TIP
本文主要是介绍 推荐系统-精华基础总结 。
# 实时个性化推荐介绍
随着互联网的深入发展和产品布局的多元化,越来越多的企业通过提供快节奏的产品及服务消耗用户的碎片化时间,从而赢得用户的青睐。这类产品通过便捷的UI交互来跟用户进行实时互动,在极短的时间内给用户“奖赏”,让用户欲罢不能,根本停不下来。这类产品普遍用到的一个技术就是实时个性化推荐技术。
相比于传统的个性化推荐每天更新用户的推荐结果,实时推荐基于用户最近几秒的行为实时调整用户的推荐结果。实时推荐系统让用户当下的兴趣立刻反馈到了推荐结果的变化上,可以给用户所见即所得的视觉体验,它牢牢地抓住了用户的兴趣,让用户沉浸在其中。实时推荐技术大量用于现在的主流产品上,基本上你常用的互联网APP的核心推荐算法都已经实时化了,包括头条、淘宝、快手、B站等等,毫不夸张地说实时推荐是推荐系统未来的发展趋势。
在本篇文章中,我们就来讲解实时个性化推荐相关的知识点。具体来说,我们会从实时推荐系统背景介绍、实时推荐系统的价值、实时推荐系统的应用场景、实时推荐系统的整体架构、实时推荐系统的技术选型、实时推荐算法与工程实现介绍、构建实时推荐系统面临的困难与挑战、实时推荐系统的未来发展等8个方面来进行讲解。期望本文可以帮助读者全方位地了解实时推荐系统相关的业务、原理与技术细节,本文可以作为读者学习和构建实时推荐系统的参考指南。
# 一、实时推荐系统背景介绍
**所谓实时推荐系统,就是根据用户当前行为或者用户的主动操作(如下拉、滑动等),推荐系统实时更新展示给用户的推荐结果,前端快速反应用户的兴趣变化,给用户视觉上的冲击与强感知。**大家比较熟悉的实时推荐系统是今日头条、抖音、快手上的推荐(参见下面图1),通过下拉或者上下滑动来实时更新推荐列表。如果实时推荐的结果采用瀑布流的形式呈现给用户,一般也将实时推荐称为信息流推荐,如今日头条推荐、微信朋友圈“看一看”等都可以这么叫。
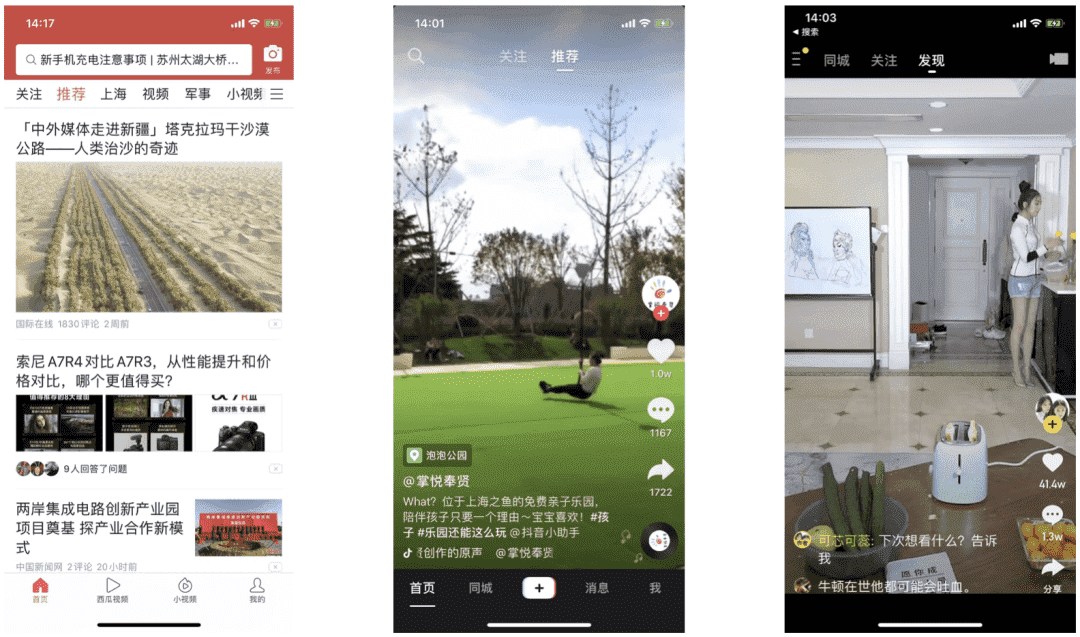
图1:今日头条、抖音、快手上的实时推荐
实时推荐系统不是一种新的推荐算法(当然会对算法进行适当的调整优化,以适应实时性的需要),而是一种新的推荐形态,一种新的工程架构,是将传统的T+1(按天)推荐调整为秒级推荐,是处理效率的极大提升。处理速度提升了,当然对算法、工程架构、交互方式也提出了新的要求。
任何事情的出现和发展一定是有相关背景的,实时推荐也不例外,我认为主要有如下几个原因导致实时推荐的出现和火爆:
# 1. 技术的进步
首先是智能手机的普及和摄像技术、无线网络的发展,让每个人都成为数据生产方,我们时时刻刻都在制造数据。数据量的爆发增长,推动了大数据与云计算技术的出现和发展。大数据和云计算让我们可以更快、更便捷、更高效地处理大规模的海量数据,实时数据处理成为可能,这是实时推荐系统出现的先决条件。
# 2. 产品的“快消”化、用户时间的碎片化
新技术本身就是一种资源,所以一般一种新技术出现会带来非常大的红利期,出现一段较长时间的技术应用爆发期。在新红利的刺激下,越来越多的创业者寻找机会和突破,期望从红利中分一杯羹。技术催化了各种各样的产品,像头条、快手、抖音等无不都是在这样的背景下产生的。这类产品有一个特点,属于“快消类”产品(用户消费一个标的物所花时间较短),消费的也是用户的碎片化时间,用户在地铁上、公交上、吃饭排队、甚至上厕所都可以高效使用这类产品。产品的“快消”化、用户时间的碎片化,这要求产品需要实时响应用户的需求,对用户的行为作出及时反馈,这正是实时推荐系统擅长的方向,因而实时推荐最早在这些产品上出现就不足为奇了。
# 3. 人机交互方式的便捷性
触屏技术的发展,让用户与产品交互更加方便快捷,交互可以在瞬间完成,毫无障碍,无任何学习成本。快捷的交互自然要求产品可以进行快速的响应,这也间接催生了实时推荐技术的普及和发展。
# 4. 人天生喜欢动态变化的东西、人的需求也越来越主动
移动互联网时代,用户每时每刻都在线。人的大脑是无法停下来的(即使是睡着了,也在做梦,大脑也没停),一定要注意到一件事情,这就是人的注意力,静止不变的东西是很难吸引用户兴趣的,实时推荐对用户反馈做实时调整,是动态变化的过程,更容易吸引用户的关注。年轻一代更希望对生活有控制权,对产品也一样,希望自己可以把控产品的交互逻辑和结果展示,实时个性化推荐的这种下拉更新推荐结果的方式就很自然地将控制权交给了用户。
# 5. 信息产生的速度更加快速
前面提到摄像头技术的发展等让信息产生的速度按照指数方式增长,信息产生的速度远大于人类消费信息的速度。而实时推荐提升了信息分发的效率,可以让信息得到更加有效的分发与利用,因此也是提升资源使用效率的一种方式。
# 6. 激烈的产品竞争
当移动互联网红利结束之时,没有太多新的流量注入,所有的产品在争夺固有的流量,产品之间的竞争愈发激烈,谁能更好地服务用户,谁就能在激烈的市场竞争中赢得主动权。实时个性化推荐由于跟用户的实时互动性,可以更好地满足用户的需求,让用户沉浸在其中,因此可以极大地提升用户的体验,这让实时推荐技术成为产品争夺用户和流量的有力武器。
