大数据-技术体系构成
更新时间
浏览
TIP
本文主要是介绍 大数据-技术体系构成 。
# 大数据技术体系
# 1、概述
# 企业级大数据体系

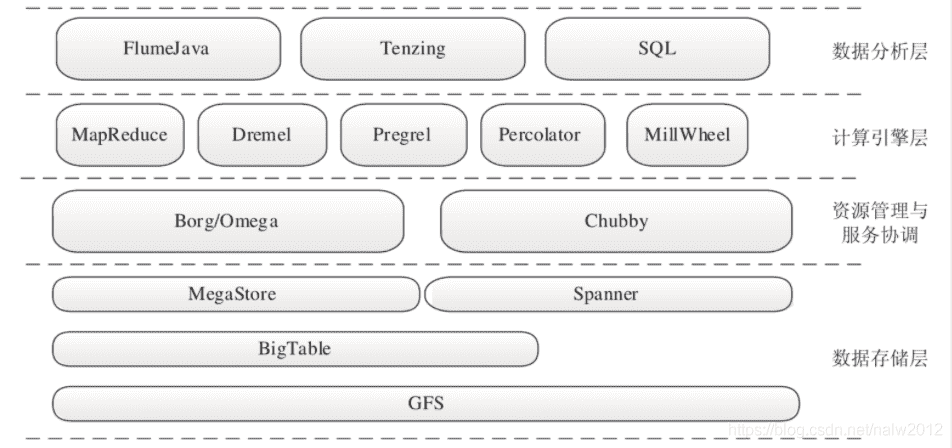
# Google大数据技术栈
# Hadoop与Spark开源大数据技术栈

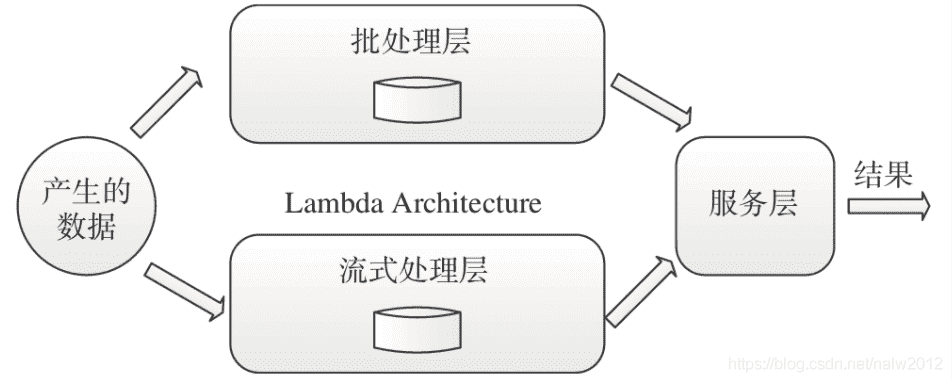
# 大数据架构
# 2、关系型数据库采集
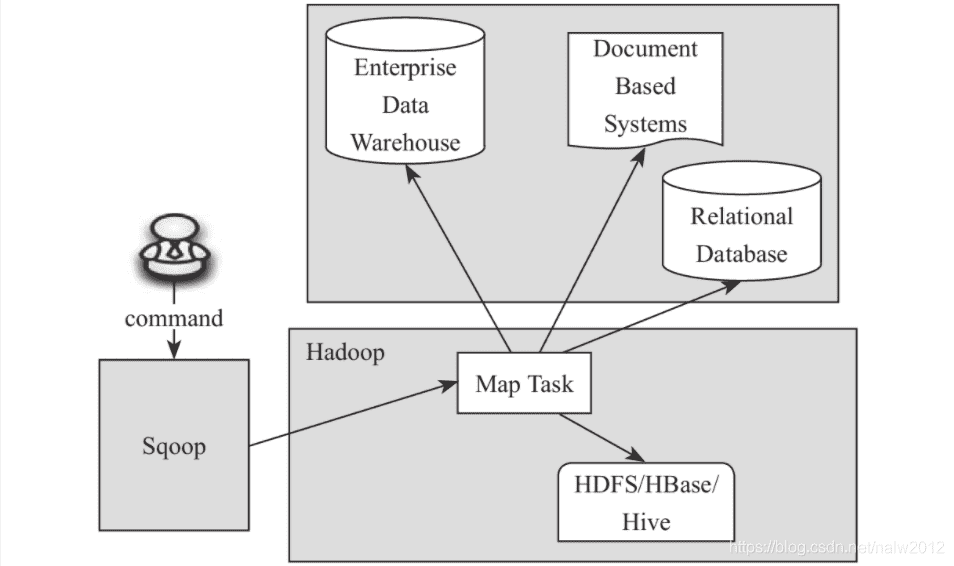
# Sqoop1架构
# Sqoop2架构

