差。在初级神经网络中,权重的更新是一个双向过程,既有前向反馈(feed-forward)又有后向传播(back-propagation):
- 前向反馈:这涉及到在网络中处理观测(Observation)时,每次只有一个动作。给定权重后,神经网络模型会输出一个预测,通过对比该预测和实际输出,便可计算误差。
- 后向传播:这涉及到将误差通过网络往后传播以调节各个权重,最终能得到更精确的实际输出。更新的权重则被用在下一次观测中。
额外调节(Extra tuning):这是调节神经网络的基础手法。但在将模型往数据集拟合(fitting)时,如下关键参数需要注意:
- 学习率(Learning rate): 权重的后向传播不能太敏感,否则你的模型有可能会因为某些观测有剧烈起伏。同样地,你也不希望你的模型对新的数据集没有响应。因此,在模型调优中设定一个不偏不倚的学习率是很紧要的。
- 拓扑结构(Topology):具体而言,就是神经网络的设计(如隐藏层数量及每层中的神经元的数量)。它随着你的目标不同而变化,也和你所采用的具体神经网络算法相关。广义上来说,如果你想要更多的特征,则增加模型中神经元的数量;如果只是想得到最紧要的特征,则减少神经元数量。要是你采用的是深度学习(Deep learning)这样的复杂算法,拓扑结构就更加紧要。
- 退出率(Dropout rate):神经网络的缺陷就是容易过拟合(Over-fitting),且训练过程耗时。尽管它们是可扩展的(scalable)且Map-reduce的神经网络算法也存在。当神经元退出时,它们的所有连接以给定的概率一同退出网络。这就解释了相同的训练会产生一个神经网络集成(Ensemble); 此外,得当的退出率可提高神经网络的性能。
# 四、神经网络的适用场景
如同数据科学中的其他技术,神经网络也只是处理海量商业数据时众多算法大类里的一种备选方案。该技术是非常处理器密集型(processor-intensive)的,因此预测结果可能很难诠释。如果你的目标不是清晰易懂的分析结果而是处理能力,你可以考虑使用神经网络技术。在解决人脑擅长的领域时(如文本、图像或语音的识别),神经网络尤其适合。
# 【----------------------------】
# 神经网络基本类型
神经网络的基本类型与学习算法:
目前已有的数十种神经网络模型,按网络结构划分可归纳为三大类:
- 前馈网络
- 反馈网络
- 自组织网络。
前馈神经网络则是指神经元分层排列,分别组成输入层、中间层和输出层。每一层的神经元只接受来自前一层神经元的输入,后面的层对前面层没有信号反馈。输入模式经过各层的顺序传播,最后在输出层上得到输出。这类网络结构通常适于预测、模式识别及非线性函数逼近,一般典型的前向神经网络基于梯度算法的神经网络如BP网络,最优正则化方法如SVM,径向基神经网络和极限学习机神经网络。
反馈网络又称回归网络,输入信号决定反馈系统的初始状态,系统经过一系列状态转移后逐渐收敛于平衡状态,因此,稳定性是反馈网络最重要的指标之一,比较典型的是感知器网络、Hopfield神经网络、海明祌经网络、小波神经网络双向联系存储网络(BAM)、波耳兹曼机。
自组织神经网络是无教师学习网络,它模拟人脑行为,根据过去经验自动适应无法预测的环境变化,由于无教师信号,这类网络通常采用竞争原则进行网络学习。