实时推荐是技术发展和产品迭代的必然趋势,也是人类自身诉求满足的有效方式,这只是实时推荐技术出现和发展的必要条件。实时推荐之所以这么火爆,成为当今绝大多数产品的标配,并且也是推荐系统未来发展的趋势,是因为实时推荐系统极具价值。实时推荐是非常有业务价值的,这就是我们下节要讲解的内容。
# 二、实时推荐系统的价值
实时推荐系统通过降低用户的行为和系统的反馈之间的时间间隔,让用户可以马上享受到自我行为的奖赏,这本身就是一种用户价值的体现。具体来说,实时推荐系统的价值至少可以从如下4个维度来体现。
# 1. 提升用户体验,提升用户的满意度
在实时推荐系统中,用户可以实时与推荐模块交互,推荐模型实时给用户做出反馈,提升了用户与产品交互的频率。用户的每次交互都带来了新的刺激,这让用户更愿意沉浸在其中,从而满足了用户的某种心理需求,而用户需求满足的程度决定了用户对产品的满意度。因此,实时个性化推荐一定是可以提升用户满意度的。
# 2. 提升用户粘性,提升用户使用时长
从产品来看,实时推荐可以让用户实时获得反馈,用户的需求得到即刻的满足,这让用户非常兴奋,停不下来,不知不觉中花了大把的时间,消费了大量的内容。总体来说,提升了用户的粘性,让用户更愿意驻留更多的时间。
# 3. 增加内容的曝光、分发与消费
实时个性化推荐大大提升了内容的流转效率,可以更快地将内容分发到每个用户手中,直观地呈现在用户眼前,内容不再是沉入信息海洋的石块,而是高效流转的“宝藏”。分发效率的提升,让内容制作方可以得到更多的曝光,获得更多用户的关注。更多的曝光和更多的粉丝,当然可以通过变现产生不菲的商业收入。
# 4. 增加产品的商业化能力
实时推荐增加了内容的曝光机会,提升了标的物的流转效率,让单个推荐位的点击和转化大大提升。好的实时推荐能够抓住用户的眼球,让用户沉浸其中,提升了用户购买商品(如果是电商实时推荐)的概率。即使是今日头条这类提供非卖品标的物的产品,实时推荐中还可以整合信息流广告,让更多的广告得到曝光,从而增加广告的CPM,这也是一种价值变现的好方式。
正因为实时推荐的巨大价值,让当今的互联网产品开发者非常心动,期望在自己的产品中整合实时推荐功能。那么实时推荐可以用到哪些产品中呢?这就是下节要分享的主要内容。
# 三、实时推荐系统的应用场景
实时推荐系统根据用户的当下行为作出快速反馈,给用户提供所见即所得的推荐,这一般也要求用户的行为是可以在短期内完成的,即用户”消费“一个标的物不会花很长时间。推荐系统需要在短期内就知道用户是否对该标的物感兴趣,才能基于用户行为给用户实时反馈。
基于上面的分析,我认为**“内容”消费完所花时间较短,用户希望短时间获取信息的产品比较适合实时推荐,即提供“快消“类标的物的产品是比较适合做实时推荐的,而像长视频、小说阅读等APP是不太适合做实时推荐的。**拿电影来说,用户看完一个电影需要花费2个小时左右,很大概率用户没有时间再接着去看另一部喜欢的。如果该电影用户看了几分钟就退出来了,这顶多算负反馈,没有正反馈(用户看完了或者看了很长时间),我们也没法给用户实时推荐他喜欢的,这也是这类产品不太适合做实时推荐的原因。
前面已经提到长视频类、小说阅读类不适合做实时推荐。下面我们来列举一下适合做实时推荐的常用产品形态,给读者提供一个参考。适合做实时推荐的产品主要包括如下6大类别:
# 1. 新闻资讯类
用户阅读一条文本新闻时间一般不会很长,几分钟就够了,因此是满足做实时推荐条件的。如今日头条、腾讯新闻、网易新闻、趣头条、手机百度APP信息流等等都提供了实时推荐的能力。
# 2. 短视频类
短视频也是一类时长较短的产品,满足“快消”产品的特性,因此是实时推荐非常好的应用场景,目前主流的短视频应用,如快手、抖音、好看视频、哔哩哔哩等都提供了实时推荐形态。
# 3. 婚恋、陌生人社交类
对于婚恋、陌生人交友类软件,用户只要对陌生人的长相或者相关简介有个基本了解就可以决定要不要聊下去,决策时间不需要很长,因此是适合做实时推荐的。像世纪佳缘、陌陌、探探等都提供了实时推荐能力。
图4:陌陌、世纪佳缘、探探上下滑动或者通过左右滑动来选择感兴趣的人
# 4. 直播类
直播类虽然播放时长会很长(很多主播一次性可能直播几个小时),但用户只要进去看几分钟就可以知道是不是自己喜欢的类型了,因此直播类也是适合实时推荐的,像斗鱼、虎牙、映客等在首页就包含实时推荐模块。
# 5. 电商类
电商类APP,如手机淘宝、京东、拼多多,首页都提供了实时推荐的能力,用户只要下拉刷新,系统会自动刷新给你的推荐结果。一般用户决定是否要买一个商品也不需要投入很多的时间决策,看下图片和详情页简介就知道了。因此,电商类产品是适合做实时推荐的。 图6:淘宝、京东、拼多多首页通过下拉滑动为用户提供实时个性化推荐
# 6. 音乐、电台类
音乐类、电台类APP,用户消费一首歌也就几分钟,也是满足实时推荐场景的,下面这3个APP都提供了实时推荐的能力。
图7:喜马拉雅、酷狗音乐、豆瓣FM上的实时个性化推荐