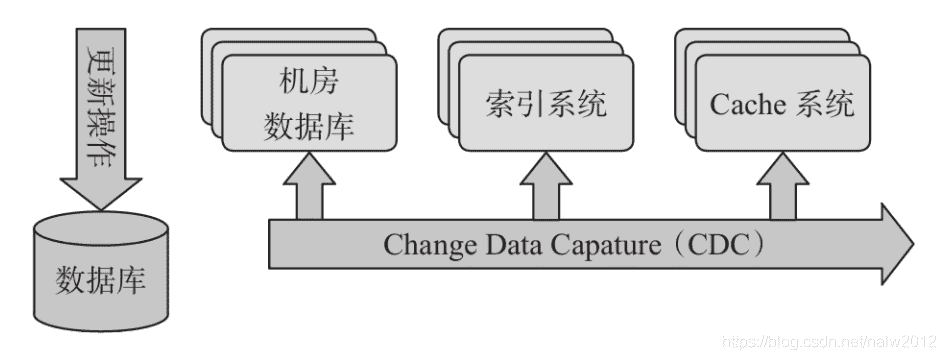
# CDC(增量数据收集)
# 应用场景
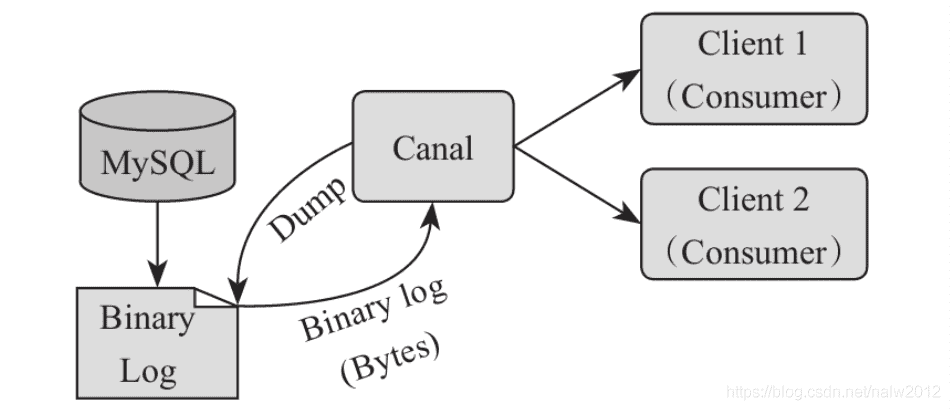
# 开源实现Canal
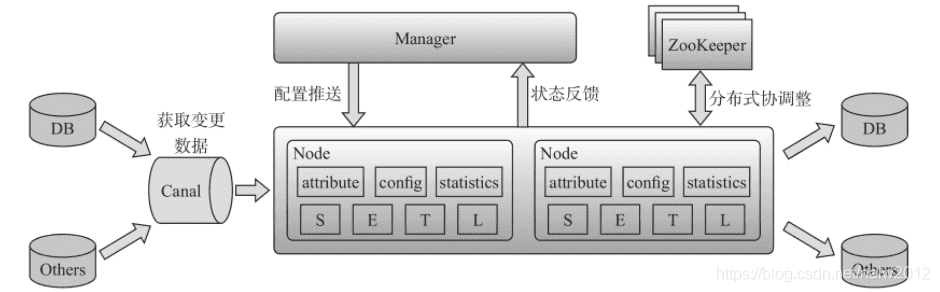
# 多机房同步系统Otter
- 基本原理
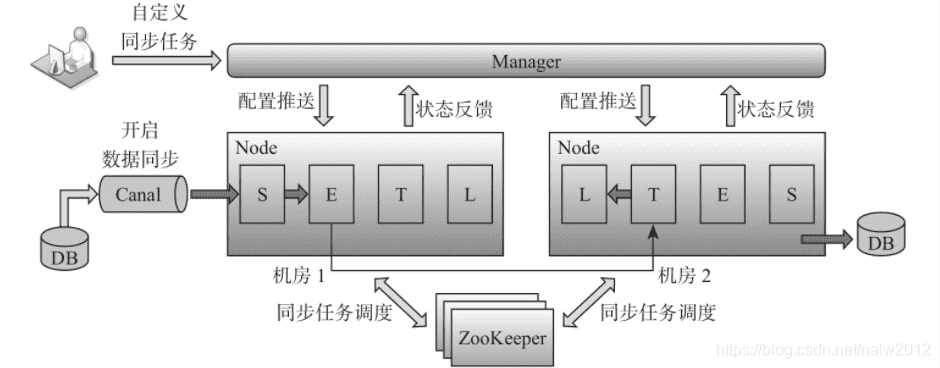
- S、E、T、L四阶段模型