# 【----------------------------】
# 科普 | 深度学习算法三大类:CNN,RNN和GAN
人工智能在近几年处于爆发期,越来越多意想不到的应用被提出,说明AI还有非常多的发展空间。相同的数据型态,利用不同的方法分析,就可以解决不同的课题。例如目前已相当纯熟的人脸识别技术,在国防应用可以进行安保工作;企业可做员工门禁系统;可结合性别、年龄辨识让卖场进行市调分析,或结合追踪技术进行人流分析等。
本篇接下来要针对深度学习方法的数据类型或算法,介绍AI常见的应用。
以算法区分深度学习应用,算法类别可分成三大类:
- 常用于影像数据进行分析处理的卷积神经网络(简称CNN)
- 文本分析或自然语言处理的递归神经网络(简称RNN)
- 常用于数据生成或非监督式学习应用的生成对抗网络(简称GAN)
# CNN
因为应用种类多样,本篇会以算法类别细分,CNN主要应用可分为图像分类(image classification)、目标检测(object detection)及语义分割(semantic segmentation)。下图可一目了然三种不同方法的应用方式。
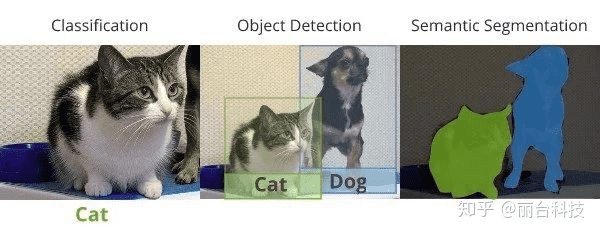
# 1、图像分类 (Classification)
顾名思义就是将图像进行类别筛选,通过深度学习方法识别图片属于哪种分类类别,其主要重点在于一张图像只包含一种分类类别,即使该影像内容可能有多个目标,所以单纯图像分类的应用并不普遍。不过由于单一目标识别对深度学习算法来说是正确率最高的,所以实际上很多应用会先通过目标检测方法找到该目标,再缩小撷取影像范围进行图像分类。所以只要是目标检测可应用的范围,通常也会使用图像分类方法。
图像分类也是众多用来测试算法基准的方法之一,常使用由ImageNet举办的大规模视觉识别挑战赛(ILSVRC)中提供的公开图像数据进行算法测试。图像分类属于CNN的基础,其相关算法也是最易于理解,故初学者应该都先以图像分类做为跨入深度学习分析的起步。使用图像分类进行识别,通常输入为一张图像,而输出为一个文字类别。
# 2、目标检测 (Object Detection)
一张图像内可有一或多个目标物,目标物也可以是属于不同类别。算法主要能达到两种目的:找到目标坐标及识别目标类别。简单来说,就是除了需要知道目标是什么,还需要知道它在哪个位置。
目标检测应用非常普遍,包含文章开头提到的人脸识别相关技术结合应用,或是制造业方面的瑕疵检测,甚至医院用于X光、超音波进行特定身体部位的病况检测等。目标识别的基础可想象为在图像分类上增加标示位置的功能,故学习上也不离图像分类的基础。不过目标检测所标示的坐标通常为矩形或方形,仅知道目标所在位置,并无法针对目标的边缘进行描绘,所以常用见的应用通常会以「知道目标位置即可」作为目标。
最常见的算法为YOLO及R-CNN。其中YOLO因算法特性具有较快的识别速度,目前已来到v3版本。R-CNN针对目标位置搜寻及辨识算法和YOLO稍有不同,虽然速度稍较YOLO慢,但正确率稍高于YOLO。使用目标检测进行识别,通常输入为一张图像,而输出为一个或数个文字类别和一组或多组坐标。
# 3、语义分割 (Semantic Segmentation)
算法会针对一张图像中的每个像素进行识别,也就是说不同于目标检测,语义分割可以正确区别各目标的边界像素,简单来说,语义分割就是像素级别的图像分类,针对每个像素进行分类。当然这类应用的模型就会需要较强大的GPU和花较多时间进行训练。