我们在上面基本列举了市面上主流的提供了实时推荐能力的APP,这些APP都满足我们前面提到的可以做实时推荐的条件。当然这个条件不是绝对的,需要根据具体的应用场景和限制条件再综合分析。我们电视猫上在首页就提供了长视频的近实时推荐,电视猫的产品应用于家庭场景中,家中一般多人使用,用户平均使用时长比手机长得多,操作主要靠遥控器,操作相对手机端极为不便,并且用户可以一键(返回键)回到首页,这些条件导致首页暴露给用户是比较频繁的。因此,基于上面几个特点,我们在首页提供近实时反馈的兴趣推荐,只要用户看过某些视频时长达到一定值(我们认为用户喜欢)就更新兴趣推荐。
图8:电视猫首页近实时反馈的兴趣推荐模块
这里最后还要提一点,即使你的产品适合做实时推荐,实时推荐产品一定要放到首页这种用户触点多的位置,不然很难最大化发挥个性化推荐的价值。想象一下,你将实时个性化推荐产品安放到一个非常隐蔽的地方,用户很难找到,即使你推荐的再准有什么用呢?好的东西就是要让用户多使用,用户的反馈就是推荐模型的数据源,用户和产品互动的过程是一个正向的反馈环,交互越多,收集的数据就越多,基于这些数据训练出的推荐模型就越精准,通过用户与(实时推荐)产品的协同进化,推荐会越来越有商业价值。
# 四、实时推荐系统的整体架构
实时推荐系统需要基于用户的实时反馈行为来近实时更新用户的推荐结果,因此需要对推荐算法进行实时调整,实时数据处理与实时建模一定是实时推荐系统中最重要的一种技术。当前,推荐系统一般应用于提供toC服务的互联网产品中,这类产品用户基数大,数据量多,一般需要大数据平台来进行处理,对数据进行ETL、构建模型特征,我们这里讲解的实时推荐系统的整体架构是建立在大数据技术基础上的。
在大数据的发展史上先后出现了两种数据处理的架构,这两种架构刚好也是实时推荐系统算法构建的原型,下面我们分别对这两种架构进行介绍,并说明怎么基于这两种架构来构建实时推荐系统。
# 1. Lambda架构
当前的主流大数据平台一般将用户行为日志分为离线部分和实时部分(参见下图)。离线部分进入数仓供离线任务进行处理,包括各种按天统计的报表、T+1的推荐业务(非实时推荐,一般每天更新一次)。实时部分一般进入消息队列(如Kafka),供实时处理程序消费,如各类实时监控、大屏展示报表等。
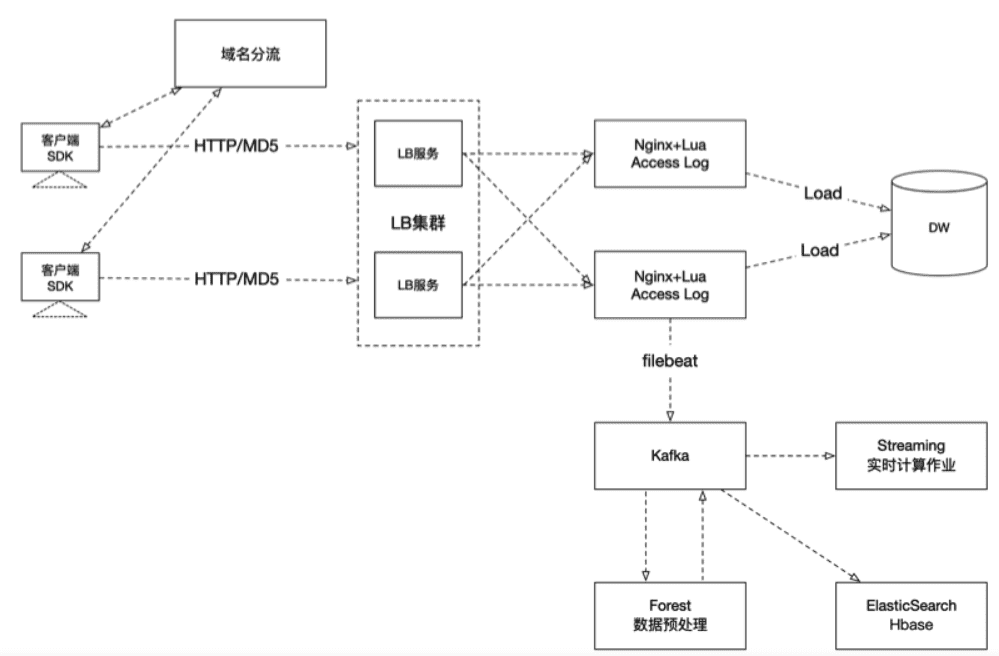
图:主流大数据平台将日志分别通过批和流两种逻辑进行分发,供不同业务处理
Lambda架构(见参考文献1)就是上面这种思路的高度抽象,它是著名的流式处理框架Storm的作者Nathan Marz最先提出来的。Lambda架构一般分为3个模块:Batch Layer、Speed Layer、Serving Layer,Batch Layer负责处理离线的大规模数据,Speed Layer负责处理实时收集到的用户行为数据,而Serving Layer将离线和实时两部分结果基于一定的规则或算法进行汇集、排序,并最终对用户(既可以是终端用户也可以是公司内部的其他业务部门)提供服务,下图即是Lambda架构的抽象业务处理逻辑。
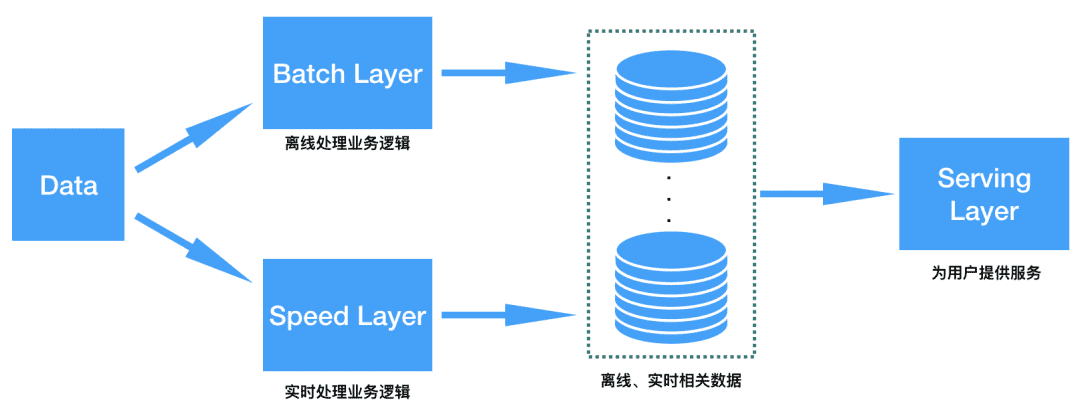
图:Lambda架构示意图
一般用户行为数据从底层的数据源开始,按照一定的数据规范和协议(比如采用Json格式)进入大数据平台,在大数据平台中经过Kafka、Logstash等数据组件进行收集,然后分成两条线进行计算。一条线是进入流式计算平台(例如 Storm、Flink或者Spark Streaming),计算一些实时指标或训练实时模型;另一条线进入批量数据处理离线计算平台(例如Map Reduce、Hive,Spark SQL等),计算T+1的相关业务指标或者训练离线模型,这些指标或者模型(结果)需要第二天才能算出。
Lambda架构历经多年发展,其优点是稳定,对于实时计算部分的计算成本可控,批量处理可以用晚上的时间来整体规划。将实时计算和离线计算高峰分开,可以极大化利用服务器资源,减少对用户的影响,这种架构支撑了数据行业的早期发展,但是它也有一些缺点,这些缺点导致Lambda架构不适应部分数据分析业务的需求,具体缺点如下:
实时与批量计算结果不一致引起的数据口径问题:因为批量和实时计算走的是两套计算框架,使用的是不同的计算程序,算出的结果往往不同,特别是对于那些累积的指标,时间长了容易产生误差。因此,需要一套完善的机制来保证计算的一致性,纠正数据偏差。
批量计算在计算窗口内存在无法算完的风险:在IOT时代,数据量级越来越大,经常发现夜间只有4、5个小时的时间窗口用于离线计算,已经无法完成白天20多个小时累计的数据计算。怎么保证早上上班前准时出数据报表已成为大数据团队头疼的问题。集群之间不同作业之间的依赖关系及资源占用等更加剧了这种情况的发生。
数据源变化都要重新开发,开发周期长:每次数据源的格式变化,业务的逻辑变化都需要针对ETL和Streaming做开发修改,整体开发周期很长,业务反应不够迅速。
服务器存储大:数据仓库的典型设计,会产生大量的中间结果表,造成数据急速膨胀,加大了服务器存储压力。