- 跨机房部署
# 3、非关系型数据库采集
- 非关系型数据指日志、网页、视频等数据。
# Flume
# 基本思想和特点
- 插拔式架构,已扩展
- 各组件可定制化
- 声明式配置
- 语意路由
- 内置事务,高可靠性
# 基本架构
Flume的数据流通过一系列Agent的组件构成,经过过滤、路由操作后,传递给下一个或多个Agent,直至目标系统。
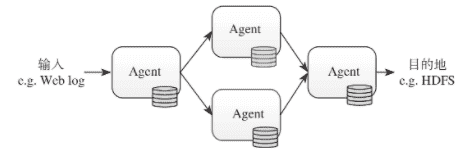
# Agent构造
Agent内部由三个组件构成,分别是Source、Channel、Sink。
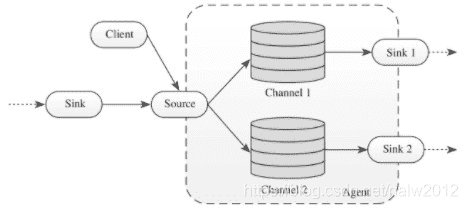
- Source 从Client或上一个Agent接收数据,写入Channel。 Flume提供了很多Source实现,包括
- Avro Source
- Thrift Source
- Exec Source
- Spooling Directory Source
- Kafka Source
- Syslog Source
- Http Source
- 自定义Source
2)Channel 缓冲区,暂存Source写入的数据,直到被Sink发送出去。 Flume提供了几种实现:
- Memory Channel 内存中缓存,性能高,断电数据易丢失,内存不足,Agent会崩溃。
- File Channel 磁盘文件缓存Event。
- JDBC Channel
- Kafka Channel
3) Sink 从Channel读取数据,发送给下一个Agent。 Flume提供以下几张实现:
- HDFS Sink
- HBase Sink
- Avro/Thrift Sink
- MorphineSolrSink/ElasticSearch Sink
- Kafka Sink
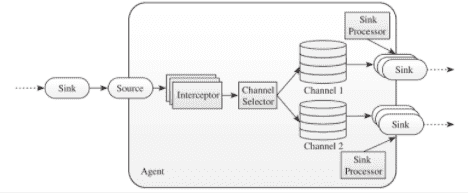
# Flume高阶组件
包括Interceptor、Channel Selector和Sink Processor
# 数据流构建方法
# 如何构建
1) 确定流式数据获取方式 2) 根据需求规划Agent 3) 设置每个Agent 4) 测试构建的数据流拓扑 5) 在生产环境部署该数据流拓扑
# 数据流获取方式
- RPC
- TCP或UDP
- 执行命令
# 常见拓扑架构
1) 多路合并
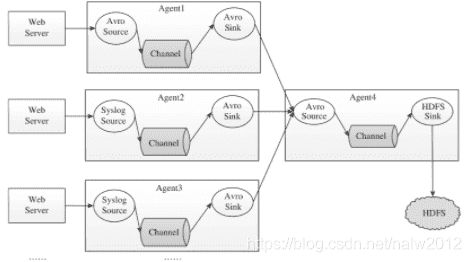
2) 多路复用

# 参考文章
- https://blog.csdn.net/nalw2012/article/details/108188819
← 大数据-技术框架方案 大数据-技术架构总结 →