常见应用类似目标检测,但会使用在对于图像识别有较高精细度,如需要描绘出目标边界的应用。例如制造业上的瑕疵检测,针对不规则形状的大小瑕疵,都可以正确描绘。医学上常用于分辨病理切片上的病变细胞,或是透过MRI、X光或超音波描绘出病变的区块及类别。算法如U-Net或是Mask R-CNN都是常见的实作方法。使用语义分割进行识别,通常输入为一张图像,而输出也为一张等大小的图像,但图像中会以不同色调描绘不同类别的像素。
# RNN
有别于CNN,RNN的特色在于可处理图像或数值数据,并且由于网络本身具有记忆能力,可学习具有前后相关的数据类型。例如进行语言翻译或文本翻译,一个句子中的前后词汇通常会有一定的关系,但CNN网络无法学习到这层关系,而RNN因具有内存,所以性能会比较好。因为可以通过RNN进行文字理解,其他应用如输入一张图像,但是输出为一段关于图像叙述的句子。(如下图)

RNN虽然解决了CNN无法处理的问题,但其本身仍然有些缺点,所以现在很多RNN的变形网络,其中最常被使用的网络之一为长短记忆网络(Long Short-Term Network,简称LSTM)。这类网络的输入数据不限于是图像或文字,解决的问题也不限于翻译或文字理解。数值相关数据也同样可以使用LSTM进行分析,例如工厂机器预测性维修应用,可透过LSTM分析机台震动讯号,预测机器是否故障。在医学方面,LSTM可协助解读数以千计的文献,并找出特定癌症的相关信息,例如肿瘤部位、肿瘤大小、期数,甚至治疗方针或存活率等等,透过文字理解进行解析。也可结合图像识别提供病灶关键词,以协助医生撰写病理报告。
# GAN
除了深度学习外,有一种新兴的网络称为强化学习(Reinforcement Learning),其中一种很具有特色的网络为生成式对抗网络(GAN)。
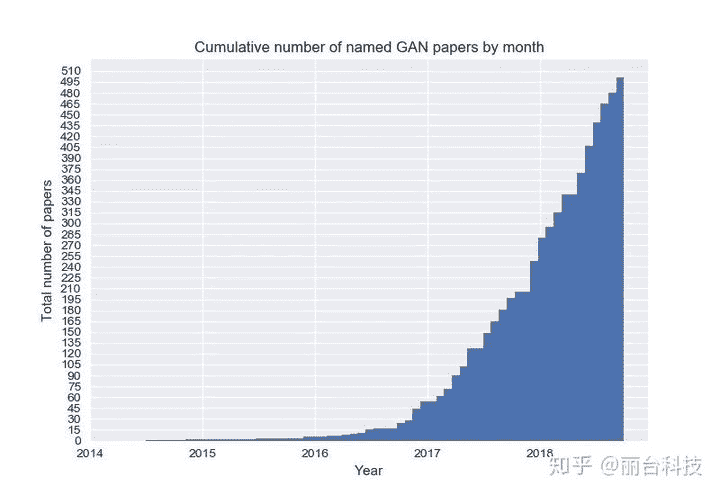
GAN的应用相关论文成长幅度相当大(如下图)。
这里不详述GAN的理论或实作方式,而是探讨GAN实际应用的场域。深度学习领域最需要的是数据,但往往不是所有应用都可以收集到大量数据,并且数据也需要人工进行标注,这是非常消耗时间及人力成本。图像数据可以通过旋转、裁切或改变明暗等方式增加数据量,但如果数据还是不够呢?目前有相当多领域透过GAN方法生成非常近似原始数据的数据,例如3D-GAN就是可以生成高质量3D对象。当然,比较有趣的应用例如人脸置换或表情置换。(如下图)

另外,SRGAN (Super Resolution GAN)可用于提高原始图像的分辨率,将作为低分辨率影像输入进GAN模型,并生成较高画质的影像(如下图)。这样的技术可整合至专业绘图软件中,协助设计师更有效率完成设计工作。

NVIDIA也有提供一些基于GAN的平台的应用,包含透过GauGAN网络,仅需绘制简单的线条,即可完成漂亮的画作,并且还能随意修改场景的风格(如下图)。

# 参考文章
- https://www.cnblogs.com/chamie/p/5579884.html
- https://zhuanlan.zhihu.com/p/163065584
- https://zhuanlan.zhihu.com/p/22475839