上面对Lambda架构进行了初略的介绍,那么下面我们来讲解怎么基于Lambda架构来构建实时个性化推荐系统,我们先给出架构图(见下面图11),这里包含离线算法模块(对应Lambda架构中的Batch Layer)、实时算法模块(对应Lambda架构中的Speed Layer)、融合模块(是Lambda架构中Serving Layer抽取出来的一部分,对于推荐算法来说,它比一般的数据处理更复杂,为了减轻Serving层的压力,将复杂的与业务逻辑相关的计算操作独立出来形成一个单独的模块),下面我们来逐一说明各个模块的作用。
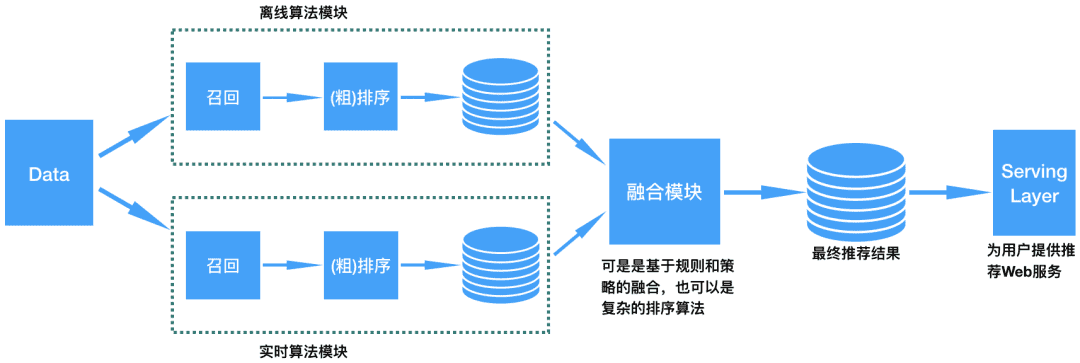
图:基于Lambda架构的实时个性化推荐算法架构
# 离线算法模块
离线算法模块基于用户长期行为数据训练召回模型和排序模型,最终生成离线推荐结果。离线部分由于使用的是历史数据,每天更新一次,模型可以较复杂,只要在一天之内计算完成即可,最终算出的是基于用户历史兴趣的推荐结果。
# 实时算法模块
实时算法模块基于用户最近的兴趣来获得给用户的推荐,比如可以基于用户最近一次操作的标的物,召回与该标的物最相似的标的物作为召回结果,后面可以基于用户整体兴趣对召回的标的物进行排序,获得用户的近实时推荐结果。
# 融合模块
融合模块基于给用户的离线推荐结果和实时推荐结果,通过利用合适的业务规则、策略以及复杂的排序算法对推荐结果进行排序,获得给用户的最终推荐。
混合模块的具体实现方式可以多种多样,上面提到的是其中的一种,还可以基于生成的离线推荐结果,实时推荐基于近期兴趣读取并更新离线推荐结果获得最终的推荐。在电视猫中部分实时推荐就是采用的该方式:离线推荐结果插入CouchBase推荐库,实时推荐程序获得用户最后播放记录的相似视频,然后从CouchBase中读取该用户的推荐结果,将刚刚计算好的相似视频(基于一定规则)替换掉取出的推荐结果的部分视频,再插入CouchBase,从而修改了推荐结果,获得实时推荐的效果。
对于业务规则比较简单的情况,可以将融合模块放到Web Server中(见下面图12),整体架构跟上面介绍的类似,只不过这里事先计算出离线推荐和实时推荐结果,最终在Web Server中对两类推荐结果进行聚合,而上面介绍的是将集合过程独立出来成为一个子模块。
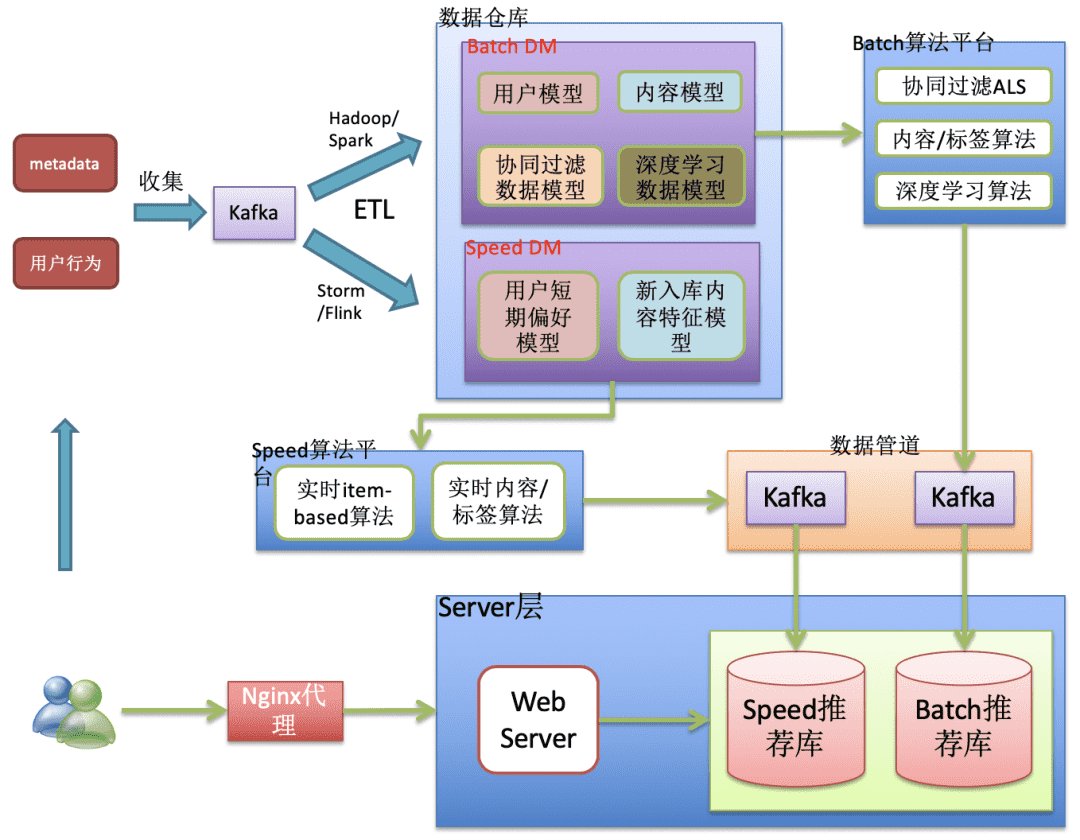
图:在web server中进行融合的实时推荐业务架构图
上述方法还可以进行适当的改进,就是首选利用历史数据训练好召回和排序模型,按照上面架构部署,等推荐业务跑起来后,直接就接入实时数据流,不需要再处理历史数据了(因为模型已经基于历史数据进行了训练),在实时流运行的过程中可以逐步迭代优化召回和排序模型。这里需要对模型进行实时学习更新,我们将这种学习过程称为增量学习。增量学习利用了最新的用户行为数据,一般可以稳定提升模型性能。在生产实践中,增量学习根据增量的时效性有三种不同粒度,其中T+1增量模式是,load已有模型的checkpoint,采用批训练模式,模型全量部署上线,更新时效性为天级别,小时级增量模式是,使用实时样本进行流式训练,但部署过程依旧采用全量模型切换,更新时效性为小时级。第三种(也是最完美的)增量学习解决方案是流式训练模型、实时用于模型预测,这种方案就不用离线模块了,这就是我们下面要讲到的Kappa架构了。
Lambda架构采用分而治之的思路通过将用户行为分为离线部分和实时部分,分别进行处理和建模,最终再汇聚两部分的信息获得最终的结果。对于当前的实时推荐,Lambda架构是一种可行有效的实施方案。结合前面介绍的Lambda架构的缺点及作者自己实施实时推荐的经验,对于实时推荐系统,Lambda架构最大的问题主要有如下三点:
- 实时处理和离线处理是不同的技术,实现离线推荐和实时推荐的模块需要采用不同的代码来实现,开发和维护成本明显偏高。
- 在衔接实时推荐和离线推荐时,会存在信息的冗余或者缺失。离线推荐处理的数据到今天零点,而最理想的状态是实时从零点开始对当前所有的用户信息进行处理和建模,而在具体实施时,有各种问题、限制导致数据的衔接存在断档或者重复使用的情况。
- 在最终给用户推荐时,需要融合实时推荐结果和离线推荐结果,进一步增加了流程和复杂度。
鉴于上述问题,我们可以采用一套统一的处理架构,这就是下面我们要介绍的Kappa架构。
# 2. Kappa架构
Kappa 架构是LinkedIn的Jay Kreps结合实际经验和个人体会,针对Lambda架构进行深度剖析,分析其优缺点并采用的替代方案(读者可以查看参考文献2,对Kappa架构进行更深入了解)。Lambda 架构的一个很明显的问题是需要维护两套分别跑在批处理和实时计算系统上面的代码,而且这两套代码需要紧密配合,对增量求和统计还得产出一样的结果。因此对于设计这类系统的人来讲,要面对的问题是:为什么我们不能改进流计算系统让它能处理这些问题?为什么不能让流系统来解决数据全量处理的问题?流计算天然的分布式特性注定其扩展性比较好,能否加大并发量来处理海量的历史数据?基于种种问题的考虑,Jay提出了Kappa这种替代方案。
Kappa架构通过剔除Lambda架构中的批处理部分简化了Lambda架构。为了取代批量处理,数据只需通过流式计算系统快速加工处理。Kappa体系结构中的规范数据存储不是使用类似于SQL的关系数据库或类似于Cassandra的键值存储,而是一个只能追加数据的不可变日志系统。从日志中,数据通过计算系统流式传输,并输入辅助存储器作为字典库供服务使用。典型的Kappa架构如下图:

图:Kappa架构
Kappa架构的核心思想,包括以下三点:
- 用Kafka或者类似MQ队列系统收集各种各样的数据,你需要几天的数据量就保存几天到消息队列中。
- 当需要全量重新计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个新的结果存储中。
- 如果需要对业务流程和计算逻辑调整,重启一个新的计算实例,当新的实例做完后,停止老的流计算实例,并把老的一些结果删除。
Kappa架构的优点在于将实时和离线代码统一起来,方便维护而且统一了数据口径的问题。而Kappa的缺点也很明显:
- 流式处理对于历史数据的高吞吐量力不从心:所有的数据都通过流式计算,即便通过加大并发实例数亦很难适应IOT时代对数据查询响应的即时性要求。
- 开发周期长:在Kappa架构下由于采集的数据格式的不统一,在对数据进行调整或兼容时每次都需要开发不同的Streaming程序,导致开发周期长。
- 服务器成本浪费:Kappa架构的核心实现需要依赖外部高性能存储Redis、HBase等服务作为中间存储器。但是这2种系统组件,又并非专门设计来满足全量数据存储的,会占用较多的内存及CPU资源,对服务器成本有较大浪费。
上面我们对Kappa架构进行了简单介绍,那么基于Kappa架构怎么构建推荐系统呢?其实这个问题是比较简单的,Kappa架构简化了Lambda架构,只保留了实时处理部分,针对推荐系统也是一样的。Kappa架构构建推荐系统只做实时推荐部分,具体架构图见下面图14。
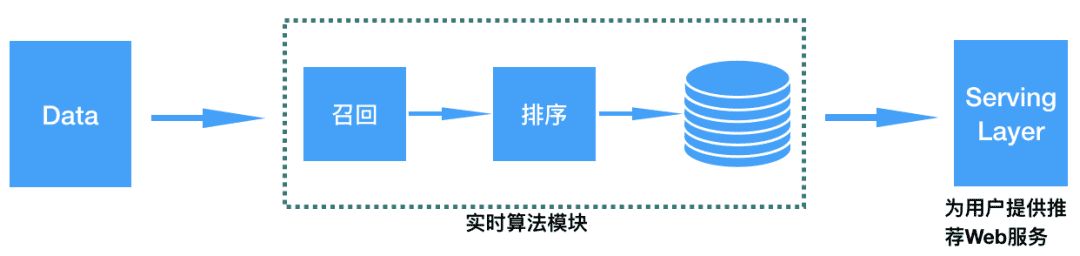
图:基于Kappa架构的实时个性化推荐算法架构
按照上面架构部署好推荐业务,算法在刚刚启动时,先将所有离线数据一次性按照实时流的方式灌入,逐步在线学习召回和排序模型,等历史数据处理好了,就直接处理流式数据了,最终变成了流式处理。这里需要强调的一点是,召回和排序模型是一个逐步学习和训练的过程,这对模型是有一定要求的,有些模型是不适合这样训练的。我们在电视猫的业务中对短视频的实时相似推荐就采用了这种模式,由于我们计算相似度是基于标签来计算的,就是简单的向量相似度计算,模型不复杂是可以采用上面的方法的。读者可以参考《基于Erlang语言的视频相似推荐系统 (opens new window)》和《基于标签的实时短视频推荐系统 (opens new window)》这两篇文章中的思路。
另外一种方式是模型训练好,直接部署上去,根据用户最近的行为实时构建最新的特征向量,将新特征向量灌入模型,获得新的推荐。为了利用最新的数据,模型还可以隔一段时间重新训练一次。TensorFlow Serving就是采用的该模式,并且模型可以热更新,这类模型一般也是比较复杂的模型,如深度学习模型等。这里不是从零开始学习模型,而是预训练让模型有一个很高的起点,再从起点开始学习。训练模型的过程中也用到了离线技术,因此模糊了跟Lambda架构的关系。
目前强化学习(强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏)在大的互联网公司已经部分用在推荐业务中(见参考文献10),强化学习这种跟环境进行实时交互的学习范式本质上就是Kappa架构。
上面我们讲到的实时推荐的Lambda架构和Kappa架构都是采用了事先将推荐结果计算出来的方式,这属于事先计算型,实际上也是可以采用实时装配型的,对这两种推荐系统提供web服务的方式,读者可以参考《推荐系统提供web服务的2种方式 (opens new window)》这篇文章进行详细了解,这里不赘述。
上面我们对当前主流的两种实时推荐架构进行了说明,并没有讲相关的具体工程技术,我们在下一节对相关技术进行介绍。
# 五、实时推荐系统的技术选型
实时推荐系统与实时大数据处理密不可分,因此构建实时推荐系统的技术一定是离不开实时大数据技术的,目前比较主流的实时大数据处理框架主要有Spark Streaming, Flink 、Storm等,这些框架都可以用于做实时推荐。基于实时推荐的两种实现架构Lambda和Kappa,这里会涉及到离线处理和实时处理(Lambda有离线处理模块而Kappa没有,不过Kappa中涉及到的模型也会进行离线训练),下面我们分别从离线处理和实时处理的技术选型来分别介绍。
# 1. 离线部分算法的技术选型
离线部分可以选择的工业级技术有Spark、MapReduce、TensorFlow等。MapReduce由于对迭代运算不是很友好,不太适合复杂的机器学习模型,建议还是采用Spark和TensorFlow。
Spark中包含很多数据ETL算子和算法库,很多算法可以直接使用,Spark MLlib中直接有ALS矩阵分解推荐算法,其他推荐算法也可以基于Spark的API自行开发。针对复杂的深度学习算法目前是不太适合在Spark上运行的,Spark的新版本3.0应该会增加对深度学习更好的支持。
TensorFlow可以实现非常多的复杂算法,在工业界也非常流行。不过TensorFlow的分布式计算没有Spark这么友好。一般企业是基于Hadoop/Spark来构建大数据平台的,如果利用TensorFlow来实现部分算法的话,是需要打通大数据与TensorFlow两套体系的。
基于上面的分析,作者建议如果在人力不足或者不是非用TensorFlow不可的情况下,还是采用Spark平台更合适,大数据和推荐两套业务共用了一套架构体系,技术栈更加统一简单。
# 2. 实时部分算法的技术选型
实时部分可以采用的技术非常多,常见的有Storm、Flink、Spark Streaming等。目前Storm没有以前那么流行了,建议还是采用Flink和Spark Streaming这两套中的一种。如果你们团队已经在使用Spark了,开始做实时处理或者实时推荐业务,那最好还是用Spark Streaming,毕竟都是Spark一套体系,API规范都保持一致,技术栈也更统一。Spark Streaming虽然实时性方面不如Flink,但是对于实时推荐来说,做到秒级实时就足够了。
作者公司最早是基于Hadoop/Spark体系来构建大数据的,顺其自然地推荐系统也是基于Spark来构建的,最近几年开始做实时推荐,也是采用Spark Streaming框架,目前看下来,整套框架都可以很好地处理离线推荐、实时推荐等各类推荐场景。
这些框架目前在云计算公司都有现成的PAAS或者SAAS服务可供选择,对于初创团队或者刚开始启动推荐业务的团队,建议可以采买相关云服务,这样整个系统更加轻量,维护成本低,团队应该将核心放到业务和算法上。
# 六、实时推荐算法与工程实现介绍
在第四第五节我们介绍了实时推荐系统的架构和技术选型,有了这些基础准备我们就能够非常方便地开发实时推荐算法了。推荐算法是推荐系统中最核心的组件之一,在本节我们就来讲讲有哪些可以用于实时推荐的算法。这里我们讲的实时推荐算法是指可以利用流数据来训练,可以进行在线学习的推荐算法,而不关注Lambda架构中离线部分的推荐算法。
我们在前面的推荐算法系列文章中部分讲解了实时推荐算法的工程实现,这里将相关资源列举出来,读者可以进行有针对性地学习和了解。
# 1. 实时协同过滤算法
《协同过滤推荐算法 (opens new window)》第四节“近实时协同过滤算法的工程实现”对实时协同过滤算法进行了详细讲解,这里采用的是利用Spark Streaming和HBase作为算法实现和存储的工具。
# 2. 实时矩阵分解算法
《矩阵分解推荐算法 (opens new window)》第五节“近实时矩阵分解算法”对腾讯在2016年发表的一篇基于Storm来实现的近实时矩阵分解的算法原理及工程实现细节进行了介绍。
# 3. 实时因子分解机
《因子分解机 (opens new window)》第六节“近实时分解机”有对分解机实时实现的简单介绍,其中给了很多参考文献,可以作为读者学习的参考资料。
# 4. 基于内容推荐的实时算法
基于内容的推荐,不需要其他用户的行为,只需学习到待推荐用户的兴趣偏好特征就可以给用户进行推荐了,相比协同过滤类算法更简单更容易实现,因此也是非常适合做实时推荐的。作者在《基于Erlang语言的视频相似推荐系统 (opens new window)》和《基于标签的实时短视频推荐系统 (opens new window)》这两篇文章中基于电视猫的视频推荐场景分别对标的物关联标的物推荐、完全个性化推荐这两种推荐范式的实时实现进行了详细介绍,读者可以参考学习具体的实习思路,这两篇文章都是基于内容的推荐算法的实时化。
业界比较出名的在线学习算FTRL(Google最早提出,见参考文献6),可以实时训练很多机器学习算法(如logistic回归),可以与推荐系统的排序阶段。当前比较热门的深度学习技术也可以进行在线学习,读者可以阅读参考文献4、5进行了解。在工业界,蚂蚁金服的AI团队对TensorFlow的底层架构进行了修改优化(见参考文献9),使之适应实时学习,并在支付宝的推荐业务中得到了很好的应用。
参考文献7、8分别介绍了凤凰新闻和爱奇艺的实时推荐的工程实现细节,读者可以参考。另外参考文献3比较详细介绍了Netflix的推荐系统的工程实现介绍,其中也包括实时实现部分,采用的是Lambda架构的模式。Netflix推荐系统是业界做得非常好的典范,值得读者深入了解。从这篇参考文献也可以看到要做好实时推荐系统是非常复杂的,需要面临非常多的技术、工程挑战,在下一节我们就会对这方面进行详细介绍。
# 七、构建实时推荐系统面临的困难和挑战
实时推荐系统需要实时处理用户行为,并基于用户行为给用户提供近实时的推荐,时间上的及时响应,对整个推荐系统的架构、算法都提出了极高的要求。设计实时推荐系统面临的挑战主要体现在如下几个方面:
# 1. 算法架构
实时推荐系统需要实时收集用户行为,对用户行为进行实时ETL处理,实时挖掘用户兴趣变化,实时训练模型,实时更新推荐结果。对数据分析处理、数据存储、接口访问等需要提供基础能力支撑。整个推荐过程是一个相当长的链路,每一个环节都不能出错,对数据处理和分析响应的及时性要求极高。
# 2. 算法模型
对于在线学习类的推荐算法模型,构建实时推荐系统还需要模型层面的支持,不管是召回还是排序,都需要能够兼容实时数据,能够实时训练。传统的算法是不满足条件的,比如Logistic回归就不适合用于实时训练,它通过改进后的FTRL是可以进行实时训练的。
# 3. 产品交互
实时推荐的结果需要以用户易于理解和操作的方式展现给用户,因此需要设计一个良好的产品交互界面,让用户易于理解,易于操作,更好地感受到个性化推荐带来的价值。像今日头条首创的下拉的交互产品形态就是比较好的一种实时交互形态,用户完全掌握主动权,不喜欢就滑一滑获得新的一批推荐。
总之,实时推荐系统是一个复杂的体系工程,我们需要在算法架构、算法模型、产品交互等多个方面做得出色才能打造出一个用户体验好、有商业价值的实时推荐系统。
# 八、实时推荐系统的未来发展
前面对实时推荐相关的产品、架构、算法等进行了深入的介绍,我们知道了实时推荐的价值和面临的挑战。很多公司的推荐产品也进行了实时化改造,充分享受到了实时推荐给产品带来的红利。实时推荐是随着移动互联网的起步和发展逐步发展成熟起来的,历史不超过10年,未来实时推荐还有很大的发展空间。在本节作者基于自己的理解来对实时推荐的未来发展进行一些预判和思考,希望给读者提供一些参考和借鉴。
# 1. 实时推荐是未来推荐发展的方向
实时推荐可以跟用户进行更加及时、高效地互动,有利于用户更好地使用产品,用户体验也更加真实自然,因此相比传统的T+1推荐系统更具商业价值。未来越来越多的企业会意识到实时推荐的价值,实时推荐一定是未来推荐系统发展的重点方向之一。
随着网络基础设施在世界更广泛的范围覆盖,越来越多的人会享受到信息技术带来的红利,实时推荐系统也会覆盖到更多的人群。5G技术的发展,让人们获取信息更加方便及时,复杂的多媒体信息也可以在瞬间完成下载和上传,云计算、AI技术的发展可以让更多的复杂高效算法应用于实时推荐,这些基础技术条件的成熟驱动着实时推荐朝着更流行、更普及、更精准的方向发展。
另外,社会的发展也让人类趋向于越来越个性化,人们期望更好地表达自我、满足自我,实时推荐可以让用户获得主动权和控制权,获得更加及时的反馈。信息的生产也将更加实时、多样、庞杂,这些信息的分发和消费问题都可以利用实时推荐来很好地解决。
# 2. 每个人有望拥有为自己服务的个性化算法
目前所有的实时推荐算法都是在云端部署,终端通过跟云端交互获得个性化推荐,这种方式会受到网络等多种外界因素的影响,对于及时跟用户交互是有一定副作用的。随着芯片技术和AI技术的进步,目前边缘计算是非常火的一个领域,边缘计算是在终端上直接完成计算,尽量不与或者少与云端交互,这极大地提升了处理的效率,受到网络等其他因素的影响也会更少,像无人驾驶这类技术的成熟是非常依赖边缘计算技术的进步的。
对于实时推荐系统,在云端实时处理庞大海量的用户信息为用户进行推荐已经非常费力,在终端完成这个事情是一种比较有创意的想法。具体的做法可以是先在云端基于全量数据离线训练一个复杂的模型,并将该模型同步到终端,终端基于该模型和用户的实时交互信息,实时优化该模型,让该模型跟着用户的行为一起进化,最终越来越适配用户的兴趣特征。
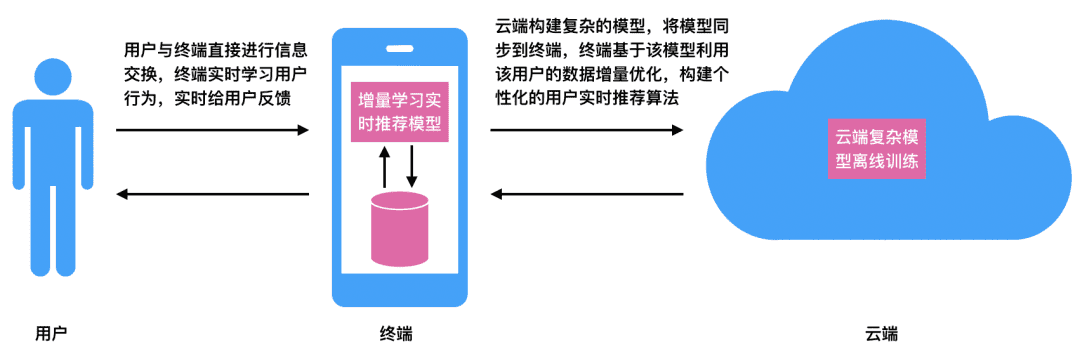
图:在终端上增量学习模型,为用户提供更加个性化的实时推荐
上面这种部署实时推荐算法的方式,更容易做到实时化,不受网络因素的影响,同时模型也是为用户量身打造的,更满足用户口味。当然,这对终端性能、存储能力、模型实时训练等提出了很高的要求。但不可否认,这一定是一个值得尝试的,有巨大应用价值的方向。TensorFlow Lite已经朝着这个方向迈进了一大步,TensorFlow Lite 允许用户在多种设备上运行 TensorFlow 模型。在数据库方面,CouchBase也提供了CochBase Mobile解决方案,让移动端的数据存储跟云端可以做到实时联动。
基于上面的介绍,我是非常看好实时推荐在终端上的部署的,虽然目前在业界没有成熟的终端推荐解决方案,但我相信那些有前瞻性思维的公司一定是在朝着这个方向尝试的。
# 3. 实时推荐应用场景的多样性
目前实时推荐系统主要应用于移动端,随着物联网和智能家居的发展,更多的智能终端产品如雨后春笋般出现,实时推荐系统一定会落地到更多的产品、应用到更多的场景中。
我们公司的产品电视猫应该是业界比较早将实时推荐系统应用于家庭大屏中的,目前在短视频、首页长视频推荐都做到了实时化,并产生了巨大的业务价值。智能电视上的实时推荐应用目前只是起步阶段,当华为、OPPO等大厂入局家庭大屏,一定会带来更多的新应用,这时实时推荐就会蓬勃发展起来。
在智能音箱、车载系统上,由于交互方式的变化(这些系统一般用语音进行交互),对产品形态有极大影响,目前作者还没有看到在这些硬件上有相关的智能推荐形态出现。由于交互方式的限制以及可能没有屏幕,这些硬件上如果有推荐形态,那也一定会采用实时推荐的模式。
# 4. 实时交互方式趋于多元化
目前移动屏上的实时推荐产品,用户都是通过滑动触摸的方式跟推荐系统交互的,这种交互方式是非常自然方便的,正因为方便的交互才让实时推荐有如此大的爆发力。
在智能电视上的交互目前主要靠遥控器,作者在电视猫上部署的实时兴趣推荐(参见第三节的图8),由于是长视频推荐及遥控器交互的限制,目前没有直接的用户交互,当用户看一个节目再返回到兴趣推荐模块时,系统会自动更新推荐结果。而我们部署的短视频信息流推荐采用的是无限右滑的交互方式(见下面图16)。

图:视猫音乐信息流推荐采用遥控器无限右滑的方式与用户进行交互
前面提到的在智能音箱和车载软件上,用户的交互方式是语音交互,利用语音交互怎么进行个性化推荐,目前没有相关的产品形态出现,这值得大家来思考和探索。
当然,随着VR/AR/MR等虚拟现实、增强现实技术的成熟和产品形态的完善,在这些智能设备上的实时推荐可以采用更多的交互方式,比如语音、手势、甚至表情、眼动、思维意识控制等。这些是更加遥远和值得期待的事情了。
# 总结
作者在这篇文章中对实时个性化推荐系统进行了全面的介绍。我们了解了实时推荐系统产生的背景,在社会发展、技术进步、交互便捷、信息爆炸、时间碎片化、激烈的市场竞争等多种因素的驱使下,实时推荐系统的出现是必然的现象。
实时推荐系统相比传统的T+1推荐,可以更好地满足用户的诉求,让用户掌握更多的控制权,可以极大地提升用户体验,让用户沉浸其中,这也带来了极大的商业价值,因此实时推荐系统在各种移动产品中遍地开花,成为主流的推荐产品形态。
实时推荐系统由于要对信息进行实时处理,对技术架构、工程体系、算法实现等多个方面提出了更高的要求,需要算法工程师采用创新的方式来实现,本文也对相关的架构和算法进行了比较全面的归纳和讲解。
基于实时推荐系统的用户价值和商业价值,在5G技术、物联网、AI等多种技术的发展和驱动下,实时个性化推荐一定是未来推荐系统发展的核心方向,未来的产品有望在终端上为每个人部署个性化的、量身定制的实时个性化推荐。实时推荐系统也必将在应用场景、交互方式上进行发展和突破。
本文从比较全面的视觉给读者提供了全新的思考维度来认识和了解实时推荐系统。鉴于实时推荐系统的重要性,每个从事推荐算法的工程师、产品经理(特别是数据和AI产品经理)、甚至是运营人员都需要对实时推荐有一定的了解,而本文是你了解实时推荐系统的一扇窗。
# 参考文献
- [书] Big Data: Principles and best practices of scalable realtime data systems
- [Kappa架构介绍] http://milinda.pathirage.org/kappa-architecture.com/
- [System Architectures for Personalization and Recommendation] https://netflixtechblog.com/system-architectures-for-personalization-and-recommendation-e081aa94b5d8
- [2018] Online Deep Learning: Learning Deep Neural Networks on the Fly
- [2019] Addressing delayed feedback for continuous training with neural networks in CTR prediction
- [2011] Follow-the-regularized-leader and mirror descent: Equivalence theorems and l1 regularization
- [信息流推荐在凤凰新闻的业务实践] https://mp.weixin.qq.com/s/aCTP4OCGyWxWGrlCFHSYJQ (opens new window)
- [在线学习在爱奇艺信息流推荐业务中的探索与实践] https://mp.weixin.qq.com/s/aQOcnWV2L_VY3ChrSXXxWA (opens new window)
- [蚂蚁金服核心技术:百亿特征实时推荐算法揭秘] https://mp.weixin.qq.com/s/6h9MeBs89hTtWsYSZ4pZ5g (opens new window)
- [2018 Youtube] Top-K Off-Policy Correction for a REINFORCE Recommender System
# 参考文章
- https://blog.csdn.net/qq_43045873/article/details/105236451










